规范总结
-
所有数据库对象名称必须使用小写字母并用下划线分割
-
所有数据库对象名称禁止使用 MySQL 保留关键字【设计表后逐一排查】
-
所有表必须使用 Innodb 存储引擎,数据库和表的字符集统一使用 UTF8
-
所有表和字段都需要添加注释
-
禁止在数据库中存储图片,文件等大的二进制数据
【通常存储于文件服务器,数据库只存储文件地址信息】
-
优先选择符合存储需要的最小的数据类型【能用整型就不要用字符串】【ip字符串转换成整型】
-
避免使用text,blob类型,会大大降低SQL执行效率
-
避免使用ENUM类型,无法使用索引,查询效率低
-
尽可能把所有列定义为 NOT NULL【实在不行赋予默认值】
【索引 NULL 列需要额外的空间来保存,所以要占用更多的空间】
-
使用 TIMESTAMP(4 个字节) 或 DATETIME 类型 (8 个字节) 存储时间【切忌使用字符串】
-
同财务相关的金额类数据必须使用 decimal 类型【精准浮点数据类型,double和float是非精准的】
三大范式
-
第一范式:具备原子性,不可分解。
id name age address
其中address可以细分为国家,省市,区域。
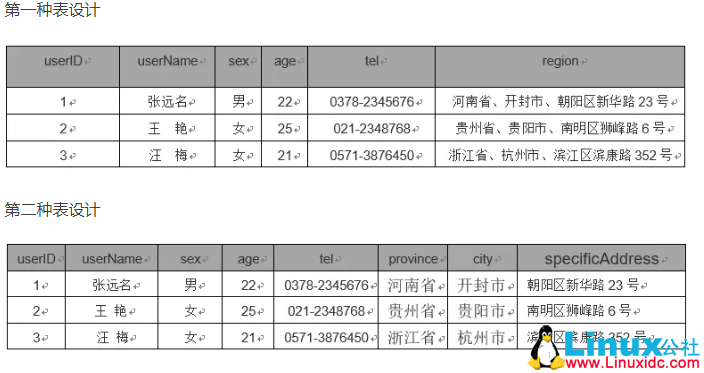
-
第二范式:需要确保数据库表中每一列都和主键相关
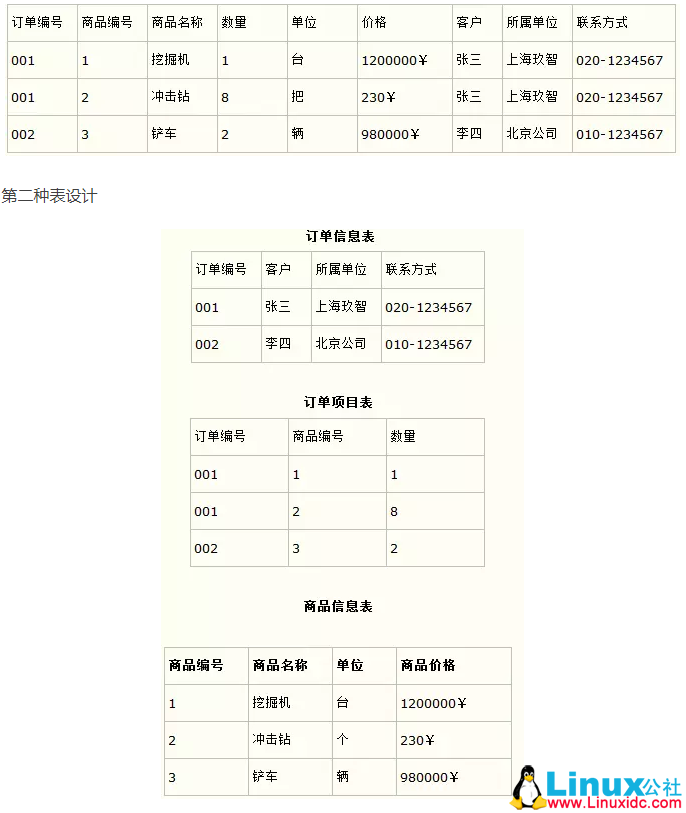
-
第三范式:不允许数据冗余
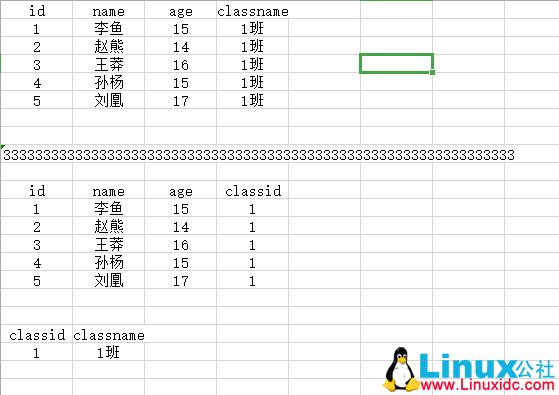
数据库命名规范
1.所有数据库对象名称必须使用小写字母并用下划线分割
表名:users,users_like-videos,users_fans
表头:id,face_image,nickname
why??
