如果你需要一个PDF文件合并工具,那么本文章完全可以满足您的要求。哈喽,大家好呀,这里是滑稽研究所。不多废话,本期我们利用Python合并把多个pdf文件合并为一个。我们提前准备了5个pdf文件,来验证代码。
源代码:
import os
from PyPDF2 import PdfFileReader, PdfFileWriter
# 使用os模块的walk函数,搜索出指定目录下的全部PDF文件
# 获取同一目录下的所有PDF文件的绝对路径
def getFileName(filedir):
file_list = [os.path.join(root, filespath) \
for root, dirs, files in os.walk(filedir) \
for filespath in files \
if str(filespath).endswith('pdf')
]
return file_list if file_list else []
# 合并同一目录下的所有PDF文件
def MergePDF(filepath, outfile):
output = PdfFileWriter()
outputPages = 0
pdf_fileName = getFileName(filepath)
if pdf_fileName:
for pdf_file in pdf_fileName:
print("路径:%s"%pdf_file)
# 读取源PDF文件
input = PdfFileReader(open(pdf_file, "rb"))
# 获得源PDF文件中页面总数
pageCount = input.getNumPages()
outputPages += pageCount
print("页数:%d"%pageCount)
# 分别将page添加到输出output中
for iPage in range(pageCount):
output.addPage(input.getPage(iPage))
print("合并后的总页数:%d."%outputPages)
# 写入到目标PDF文件
outputStream = open(os.path.join(filepath, outfile), "wb")
output.write(outputStream)
outputStream.close()
print("PDF文件合并完成!")
else:
print("没有可以合并的PDF文件!")
# 主函数
def main():
file_dir = input('请输入存有Pdf的文件夹').replace('/','//')# 存放PDF的原文件夹
outfile = "pick_me.pdf" # 输出的PDF文件的名称
MergePDF(file_dir, outfile)
print('done')
main()
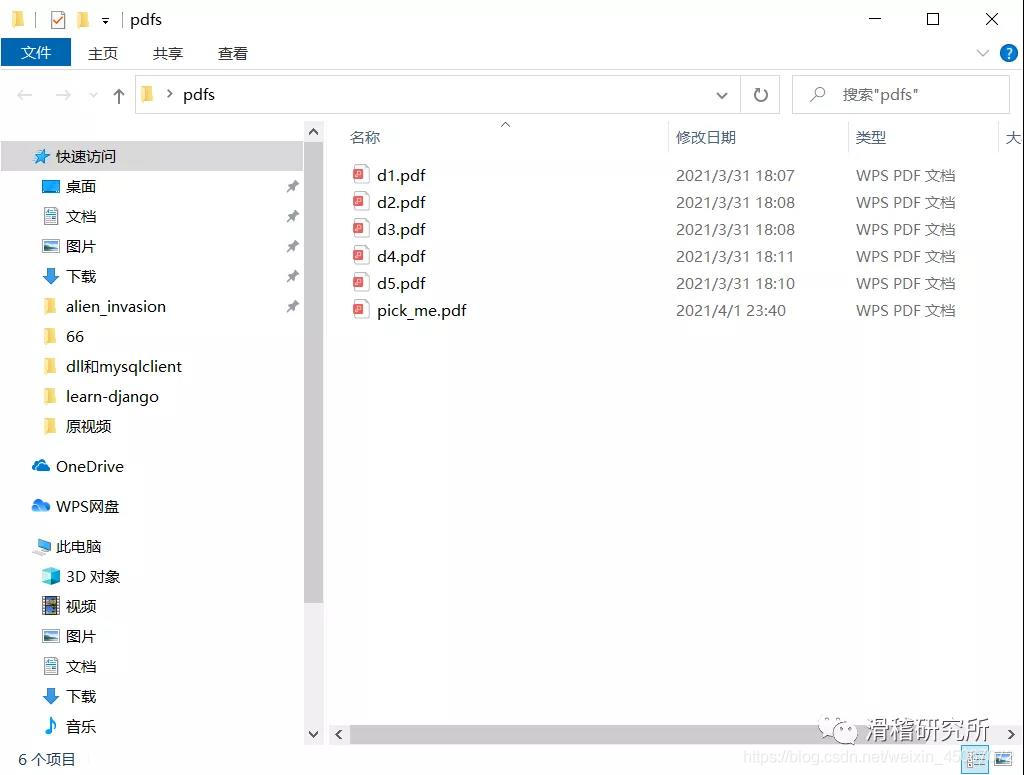
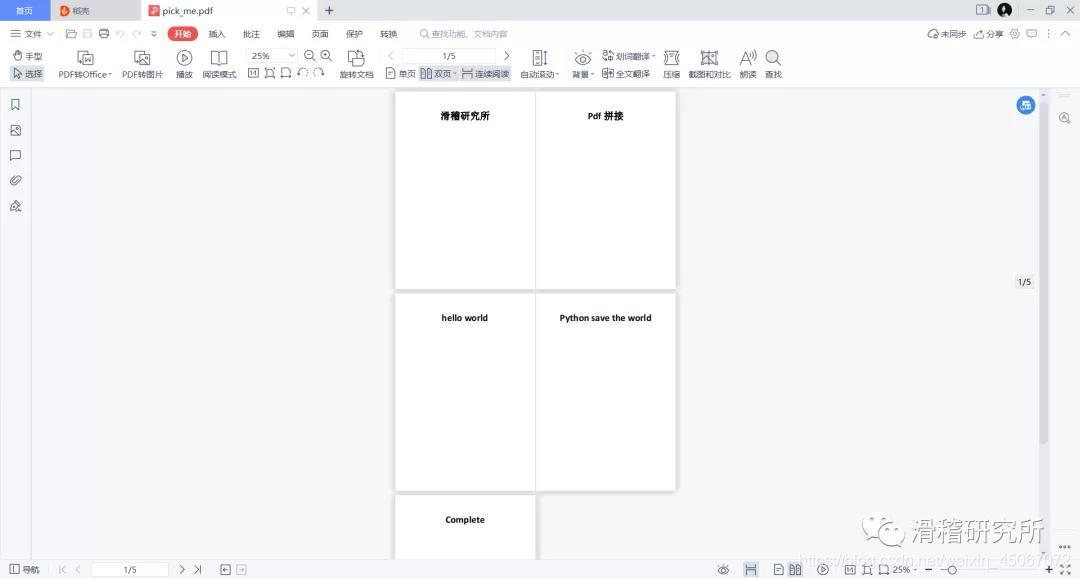
可以看到5个PDF文件合并到了一起,那么到这里就结束了吗?当然不是,代码运行遇到PDF文件中文件格式较多时,比如多图,word格式等,会出现以下报错。
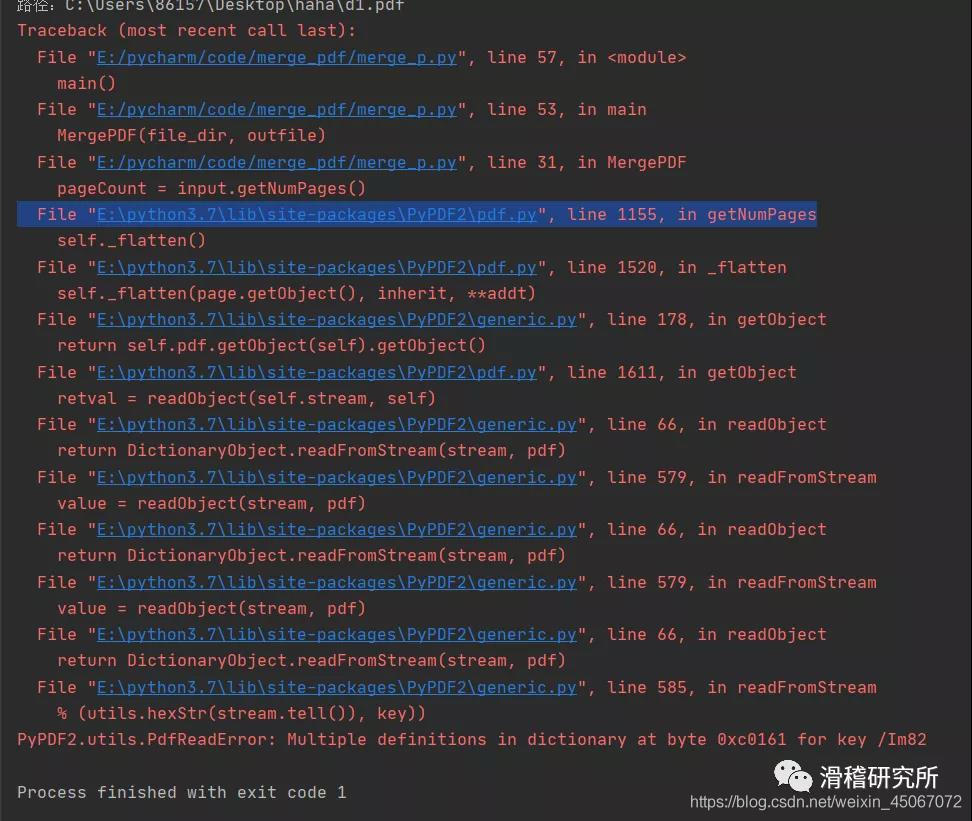
最后一行报错的意思为:
PyPDF2。utils.PdfReadError:对于键/Im82,字典中字节0xc0161处有多个定义
