一、tensorboard的简要介绍
TensorBoard是一个独立的包(不是pytorch中的),这个包的作用就是可视化您模型中的各种参数和结果。
下面是安装:
pip install tensorboard
安装 TensorBoard 后,这些实用程序使您可以将 PyTorch 模型和指标记录到目录中,以便在 TensorBoard UI 中进行可视化。 PyTorch 模型和张量以及 Caffe2 网络和 Blob 均支持标量,图像,直方图,图形和嵌入可视化。
SummaryWriter 类是您用来记录数据以供 TensorBoard 使用和可视化的主要入口。
看一个例子,在这个例子中,您重点关注代码中的注释部分:
import torch
import torchvision
from torchvision import datasets, transforms
# 可视化工具, SummaryWriter的作用就是,将数据以特定的格式存储到上面得到的那个日志文件夹中
from torch.utils.tensorboard import SummaryWriter
# 第一步:实例化对象。注:不写路径,则默认写入到 ./runs/ 目录
writer = SummaryWriter()
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
trainset = datasets.MNIST('mnist_train', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
model = torchvision.models.resnet50(False)
# 让 ResNet 模型采用灰度而不是 RGB
model.conv1 = torch.nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False)
images, labels = next(iter(trainloader))
grid = torchvision.utils.make_grid(images)
# 第二步:调用对象的方法,给文件夹存数据
writer.add_image('images', grid, 0)
writer.add_graph(model, images)
writer.close()
点击运行之后,我们就可以在文件夹下看到我们保存的数据了,然后我们就可以使用 TensorBoard 对其进行可视化,该 TensorBoard 应该可通过以下方式运行(在命令行):
tensorboard --logdir=runs
运行结果:

把上述的地址,粘贴到浏览器就可以看到可视化的结果了,如下所示:
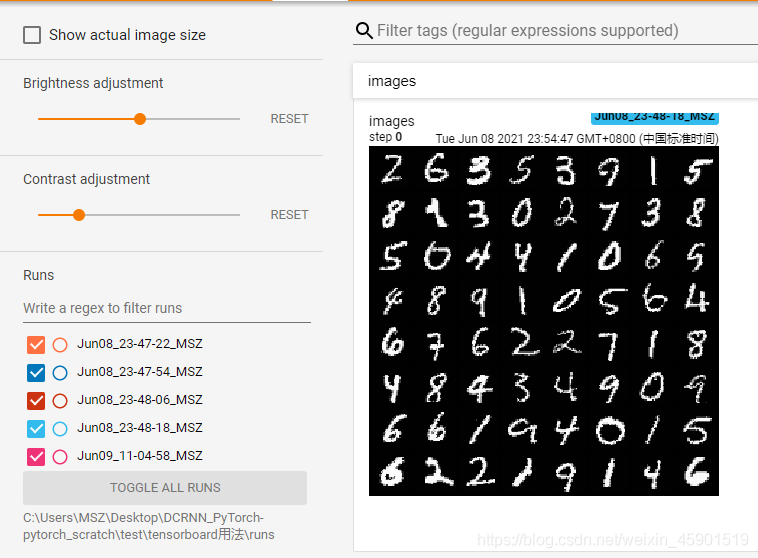
接着看:
一个实验可以记录很多信息。 为了避免 UI 混乱和更好地将结果聚类,我们可以通过对图进行分层命名来对图进行分组。 例如,“损失/训练”和“损失/测试”将被分组在一起,而“准确性/训练”和“准确性/测试”将在 TensorBoard 界面中分别分组。
我们再看一个更简单的例子来理解上面的话:
from torch.utils.tensorboard import SummaryWriter
import numpy as np
# 第一步:实例化对象。注:不写参数默认是 ./run/ 文件夹下
writer = SummaryWriter()
for n_iter in range(100):
# 第二步:调用对象的方法,给文件夹存数据
writer.add_scalar('Loss/train', np.random.random(), n_iter)
writer.add_scalar('Loss/test', np.random.random(), n_iter)
writer.add_scalar('Accuracy/train', np.random.random(), n_iter)
writer.add_scalar('Accuracy/test', np.random.random(), n_iter)
writer.close()
点击运行(保存数据); 在命令行输入tensorboard --logdir=run(run是保存的数据的所在路径)
