1、下载工具
两种渠道
a、官网(建议直接跳过~)
地址:http://www.tpc.org/tpc_documents_current_versions/current_specifications.asp
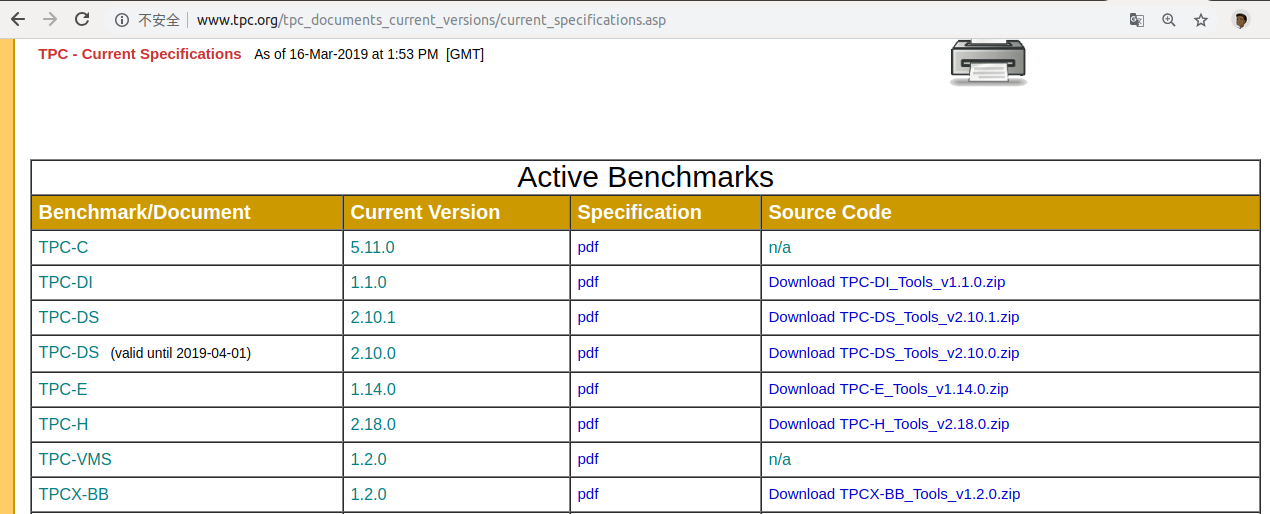
在信息填写正确的情况下,无法下载。看网友的解答,需要用谷歌浏览器才能下载。尝试未果。
b、github上下载
地址: https://github.com/gregrahn/tpcds-kit.git
ps:官方的包生成sql的时候会报错,上面这个大神已经修复。
2、编译
操作环境:Ubuntu 16.04
进入TPC-DS工具包所在目录,由于下载的是源码,需要编译后才能使用。
a、解压
unzip tpcds-kit-master.zip
b、编译
编译之前请确认依赖环境ok
ubuntu:
1 sudo apt-get install gcc make flex bison byacc git
CentOS/RHEL:
1 sudo yum install gcc make flex bison byacc git
