python视频教程栏目介绍DeepFakes。
目标
之前没碰过DeepFakes,突然想发B站视频玩儿一下。试了试还挺麻烦的,这里记录一下自己踩的坑。
本文的目标就是将The Singing Trump的视频换成我们的川建国同志。
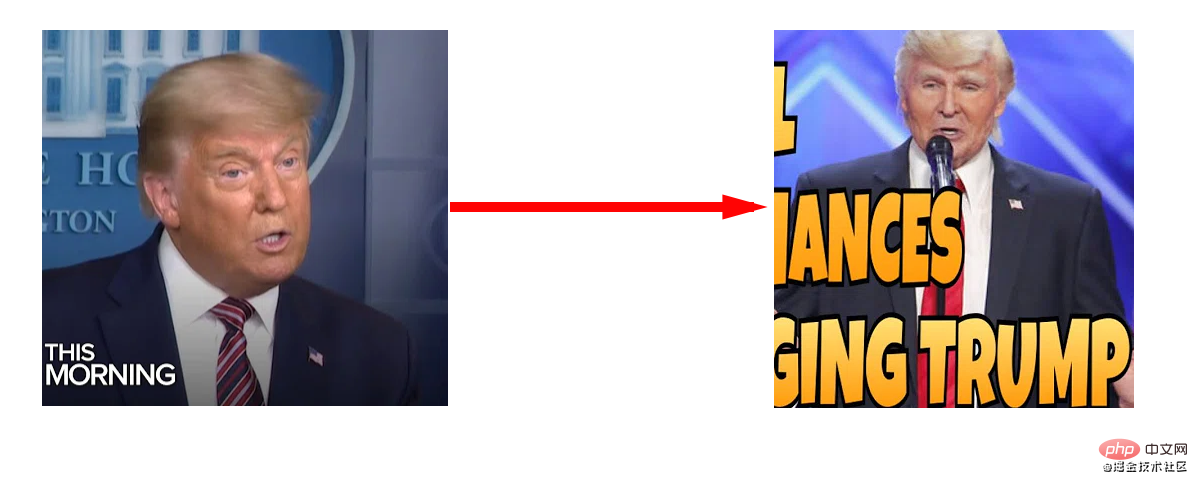
最后效果:
视频链接:https://www.bilibili.com/video/BV12p4y1k7E8/
环境说明
本文尝试的环境为linux服务器的环境,因为跑得比较快吧。
Python环境:Anoconda python3.7版本
GPU:K80, 12G显存
DeepFake版本:2.0
其他工具:ffmpeg
素材准备
首先需要准备一个或者多个The Singing Trump的视频,以及川建国同志的视频。用作换脸素材。
视频切分
首先通过ffmpeg将视频素材切分成多个图片。
mkdir output ffmpeg -i 你的视频.mp4 -r 2 output/video-frame-t-%d.png复制代码