通俗一点就是说遇到了一个多义词,程序不知道该取哪个意思了。我们点进pdf.py文件里,找到下图位置。
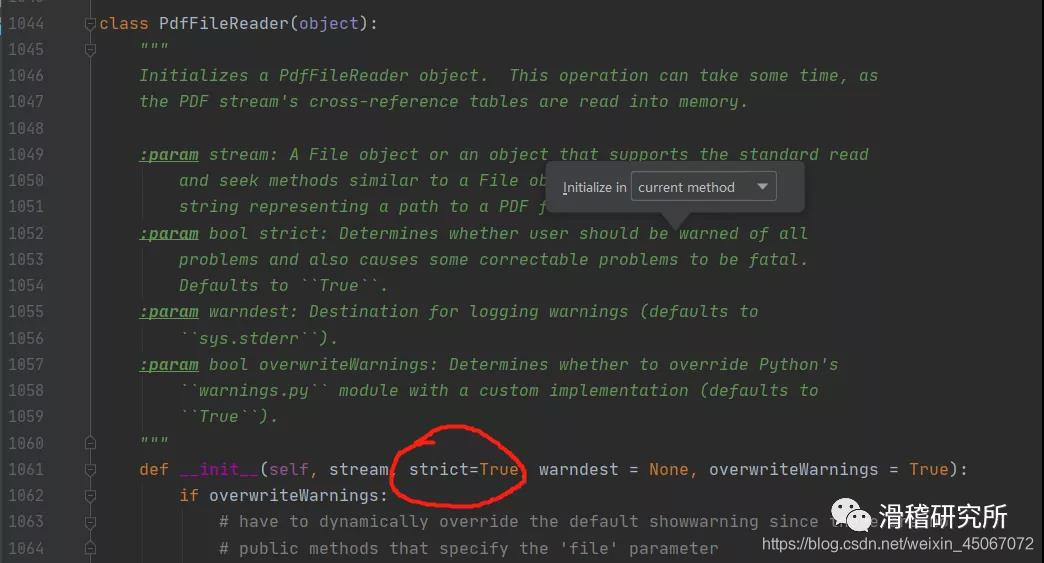
严格模式默认是打开的,我们改成False。
构造方法:
PyPDF2.PdfFileReader(stream,strict = True,warndest = None,overwriteWarnings = True)
stream:File 对象或支持与 File 对象类似的标准读取和查找方法的对象,也可以是表示 PDF 文件路径的字符串。
strict(bool):确定是否应该警告用户所用的问题,也导致一些可纠正的问题是致命的,默认是 True
warndest : 记录警告的目标(默认是 sys.stderr)
overwriteWarnings(bool):确定是否 warnings.py 用自定义实现覆盖 Python 模块(默认为 True)
我们重新运行程序.
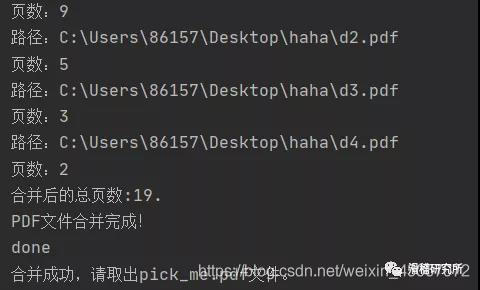
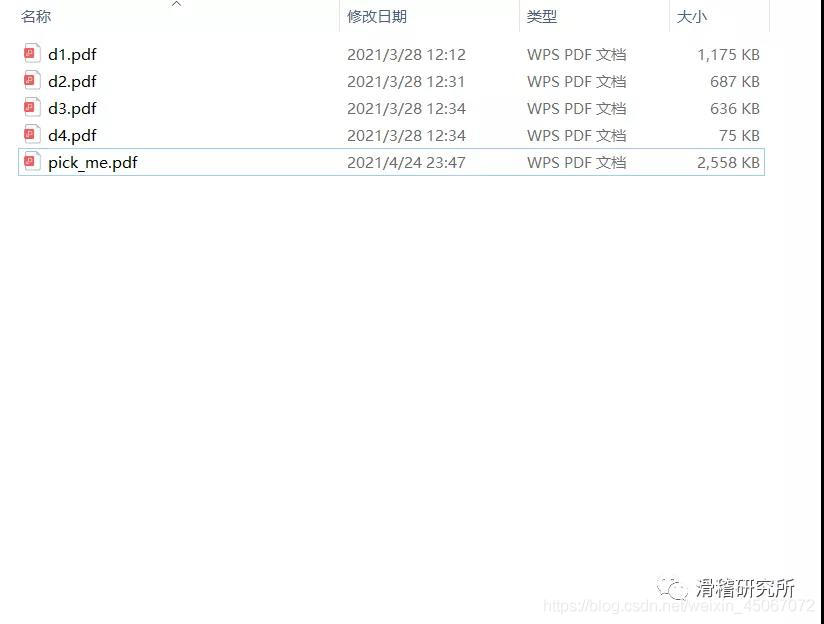
打开文件夹,可以看到我们的文件已经合并好了,打开之后的格式也是没有错误的。
那么,问题解决。
如果你只是需要应该PDF合并工具代码直接拿走用即可,如果你想学习pypdf2这个实用的库,并且希望对这段代码进行改进来适配自己的情况
到此这篇关于Python合并pdf文件的文章就介绍到这了,更多相关Python合并pdf文件内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!