项目需求
在专门供爬虫初学者训练爬虫技术的网站(http://quotes.toscrape.com)上爬取名言警句。
创建项目
在开始爬取之前,必须创建一个新的Scrapy项目。进入您打算存储代码的目录中,运行下列命令:
(base) λ scrapy startproject quotes
New scrapy project 'quotes ', using template directory 'd: \anaconda3\lib\site-packages\scrapy\temp1ates\project ', created in:
D:\XXX
You can start your first spider with :
cd quotes
scrapy genspider example example. com
首先切换到新建的爬虫项目目录下,也就是/quotes目录下。然后执行创建爬虫文件的命令:
D:\XXX(master) (base) λ cd quotes\ D:\XXX\quotes (master) (base) λ scrapy genspider quotes quotes.com cannot create a spider with the same name as your project D :\XXX\quotes (master) (base) λ scrapy genspider quote quotes.com created spider 'quote' using template 'basic' in module:quotes.spiders.quote
该命令将会创建包含下列内容的quotes目录:

robots.txt
robots协议也叫robots.txt(统一小写)是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜索引擎的网络蜘蛛,此网站中的哪些内容是不应被搜索引擎的爬虫获取的,哪些是可以被爬虫获取的。
robots协议并不是一个规范,而只是约定俗成的。
#filename : settings.py #obey robots.txt rules ROBOTSTXT__OBEY = False
分析页面
编写爬虫程序之前,首先需要对待爬取的页面进行分析,主流的浏览器中都带有分析页面的工具或插件,这里我们选用Chrome浏览器的开发者工具(Tools→Developer tools)分析页面。
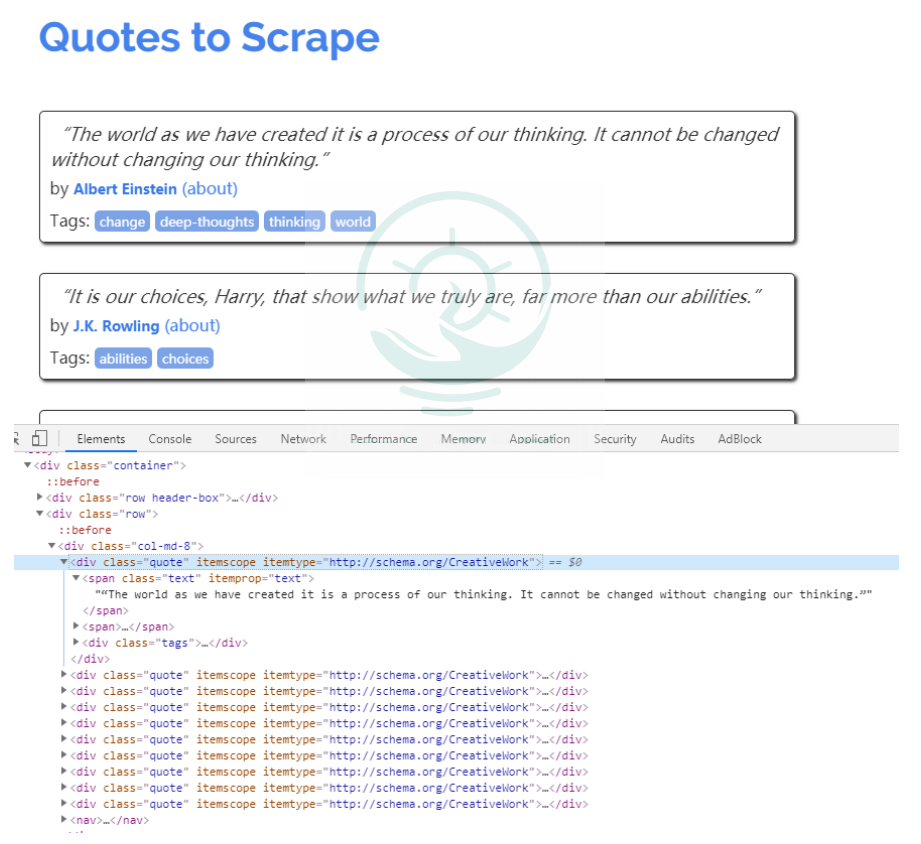
数据信息
在Chrome浏览器中打开页面http://lquotes.toscrape.com,然后选择"Elements",查看其HTML代码。
可以看到每一个标签都包裹在
编写spider
分析完页面后,接下来编写爬虫。在Scrapy中编写一个爬虫, 在scrapy.Spider中编写代码Spider是用户编写用于从单个网站(或者-些网站)爬取数据的类。
其包含了-个用于下载的初始URL,如何跟进网页中的链接以及如何分析页面中的内容,提取生成item的方法。
为了创建一个Spider, 您必须继承scrapy.Spider类,且定义以下三个属性:
- name:用于区别Spider。该名字必须是唯一-的, 您不可以为不同的Spider设定相同的名字。
- start _urls:包含了Spider在启动时进行爬取的ur列表。因此, 第一个被获取到的页面将是其中之一。后续的URL则从初始的URL获取到的数据中提取。
- parse():是spider的一一个方法。被调用时,每个初始URL完成下载后生成的Response对象将会作为唯一的参数传递给该函数。该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL 的Request对象。
import scrapy