tpcds-kit-master/tools make -f Makefile.suite
编译过程中报错:
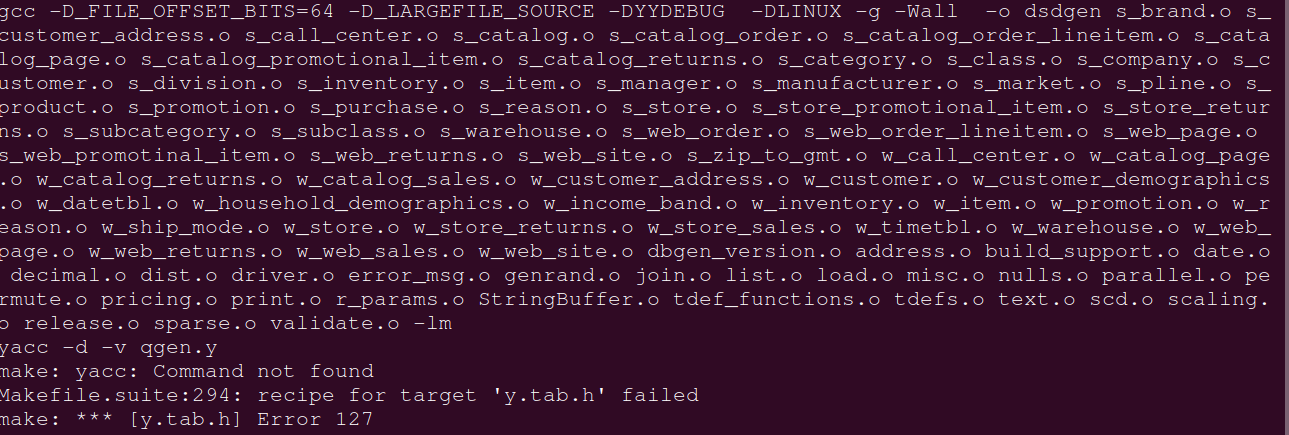
make: yacc: Command not found。报错是因为yacc没有安装 。
安装yacc
sudo apt-get install -y byacc
再次编译
又报错对‘yy_create_buffer’未定义的引用。对C/C++不熟悉,搜索了一下也没有相关的解答。百思不得其解之下,换了个思路。可能是第一次编译报错生成的错误文件对第二次编译产生的影响。
于是删除解压后的目录,重新编译成功。
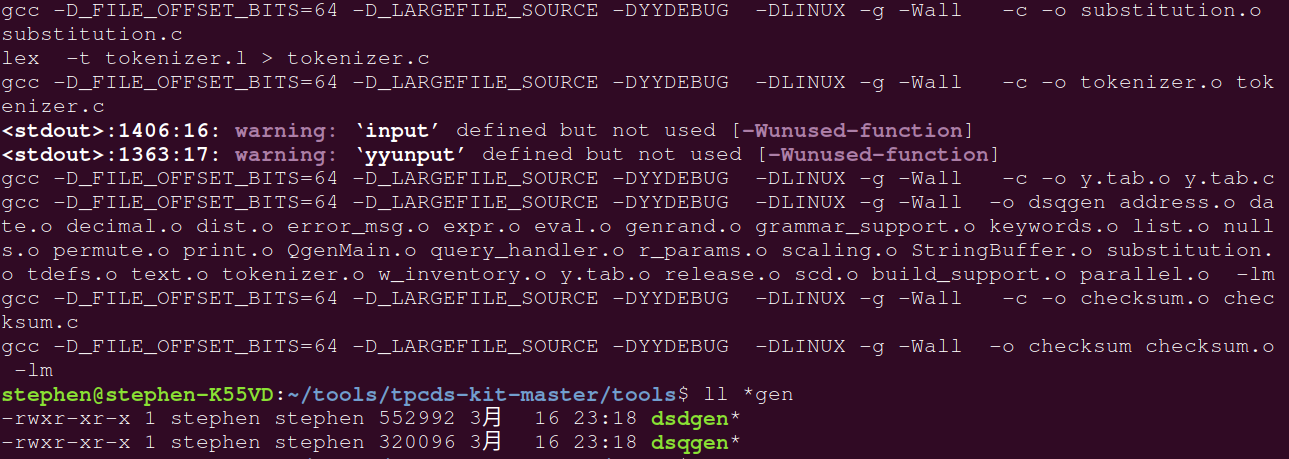
如果生成dsdgen和dsqgen且无报错,说明编译成功
ll *gen
3、生成数据
第一次使用这个工具我是一脸懵比的。因为官方的文档特喵的根本看不懂。回想一下,你碰到不熟悉的Linux命令是怎么做的?man或者--help,对吧。这里也可以用--help。
先不着急生成数据,看一下帮助信息先。
./dsdgen --help