MySQL对象名默认规定大小写敏感,且在生产环境中MySQL通常运行在Linux系统下,Linux系统本身也是大小写敏感的。
2.所有数据库对象名称禁止使用 MySQL 保留关键字(如果表名中包含关键字查询时,需要将其用单引号括起来)
关于MySQL保留关键字
WHERE,INSERT,UPDATE,SET,SELECT
https://dev.mysql.com/doc/mysqld-version-reference/en/keywords-8-0.html
建议在设计数据表之后逐一排查有没有使用关键字。
数据库基本设计规范
1. 所有表必须使用 Innodb 存储引擎
没有特殊要求(即 Innodb 无法满足的功能如:列存储,存储空间数据等)的情况下,所有表必须使用 Innodb 存储引擎(MySQL5.5 之前默认使用 Myisam,5.6 以后默认的为 Innodb)。
Innodb 支持事务,支持行级锁,更好的恢复性,高并发下性能更好。
MyISAM只支持表级锁,适用插入不频繁,查询频繁的场景。
- 关于存储引擎

2. 数据库和表的字符集统一使用 UTF8
兼容性更好,统一字符集可以避免由于字符集转换产生的乱码,不同的字符集进行比较前需要进行转换会造成索引失效,如果数据库中有存储 emoji 表情的需要,字符集需要采用 utf8mb4 字符集。
3. 所有表和字段都需要添加注释
使用 comment 从句添加表和列的备注,从一开始就进行数据字典的维护
/*表: user_info*/------------------
/*列信息*/-----------
Field Type Collation Null Key Default Extra Privileges Comment
-------- ----------- --------------- ------ ------ ------- -------------- ------------------------------- --------------
id int(10) (NULL) NO PRI (NULL) auto_increment select,insert,update,references 用户id
username varchar(10) utf8_general_ci YES (NULL) select,insert,update,references 用户姓名
password varchar(20) utf8_general_ci YES (NULL) select,insert,update,references 用户密码
age int(5) (NULL) YES (NULL) select,insert,update,references 年龄
email varchar(20) utf8_general_ci YES (NULL) select,insert,update,references 邮箱
/*索引信息*/--------------
Table Non_unique Key_name Seq_in_index Column_name Collation Cardinality Sub_part Packed Null Index_type Comment Index_comment
--------- ---------- -------- ------------ ----------- --------- ----------- -------- ------ ------ ---------- ------- ---------------
user_info 0 PRIMARY 1 id A 99 (NULL) (NULL) BTREE
/*DDL 信息*/------------
CREATE TABLE `user_info` (
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT '用户id',
`username` varchar(10) DEFAULT NULL COMMENT '用户姓名',
`password` varchar(20) DEFAULT NULL COMMENT '用户密码',
`age` int(5) DEFAULT NULL COMMENT '年龄',
`email` varchar(20) DEFAULT NULL COMMENT '邮箱',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=100 DEFAULT CHARSET=utf8 COMMENT='用户信息表'
4. 禁止在数据库中存储图片,文件等大的二进制数据
通常文件很大,会短时间内造成数据量快速增长,数据库进行数据库读取时,通常会进行大量的随机 IO 操作,文件很大时,IO 操作很耗时。
通常存储于文件服务器,数据库只存储文件地址信息
数据库字段设计规范
1. 优先选择符合存储需要的最小的数据类型
原因:
列的字段越大,建立索引时所需要的空间也就越大,这样一页中所能存储的索引节点的数量也就越少也越少,在遍历时所需要的 IO 次数也就越多,索引的性能也就越差。