class QuoteSpi der(scrapy . Spider):
name ='quote'
allowed_ domains = [' quotes. com ']
start_ urls = ['http://quotes . toscrape . com/']
def parse(self, response) :
pass
下面对quote的实现做简单说明。
- scrapy.spider :爬虫基类,每个其他的spider必须继承自该类(包括Scrapy自带的其他spider以及您自己编写的spider)。
- name是爬虫的名字,是在genspider的时候指定的。
- allowed_domains是爬虫能抓取的域名,爬虫只能在这个域名下抓取网页,可以不写。
- start_ur1s是Scrapy抓取的网站,是可迭代类型,当然如果有多个网页,列表中写入多个网址即可,常用列表推导式的形式。
- parse称为回调函数,该方法中的response就是start_urls 网址发出请求后得到的响应。当然也可以指定其他函数来接收响应。一个页面解析函数通常需要完成以下两个任务:
1.提取页面中的数据(re、XPath、CSS选择器)
2.提取页面中的链接,并产生对链接页面的下载请求。
页面解析函数通常被实现成一个生成器函数,每一项从页面中提取的数据以及每一个对链接页面的下载请求都由yield语句提交给Scrapy引擎。
解析数据
import scrapy
def parse(se1f,response) :
quotes = response.css('.quote ')
for quote in quotes:
text = quote.css( '.text: :text ' ).extract_first()
auth = quote.css( '.author : :text ' ).extract_first()
tages = quote.css('.tags a: :text' ).extract()
yield dict(text=text,auth=auth,tages=tages)
重点:
- response.css(直接使用css语法即可提取响应中的数据。
- start_ur1s 中可以写多个网址,以列表格式分割开即可。
- extract()是提取css对象中的数据,提取出来以后是列表,否则是个对象。并且对于
- extract_first()是提取第一个
运行爬虫
在/quotes目录下运行scrapycrawlquotes即可运行爬虫项目。
运行爬虫之后发生了什么?
Scrapy为Spider的start_urls属性中的每个URL创建了scrapy.Request对象,并将parse方法作为回调函数(callback)赋值给了Request。
Request对象经过调度,执行生成scrapy.http.Response对象并送回给spider parse()方法进行处理。
完成代码后,运行爬虫爬取数据,在shell中执行scrapy crawl <SPIDER_NAME>命令运行爬虫'quote',并将爬取的数据存储到csv文件中:
(base) λ scrapy craw1 quote -o quotes.csv 2021-06-19 20:48:44 [scrapy.utils.log] INF0: Scrapy 1.8.0 started (bot: quotes)
等待爬虫运行结束后,就会在当前目录下生成一个quotes.csv的文件,里面的数据已csv格式存放。
-o支持保存为多种格式。保存方式也非常简单,只要给上文件的后缀名就可以了。(csv、json、pickle等)
到此这篇关于Python爬虫基础之初次使用scrapy爬虫实例的文章就介绍到这了,更多相关Python scrapy框架内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!