
相关学习推荐:python教程
在python中,今天我们开始介绍一个新的常用的计算工具库,它就是大名鼎鼎的Pandas。
Pandas的全称是Python Data Analysis Library,是一种基于Numpy的科学计算工具。它最大的特点就是可以像是操作数据库当中的表一样操作结构化的数据,所以它支持许多复杂和高级的操作,可以认为是Numpy的加强版。它可以很方便地从一个csv或者是excel表格当中构建出完整的数据,并支持许多表级别的批量数据计算接口。
安装使用
和几乎所有的Python包一样,pandas也可以通过pip进行安装。如果你装过Anaconda套件的话,那么像是numpy、pandas等库已经自动安装好了,如果没有安装过也没有关系,我们使用一行命令即可完成安装。
pip install pandas复制代码
和Numpy一样,我们在使用pandas的时候通常也会给它起一个别名,pandas的别名是pd。所以使用pandas的惯例都是:
import pandas as pd复制代码
如果你运行这一行没有报错的话,那么说明你的pandas已经安装好了。一般和pandas经常一起使用的还有另外两个包,其中一个也是科学计算包叫做Scipy,另外一个是对数据进行可视化作图的工具包,叫做Matplotlib。我们也可以使用pip将这两个包一起安装了,在之后的文章当中,用到这两个包的时候,也会简单介绍一下它们的用法。
pip install scipy matplotlib复制代码
Series 索引
在pandas当中我们最常用的数据结构有两个,一个是Series另外一个是DataFrame。其中series是一维数据结构,可以简单理解成一维数组或者是一维向量。而DataFrame自然就是二维数据结构了,可以理解成表或者是二维数组。
我们先来看看Series,Series当中存储的数据主要有两个,一个是一组数据构成的数组,另外一个是这组数据的索引或者是标签。我们简单创建一个Series打印出来看一下就明白了。
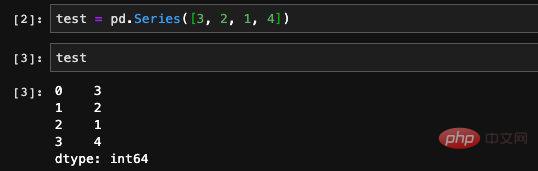
这里我们随意创建了一个包含四个元素的Series,然后将它打印了出来。可以看到打印的数据一共有两列,第二列是我们刚才创建的时候输入的数据,第一列就是它的索引。由于我们创建的时候没有特意指定索引,所以pandas会自动为我们创建行号索引,我们可以通过Series类型当中的values和index属性查看到Series当中存储的数据和索引:
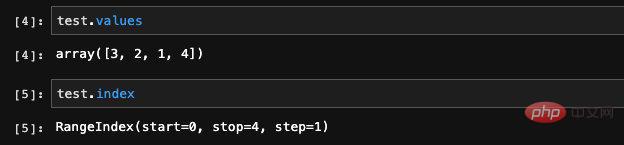
这里输出的values是一个Numpy的数组,这并不奇怪,因为我们前面说了,pandas是一个基于Numpy开发的科学计算库,Numpy是它的底层。从打印出来的index的信息当中,我们可以看到这是一个Range类型的索引,它的范围以及步长。
索引是Series构建函数当中的一个默认参数,如果我们不填,它默认会为我们生成一个Range索引,其实也就是数据的行号。我们也可以自己指定数据的索引,比如我们在刚才的代码当中加入index这个参数,我们就可以自己指定索引了。

当我们指定了字符类型的索引之后,index返回的结果就不再是RangeIndex而是Index了。说明pandas内部对数值型索引和字符型索引是做了区分的。
有了索引,自然是用来查找元素用的。我们可以直接将索引当做是数组的下标使用,两者的效果是一样的。不仅如此,索引数组也是可以接受的,我们可以直接查询若干个索引的值。
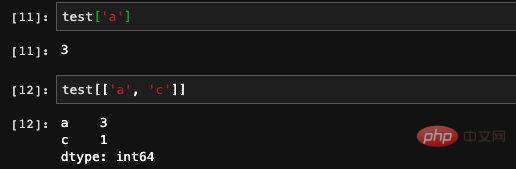
另外在创建Series的时候,重复的索引也是允许的。同样当我们使用索引查询的时候也会得到多个结果。

不仅如此,像是Numpy那样的bool型索引也依然是支持的:

Series计算
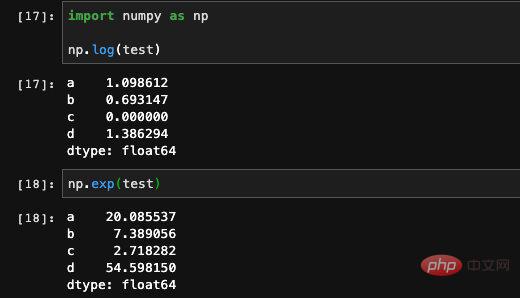
Series支持许多类型的计算,我们可以直接使用加减乘除操作对整个Series进行运算:
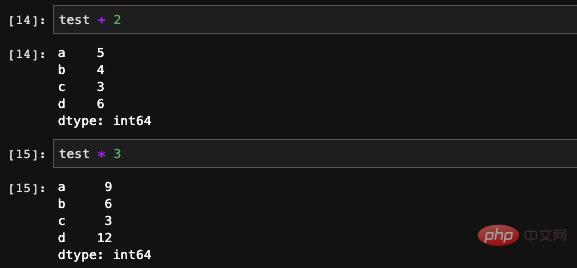
也可以使用Numpy当中的运算函数来进行一些复杂的数学运算,但是这样计算得到的结果会是一个Numpy的array。
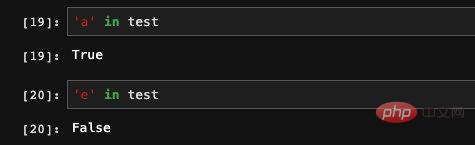
因为Series当中有索引,所以我们也可以使用dict的方式判断索引是否在Series当中:
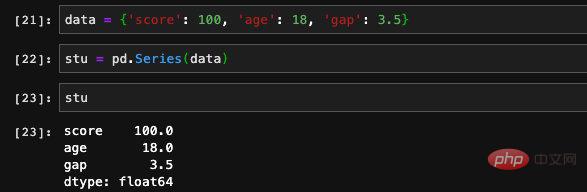
Series有索引也有值,其实和dict的存储结构是一样的,所以Seires也支持通过一个dict来初始化:
通过这种方式创建出来的顺序就是dict当中key存储的顺序,我们可以在创建的时候指定index,这样就可以控制它的顺序了。
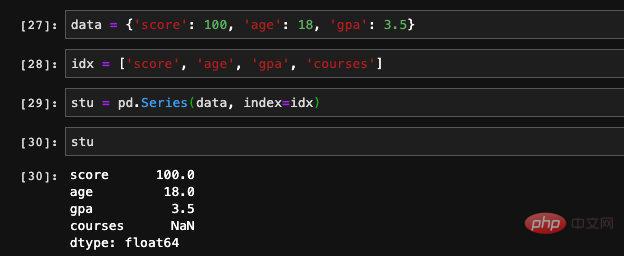
我们在指定index的时候额外传入了一个没有在dict当中出现过的key,由于在dict当中找不到对应的值,Series会将它记成NAN(Not a number)。可以理解成是非法值或者是空值,在我们处理特征或者是训练数据的时候,经常会遇到存在一些条目的数据的某个特征空缺的情况,我们可以通过pandas当中isnull和notnull函数检查空缺的情况。
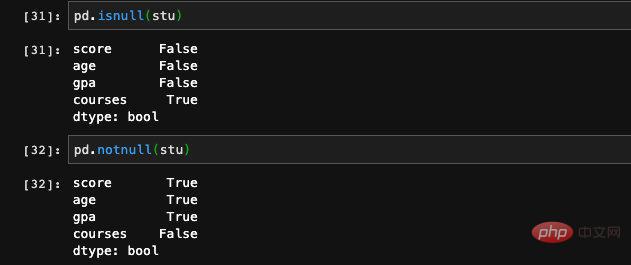
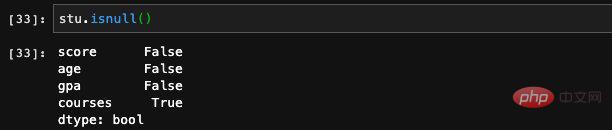
当然Series当中也有isnull的函数,我们也可以调用。
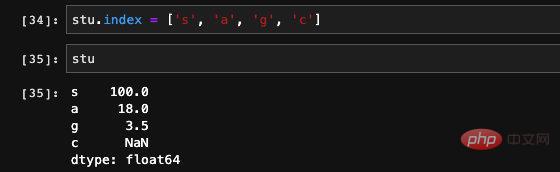
最后,Series当中的index也是可以修改的, 我们可以直接给它赋上新值:
总结
从核心本质上来说,pandas当中的Series就是在Numpy一维数组上做的一层封装,加上了索引等一些相关的功能。所以我们可以想见DataFrame其实就是一个Series的数组的封装,加上了更多数据处理相关的功能。我们把核心结构把握住了,再来理解整个pandas的功能要比我们一个一个死记这些api有用得多。
pandas是Python数据处理的一大利器,作为一个合格的算法工程师几乎是必会的内容,也是我们使用Python进行机器学习以及深度学习的基础。根据调查资料显示,算法工程师日常的工作有70%的份额投入在了数据处理当中,真正用来实现模型、训练模型的只有30%不到。因此可见数据处理的重要性,想要在行业当中有所发展,绝不仅仅是学会模型就足够的。
本文使用 mdnice 排版
想了解更多编程学习,敬请关注php培训栏目!
以上就是使用pandas进行数据处理之 Series篇的详细内容,更多请关注自由互联其它相关文章!