这里视频不一定要mp4,其他格式也行,然后 -r 2表示是2帧,也就是每秒钟采集两张图片,各位可以按照自己的视频尝试。 最后是输出到output文件夹里面,前缀随便定义就好了,名字也不是关键。
这里最好多找几个视频,因为deepfake会提示要保证人脸个数大于200张才会比较好,我这里分别准备了3个视频,一共6个视频。
ffmpeg -i sing_trump1.mp4 -r 2 sing_trump_output/st1-%d.png ffmpeg -i sing_trump2.flv -r 2 sing_trump_output/st2-%d.png ffmpeg -i sing_trump3.mp4 -r 2 sing_trump_output/st3-%d.png复制代码
ffmpeg -i trump1.webm -r 2 trump_output/t1-%d.png ffmpeg -i trump2.mp4 -r 2 trump_output/t2-%d.png ffmpeg -i trump3.mp4 -r 2 trump_output/t3-%d.png复制代码
弄完了还挺大,乱七八糟加起来3.7个G。
clone代码+装依赖
这里没啥可说的,从github上下代码。
git clone https://github.com/deepfakes/faceswap.git复制代码
然后根据自己的实际情况装环境,我这里是现在PC上装cpu这个,然后在服务器上装nvidia。

抽取脸部
接下来将所有的脸部抽出来。
python3 faceswap.py extract -i trump_output -o trump_output_face python3 faceswap.py extract -i sing_trump_output -o sing_trump_output_face复制代码
这里抽完了脸就是这样了。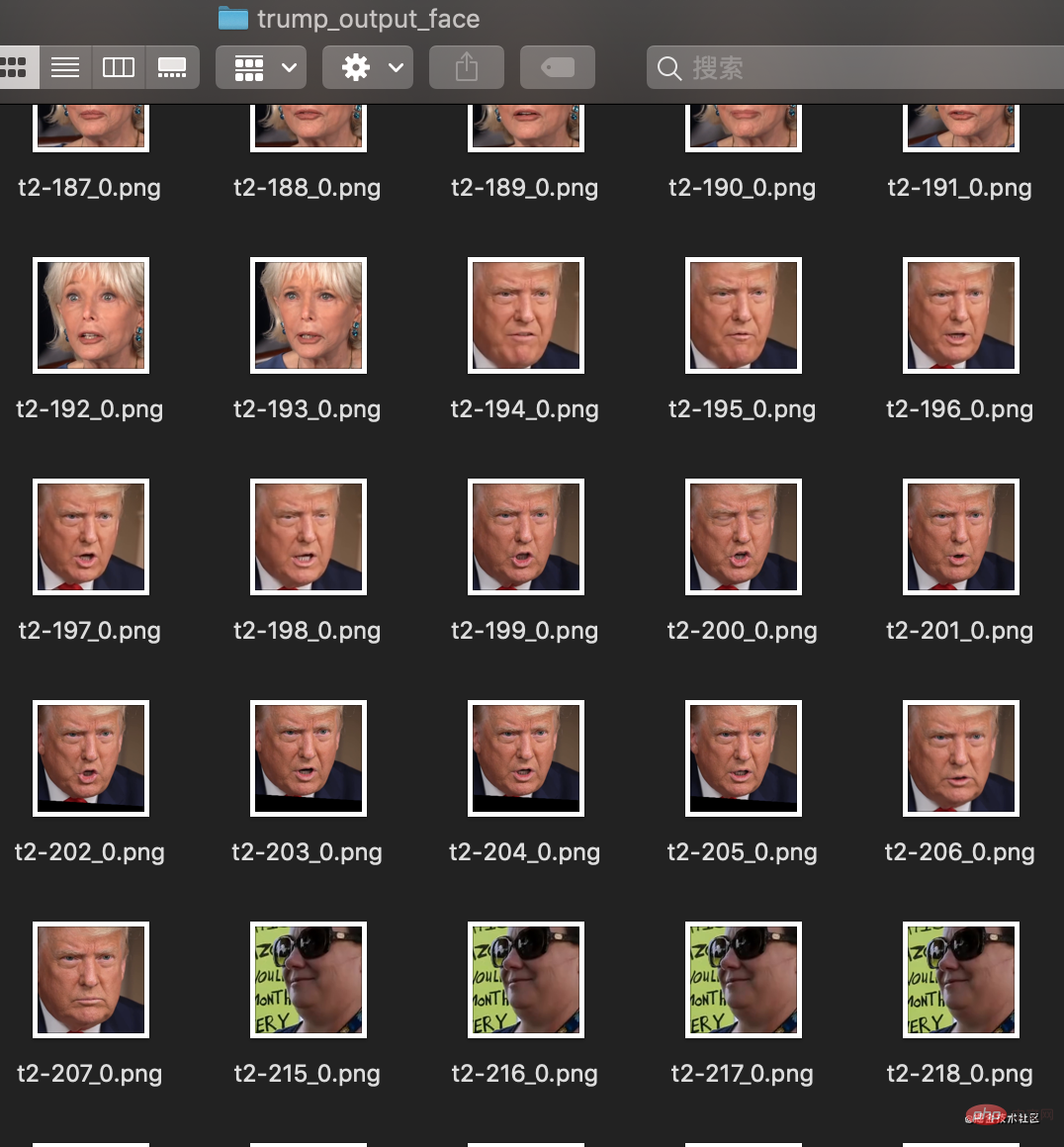
筛选脸部
接下来需要手工把我们不需要的脸都删掉。

修改alignment
在我们调用extract生成脸部时,会自动生成一个校对文件,用于在原图上保存脸部的信息。 删除脸部之后,需要将脸部和原图片进行对齐。
删除脸部之后,需要将脸部和原图片进行对齐。
这里可以打开gui工具
python3 faceswap.py gui复制代码
然后选择Tools下的Alignments。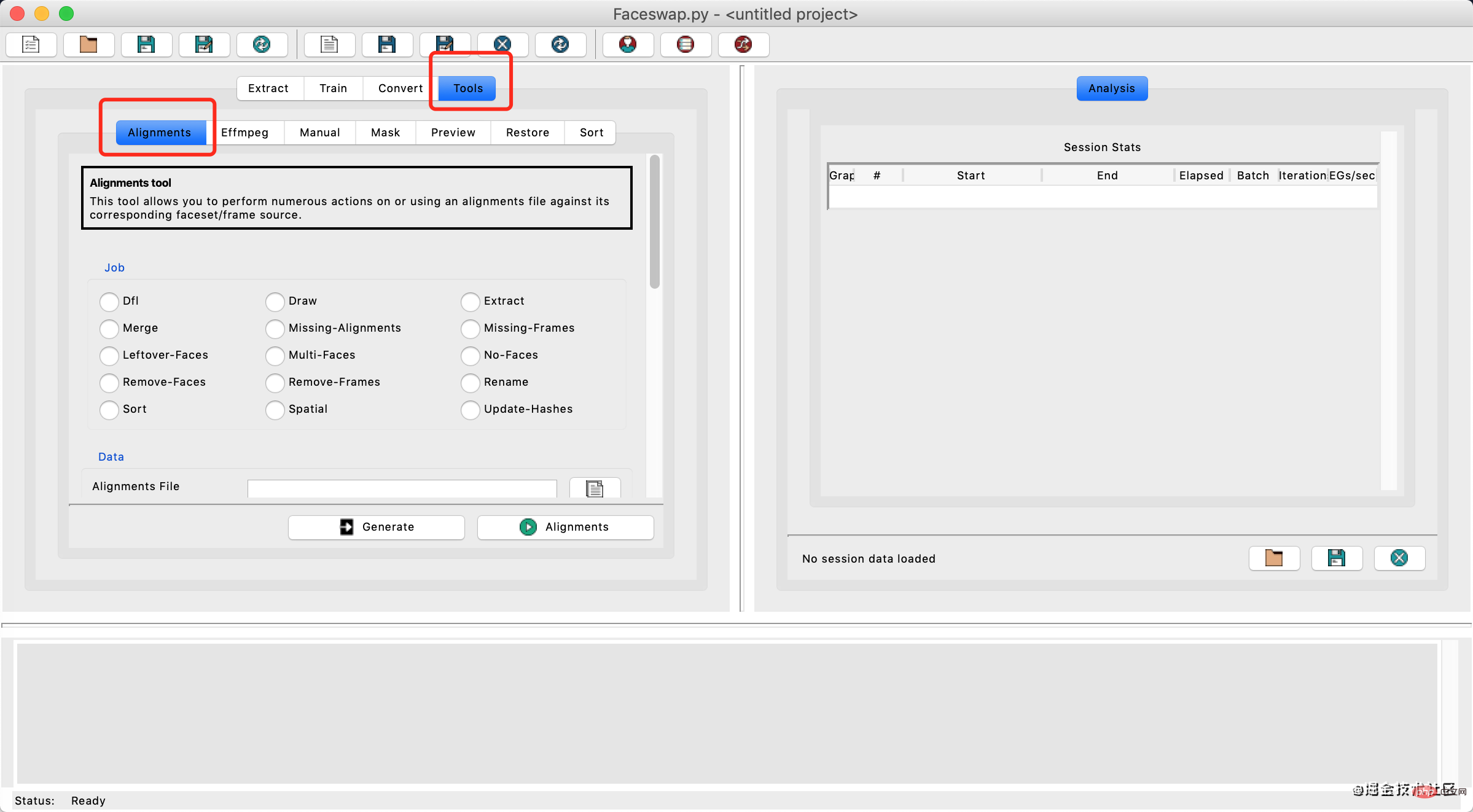