- DIR:数据存放目录。
- SCALE:数据量,以GB为单位。
- TABLE:生成哪张表的数据,一共有24张表哦。
- PARALLEL:生成的数据一共分为多少份,一般生成TB级数据才会用到。
- CHILD:当前数据是第几份,与PARALLEL配对使用。
- FORCE:强制写入数据。
常用的参数就上面几个。下面我们来生成1G包含所有表的数据。
./dsdgen -scale 1 -dir ../data/

等待dsdgen程序正常退出后,1G数据需要2~3min左右,进入data目录查看生成的数据。
cd ../data

假如只想生成其中某一张表的数据呢?这就需要用到-table参数了,以web_returns表为例。
./dsdgen -scale 1 -dir ../data -table web_returns
报错了,信息如下:

web_returns是子表,它是依赖于父表web_sales的。生成父表的时候也会同时生成子表,我们来验证一下。
./dsdgen -scale 1 -dir ../data -table web_sales

说明一下,最终生成的数据量以少于scale值的。
dsdgen的用法暂时先总结到这里。
4、生成SQL
查询SQL使用dsqgen生成,主要用于测试数据仓库的性能,一共99个。详细用法可以用--help查看帮助信息。这里不做介绍直接生成。
./dsqgen -DIRECTORY ../query_templates/ -TEMPLATE "query1.tpl" -DIALECT netezza -FILTER Y > ../sql/query1.sql
-
-DIRECTORY:SQL模板的路径
-
-TEMPLATE:SQL模板的名称
-
-DIALECT:include query dialect defintions found in <s>.tpl
-
-FILTER:重定向到标准输出。
查看生成的SQL:

一共有99,每一个都要这样生成多费劲呀。来写个for循环一把生成所有的SQL。
shell版:
#!/bin/sh
for i in `seq 1 99`
do
./dsqgen -DIRECTORY ../query_templates/ -TEMPLATE "query${i}.tpl" -DIALECT netezza -FILTER Y > ../sql/query${i}.sql
done
Python3版:
#coding:utf-8
import os
print("generate query sql")
for i in range(1,100):
tpl = "query"+str(i)+".tpl"
qsql = "query" +str(i) +".sql"
#拼接命令
cmd = "./dsqgen -DIRECTORY ../query_templates/ "+"-TEMPLATE "+tpl+" -DIALECT netezza -FILTER Y > "+"../sql/"+qsql
#print(cmd)
#执行命令
os.system(cmd)
去sql目录下查看刚才生成的SQL:
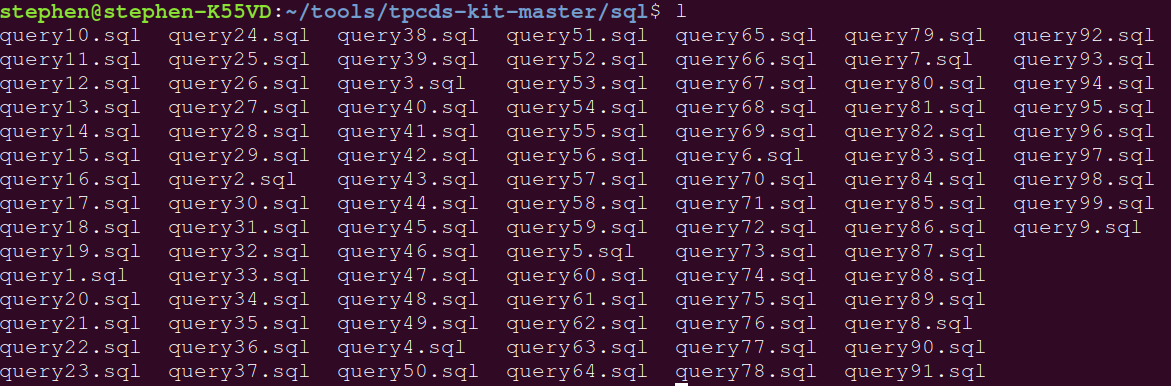
这种情况下还是shell更快一点。
5、总结
- 通过TPC-DS,可以生成指定量级的数据。
- 碰到报错不要慌,先google或bing,不要用某度,原因你懂的。
- TPC-DS基本用法已经总结完了,但是实际操作中还有很多问题,比如:
- 我想要生成10T数据怎么搞?
- 怎么判断生成的数据是否正确呢?
- child和parallel怎么使用?
- 数据和SQL生成完了怎么测试?
- 。。。。。。