实验结果:
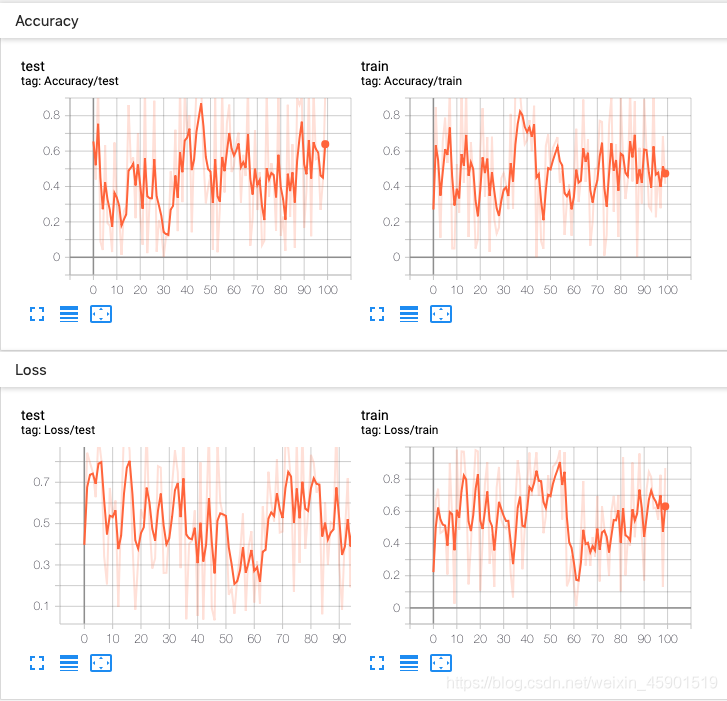
好了,现在你对tensorboard有了初步的认识,也知道了怎么在pytorch中 保存模型在运行过程中的一些数据了,还知道了怎么把tensorboard运行起来了。
但是,我们还没有细讲前面提到的几个函数,因此接下来我们看这几个函数的具体使用。
二、torch.utils.tensorboard涉及的几个函数
2.1 SummaryWriter()类
API:
class torch.utils.tensorboard.writer.SummaryWriter(log_dir=None, comment='', purge_step=None, max_queue=10, flush_secs=120, filename_suffix='')
作用:将数据保存到 log_dir 文件夹下 以供 TensorBoard 使用。
SummaryWriter 类提供了一个高级 API,用于在给定目录中创建事件文件并向其中添加摘要和事件。 该类异步更新文件内容。 这允许训练程序从训练循环中调用直接将数据添加到文件的方法,而不会减慢训练速度。
下面是SummaryWriter()类的构造函数:
def __init__(log_dir=None, comment='', purge_step=None, max_queue=10, flush_secs=120, filename_suffix='')
作用:创建一个 SummaryWriter 对象,它将事件和摘要写到事件文件中。
参数说明:
log_dir(字符串):保存目录位置。 默认值为 run/CURRENT_DATETIME_HOSTNAME ,每次运行后都会更改。 使用分层文件夹结构可以轻松比较运行情况。 例如 为每个新实验传递“ runs / exp1”,“ runs / exp2”等,以便在它们之间进行比较。comment(字符串):注释 log_dir 后缀附加到默认值log_dir。 如果分配了log_dir,则此参数无效。purge_step(python:int ):当日志记录在步骤 T + X T+X T+X 崩溃并在步骤 T T T 重新启动时,将清除 global_step 大于或等于的所有事件, 隐藏在 TensorBoard 中。 请注意,崩溃的实验和恢复的实验应具有相同的log_dir。max_queue(python:int ):在“添加”调用之一强行刷新到磁盘之前,未决事件和摘要的队列大小。 默认值为十个项目。flush_secs(python:int ):将挂起的事件和摘要刷新到磁盘的频率(以秒为单位)。 默认值为每两分钟一次。filename_suffix(字符串):后缀添加到 log_dir 目录中的所有事件文件名中。 在 tensorboard.summary.writer.event_file_writer.EventFileWriter 中有关文件名构造的更多详细信息。
例子:
from torch.utils.tensorboard import SummaryWriter
# 使用自动生成的文件夹名称创建summary writer
writer = SummaryWriter()
# folder location: runs/May04_22-14-54_s-MacBook-Pro.local/
# 使用指定的文件夹名称创建summary writer
writer = SummaryWriter("my_experiment")
# folder location: my_experiment
# 创建一个附加注释的 summary writer
writer = SummaryWriter(comment="LR_0.1_BATCH_16")
# folder location: runs/May04_22-14-54_s-MacBook-Pro.localLR_0.1_BATCH_16/
2.2 add_scalar()函数
API:
add_scalar(tag, scalar_value, global_step=None, walltime=None)
作用:将标量数据添加到summary
参数说明:
tag(string) : 数据标识符scalar_value(float or string/blobname) : 要保存的值global_step(int) :要记录的全局步长值,理解成 x坐标walltime(float):可选,以事件发生后的秒数覆盖默认的 walltime(time.time())
例子:
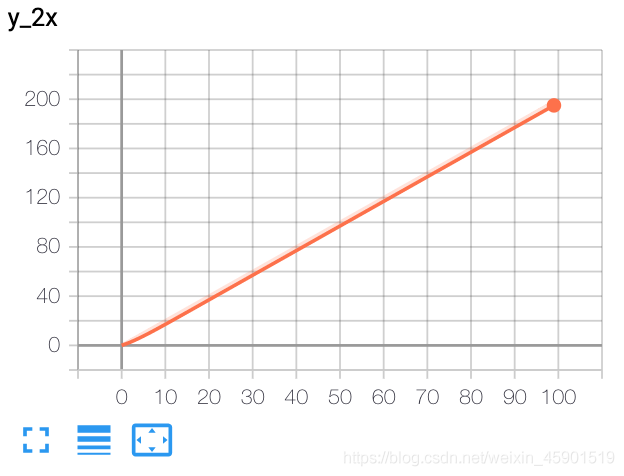
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
x = range(100)
for i in x:
writer.add_scalar('y_2x', i * 2, i)
writer.close()
结果:
2.3 add_scalars()函数
API:
add_scalars(main_tag, tag_scalar_dict, global_step=None, walltime=None)
作用:将许多标量数据添加到 summary 中。
参数说明:
main_tag(string) :标记的父名称tag_scalar_dict(dict) :存储标签和对应值的键值对global_step(int) :要记录的全局步长值walltime(float) :可选的替代默认时间 Walltime(time.time())秒
例子:
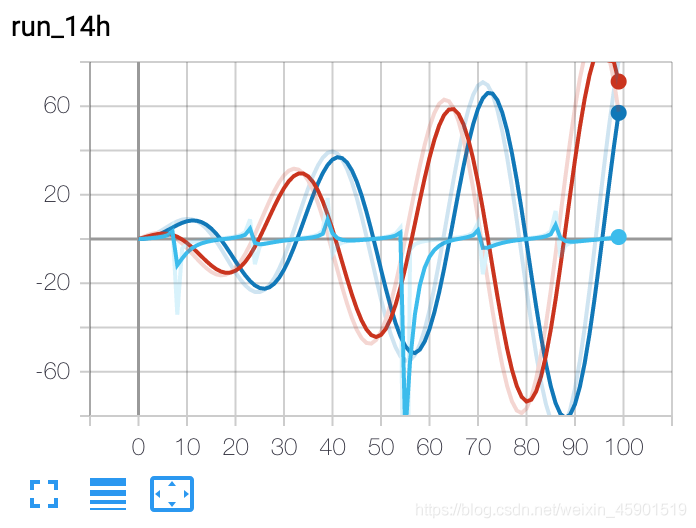
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
r = 5
for i in range(100):
writer.add_scalars('run_14h', {'xsinx':i*np.sin(i/r),
'xcosx':i*np.cos(i/r),
'tanx': np.tan(i/r)}, i)
writer.close()
# 此调用将三个值添加到带有标记的同一个标量图中
# 'run_14h' 在 TensorBoard 的标量部分
结果:
2.4 add_histogram()
add_histogram(tag, values, global_step=None, bins='tensorflow', walltime=None, max_bins=None)
作用:将直方图添加到 summary 中。
参数说明:
tag(string): 数据标识符values(torch.Tensor, numpy.array, or string/blobname) :建立直方图的值global_step(int) :要记录的全局步长值bins(string) : One of {‘tensorflow','auto', ‘fd', …}. 这决定了垃圾箱的制作方式。您可以在以下位置找到其他选项:https://docs.scipy.org/doc/numpy/reference/generated/numpy.histogram.htmlwalltime(float) – Optional override default walltime (time.time()) seconds after epoch of event
例子:
from torch.utils.tensorboard import SummaryWriter
import numpy as np
writer = SummaryWriter()
for i in range(10):
x = np.random.random(1000)
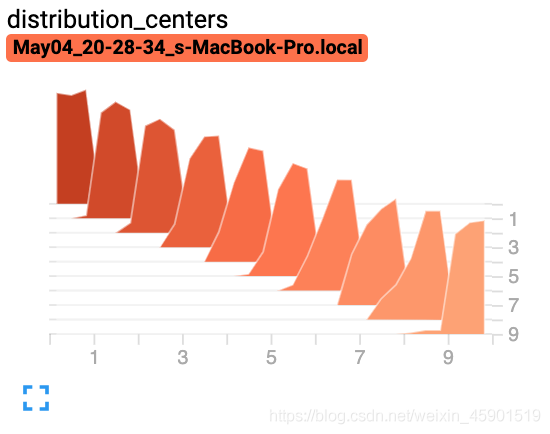
writer.add_histogram('distribution centers', x + i, i)
writer.close()
结果:
我用到了上面的这些,关于更多的函数说明 ,请点击这里查看:https://pytorch.org/docs/stable/tensorboard.html#torch-utils-tensorboard
到此这篇关于在Pytorch中简单使用tensorboard的文章就介绍到这了,更多相关Pytorch使用tensorboard内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!