接下来选择Remove-Faces,然后输入对齐文件路径,脸的路径,以及原图的路径。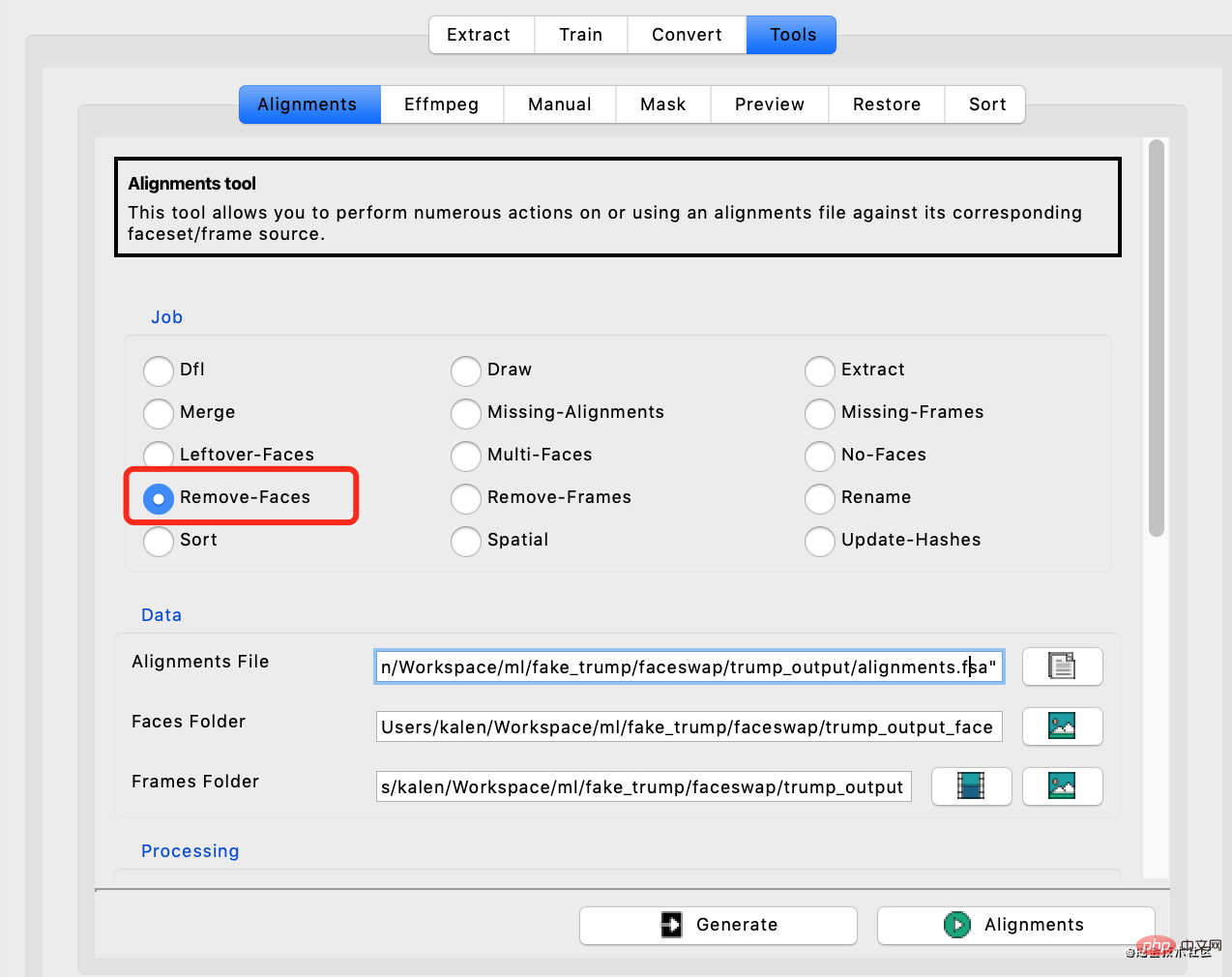
然后点击绿色按钮开始,运行即可。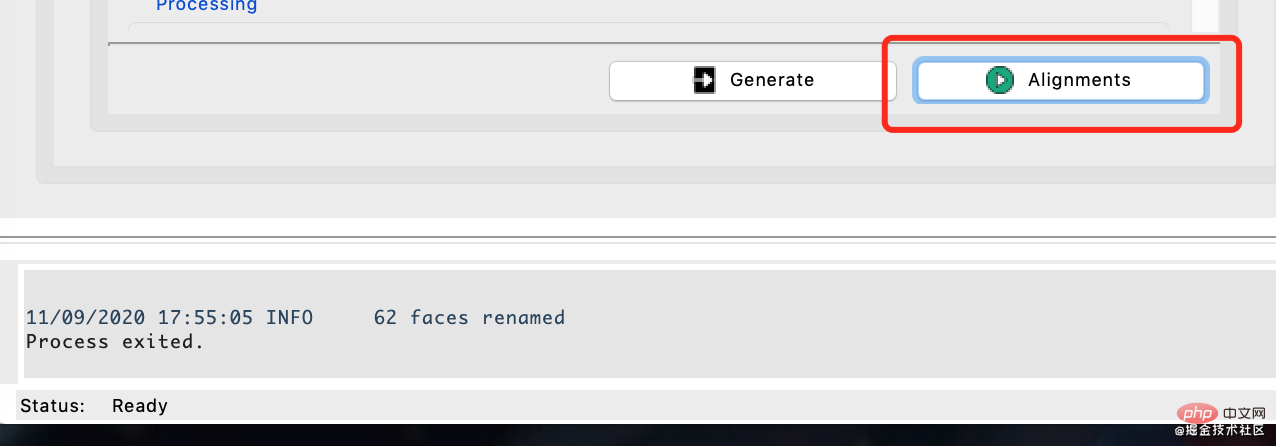
然后将sing_trump_out也执行同样的操作。
开始训练
接下来就可以开始训练了,-m参数为保存模型的位置。
python3 ./faceswap.py train -A sing_trump_output_face -ala sing_trump_output/alignments.fsa -B trump_output_face -alb trump_output/alignments.fsa -m model复制代码
小问题
这里如果用gpu的话,我发现tensorflow2.2开始要用cuda10.1以上,但我这边儿没法装,所以需要用tensorflow1.14或者tensorflow1.15,这就需要deepfake的1.0版本才能用。
github.com/deepfakes/f…
训练截图
我发现faceswap1.0和master分支的操作是一样的,没太大变化。