方法:
a.将字符串转换成数字类型存储,如:将 IP 地址转换成整形数据
MySQL 提供了两个方法来处理 ip 地址
- inet_aton 把 ip 转为无符号整型 (4-8 位)
- inet_ntoa 把整型的 ip 转为地址
插入数据前,先用 inet_aton 把 ip 地址转为整型,可以节省空间,显示数据时,使用 inet_ntoa 把整型的 ip 地址转为地址显示即可。
b.对于非负型的数据 (如自增 ID,整型 IP) 来说,要优先使用无符号整型来存储
原因:
无符号相对于有符号可以多出一倍的存储空间
SIGNED INT -2147483648~2147483647
UNSIGNED INT 0~4294967295VARCHAR(N) 中的 N 代表的是字符数,而不是字节数,使用 UTF8 存储 255 个汉字 Varchar(255)=765 个字节。过大的长度会消耗更多的内存。
2. 避免使用 TEXT,BLOB 数据类型,最常见的 TEXT 类型可以存储 64k 的数据
建议把 BLOB 或是 TEXT 列分离到单独的扩展表中
MySQL 内存临时表不支持 TEXT、BLOB 这样的大数据类型,如果查询中包含这样的数据,在排序等操作时,就不能使用内存临时表,必须使用磁盘临时表进行。而且对于这种数据,MySQL 还是要进行二次查询,会使 sql 性能变得很差,但是不是说一定不能使用这样的数据类型。
如果一定要使用,建议把 BLOB 或是 TEXT 列分离到单独的扩展表中,查询时一定不要使用 select * 而只需要取出必要的列,不需要 TEXT 列的数据时不要对该列进行查询。
3. 避免使用 ENUM 类型
修改 ENUM 值需要使用 ALTER 语句
ENUM 类型的 ORDER BY 操作效率低,需要额外操作
禁止使用数值作为 ENUM 的枚举值
4. 尽可能把所有列定义为 NOT NULL
原因:
索引 NULL 列需要额外的空间来保存,所以要占用更多的空间
进行比较和计算时要对 NULL 值做特别的处理
5. 使用 TIMESTAMP(4 个字节) 或 DATETIME 类型 (8 个字节) 存储时间
TIMESTAMP 存储的时间范围 1970-01-01 00:00:01 ~ 2038-01-19-03:14:07
TIMESTAMP 占用 4 字节和 INT 相同,但比 INT 可读性高
超出 TIMESTAMP 取值范围的使用 DATETIME 类型存储
经常会有人用字符串存储日期型的数据(不正确的做法)
- 缺点 1:无法用日期函数进行计算和比较
- 缺点 2:用字符串存储日期要占用更多的空间
6. 同财务相关的金额类数据必须使用 decimal 类型
- 非精准浮点:float,double
- 精准浮点:decimal
Decimal 类型为精准浮点数,在计算时不会丢失精度
占用空间由定义的宽度决定,每 4 个字节可以存储 9 位数字,并且小数点要占用一个字节
可用于存储比 bigint 更大的整型数据
关于存储引擎
MySQL使用插件式存储引擎,可根据应用场景选择最合适的存储引擎。
MySQL 5.5之前默认使用MyISAM,5.5之后默认使用Innodb。
-
查看当前使用的引擎[5.7]
show engines;
Innodb
- 行级锁,支持更高的并发
- 支持事务(ACID)
- 具有缓存功能,可缓存索引和数据,提高查询效率
- 支持在线热备份
【应用场景】
- 需要支持事务的业务(例如转账,付款)
- 高并发
- 数据读写及更新都比较频繁的场景,如:BBS,SNS,微博,微信等.
MyISAM存储引擎
- 不支持事务
- 只缓存索引,不缓存数据
- 表级锁,并发能力弱
- 服务器宕机,数据易损坏,且难恢复
MEMORY存储引擎
- 数据存放在内存中,懂得
- 表级锁,并发能力弱
数据类型选择
char与varchar
char:固定长度的字符串,浪费存储空间但速度快
varchar:可变长度的字符串。
使用Innodb存储引擎建议使用varchar
text和blob
避免使用,如果一定要使用,建议把 BLOB 或是 TEXT 列分离到单独的扩展表。
【MySQL 内存临时表不支持 TEXT、BLOB 这样的大数据类型,如果查询中包含这样的数据,在排序等操作时,就不能使用内存临时表,必须使用磁盘临时表进行。而且对于这种数据,MySQL 还是要进行二次查询,会使 sql 性能变得很差,但是不是说一定不能使用这样的数据类型。】
浮点数和定点数
插入数据的精度如果超过定义的精度,插入值会被四舍五入。【float,double】
定点数以字符串形式存放【decimal】
- 同财务相关的金额类数据必须使用 decimal 类型
日期类型选择
- DATETIME:记录年月日时分秒,表示的时间范围最大
- 如果记录的日期要让不同时区的人使用,使用TIMESTAMP
字符集——解决乱码问题
- 通常选用UTF-8
- 应用中涉及到已有数据的导入,考虑兼容性
- 只需要支持一般中文,数据量大,性能要求高,使用GBK(一个汉字占两个字节,UTF-8占三个字节)
- 如果应用主要处理英文字符,使用UTF-8