Linux下通过使用 tr文本处理命令,您可以非常容易地实现 sed 的许多最基本功能。您可以将 tr 看作为 sed 的(极其)简化的变体:它可以用一个字符来替换另一个字符,或者可以完全除去一些字符。您也可以用它来除去重复字符。这就是所有 tr 所能够做的。

命令格式
tr [option] ["string1"] ["string2"] < file
常用的选项有:
默认选项。就是没有任何选项的时候,tr默认为替换操作,就是将string1在文件中出现的字符替换为string2中的字符,这里要注意的是替换关系。
-c选项,用string1中字符的补集替换string1,这里的字符集为ASCII。
-d选项,删除文件中所有在string1中出现的字符。
-s选项,删除文件中重复并且在string1中出现的字符,只保留一个。
-c选项在使用时,只是将string1替换为现在的补集,如在使用
558idc@Ubuntu:~/558idc.com$ echo "hello world,558idc.com,2019" | tr -c "0-9" "*"
*************************2019*
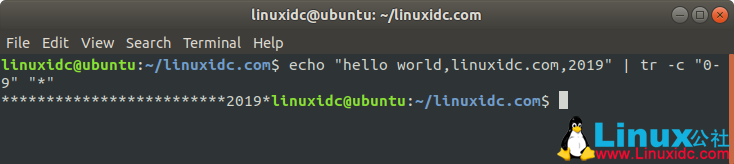
558idc@ubuntu:~/558idc.com$ echo "hello world,558idc.com,2019" | tr "0-9" "*"
hello world,558idc.com,****

可以看出,我们使用0-9,添加-c选项后,会把0-9替换为其补集,这时补集自然不包含0-9,而包含很多其它的字符,接下来就把所有的其它字符都替换成*号,但不包含数字。
字符串的取值范围
指定string或string2的内容时,只能使用单字符或字符串范围或列表。
[a-z] a-z内的字符组成的字符串。
[A-Z] A-Z内的字符组成的字符串。
[0-9] 数字串。
\octal 一个三位的八进制数,对应有效的ASCII字符。
[O*n] 表示字符O重复出现指定次数n。因此[O*2]匹配OO的字符串。
控制字符的不同表达方式
速记符 含义 八进制方式
\a Ctrl-G 铃声\007
\b Ctrl-H 退格符\010
\f Ctrl-L 走行换页\014
\n Ctrl-J 新行\012
\r Ctrl-M 回车\015
\t Ctrl-I tab键\011
\v Ctrl-X \030 注意这些控制字符,如果想在linux下输入,如我们可能需要输入^M这种字符,只需ctrl+V+M同时按下即可。
字符替换
558idc@ubuntu:~/558idc.com$ echo "hello world,www.558idc.com" | tr "a-z" "A-Z"
HELLO WORLD,WWW.LINUXIDC.COM
558idc@ubuntu:~/558idc.com$ echo "hello world,www.558idc.com" | tr "a-l" "A-Z"
HELLo worLD,www.LInuxIDC.Com
558idc@ubuntu:~/558idc.com$ echo "hello world,www.558idc.com" | tr "a-z" "A-H"
HEHHH HHHHD,HHH.HHHHHHDC.CHH
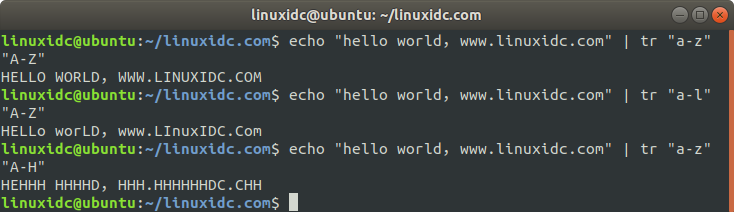
第一行输出就是将小写换成大写。
第二行输出将小写中的a-l分别换成A-L,而将小写中的l以后的字符都不替换。
第三行输出将小写中的a-h换成A-H,而h以后的字符都换成H,因为后者的替换空间没有前面的字符空间大,所以就重复后面的H,相当于后面的字符是A-HHH......HHHHH。
如果我们想要进行大小写转换,可以按下面的输入:
tr "a-z" "A-Z" < inputfile
去除重复字符
这个时候,所用的选项是-s选项,如:
558idc@ubuntu:~/558idc.com$ echo "root,hello world,558idc.com" | tr -s "ao"
rot,hello world,558idc.com
558idc@ubuntu:~/558idc.com$ echo "root,hello world,558idc.com" | tr -s "lo"
rot,helo world,558idc.com
558idc@ubuntu:~/558idc.com$ echo "root,hello world,558idc.com" | tr -s "a-z"
rot,helo world,558idc.com
558idc@ubuntu:~/558idc.com$ echo "root,hello world,558idc.com" | tr -s "0-9"
root,hello world,558idc.com

第一行表示将输入字符串中的包含在"ao"字符集中的重复字符去掉,只留一个。因为"hello world,558idc.com",只有o满足条件,所以将558idc.com变成rot,把中间的两个o变成一个。
第二行将hello和558idc.com两个字符都压缩了。
第三行表示将a-z中的除复字符都去掉。
第三行表示将字符串中的重复的且重复字符在0-9字符集中的字符去掉,这里没有。
如果我们想要去掉空行,可以这样操作:
tr -s "\n" < inputfile 或者 tr -s "\012" <inputfile // 这两个是一样的。
就是将重复的换行符去掉,只留一个。
删除字符
-d选项和-s选项类似,只不过-d选项会删除所有出现的字符。
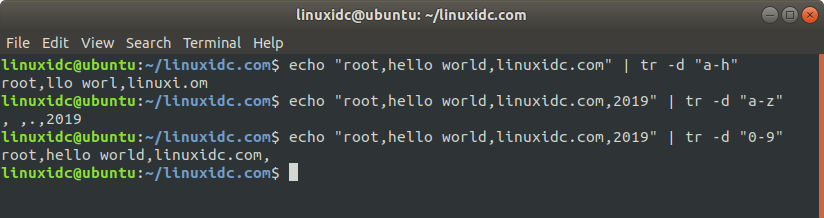
558idc@ubuntu:~/558idc.com$ echo "root,hello world,558idc.com" | tr -d "a-h"
root,llo worl,linuxi.om
558idc@ubuntu:~/558idc.com$ echo "root,hello world,558idc.com,2019" | tr -d "a-z"
, ,.,2019
558idc@ubuntu:~/558idc.com$ echo "root,hello world,558idc.com,2019" | tr -d "0-9"
root,hello world,558idc.com,
更多Linux命令相关信息见Linux命令大全 专题页面 https://www.558idc.com/topicnews.aspx?tid=16