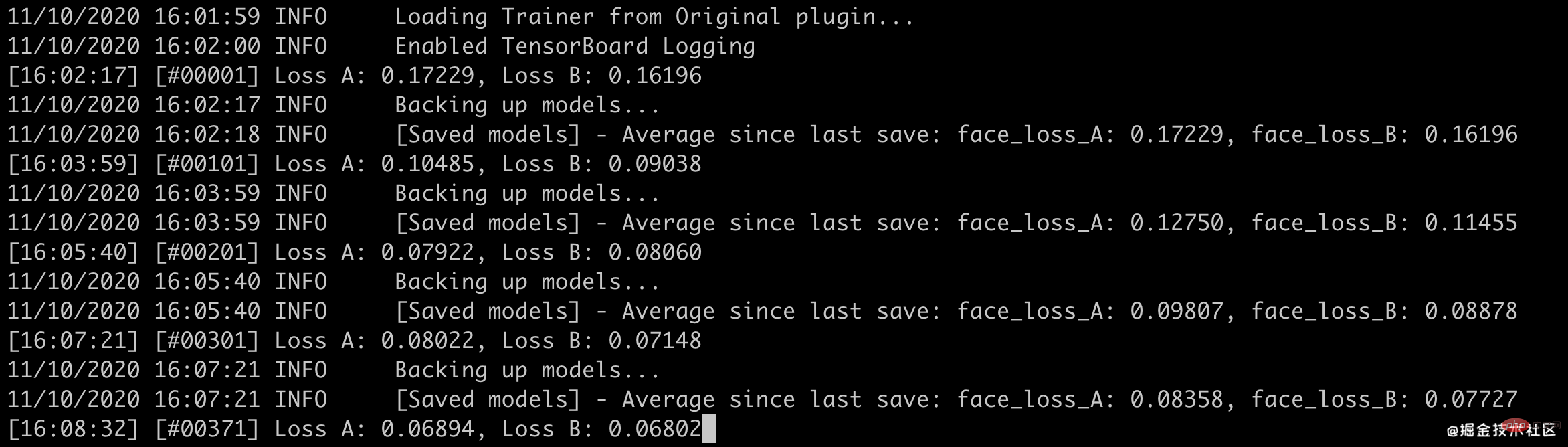 我这里的速度大概是2分钟100个step。
我这里的速度大概是2分钟100个step。
转换视频
准备视频帧
首先要准备我们要转换的视频,然后把视频切分,这里就不是按照之前的帧数了。
ffmpeg –i sing_trump2.flv input_frames/video-frame-%d.png 复制代码
这里我的视频是1分41秒。
转换完了大概有3050张图片,也就是差不多30帧的,然后一共7.1G(mac就256G真的有点儿遭不住)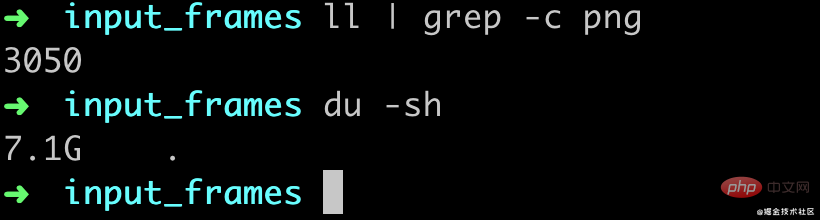
再次对齐一遍
接下来,需要对我们要转换的视频图片再来一遍人脸对齐,首先抽脸。
python3 faceswap.py extract -i input_frames -o input_frames_face复制代码
然后再把多余的脸删掉,像前面的步骤一样的操作用gui工具选择Remove-Faces,然后进行对齐。
对每一帧进行AI换脸
通过convert命令进行转换
python3 faceswap.py convert -i input_frames/ -o output_frames -m model/复制代码
我这里的速度大概是每秒1张图片,不过真正的脸只有600多张,如果脸比较密集的话我估计可能没有那么快,所有的图片转换完大概是5分多钟(这个gpu当时有别的程序在跑真实可能会更快一点儿)。
效果
训练20分钟后
在训练了1200step之后,大概是这个样子,效果看着还不是很好哈,不过已经有点儿意思了。
训练一个小时后

训练一天以后
把图片合成视频
最后通过ffmpeg把图片合成一个视频。
ffmpeg -i output_frames/video-frame-%d.png -vcodec libx264 -r 30 out.mp4复制代码
这里合并完了我发现是2分钟,不过影响也不大,毕竟后面还要进行剪辑,用PR等软件再编辑一下就好了。
总结
看视频可以发现当脸比较小的时候,faceswap并没有识别出来脸,所以也就没有做替换,还是有点儿遗憾。
个人感觉整个deepfake的最费时间的流程其实就是在删掉多余的脸上面。
推荐:python视频教程
以上就是都是第一次玩DeepFakes的详细内容,更多请关注自由互联其它相关文章!