原始数据为Excel文件,由传感器获得,通过Pyhton xlrd模块读入,读入后为数组形式,由于其存在部分异常值和缺失值,所以便利用Numpy对其中的异常值进行替换或条件替换。 1. 将'nan'替换
原始数据为Excel文件,由传感器获得,通过Pyhton xlrd模块读入,读入后为数组形式,由于其存在部分异常值和缺失值,所以便利用Numpy对其中的异常值进行替换或条件替换。
1. 将'nan'替换为给定值
import numpy as np
data = np.array([['nan', 1, 2, 3, 4], # 数据类型为字符串型
[10, 15, 20, 25, 'nan'],
['nan', 5, 8, 10, 20]])
print(data)
# [['nan' '1' '2' '3' '4']
# ['10' '15' '20' '25' 'nan']
# ['nan' '5' '8' '10' '20']]
data[data == 'nan'] = 100 # 将numpy中为'nan'的项替换为 100
print(data)
# [['100' '1' '2' '3' '4']
# ['10' '15' '20' '25' '100']
# ['100' '5' '8' '10' '20']]
data = data.astype(float) # 将数据由字符型转换为浮点型
print(data)
# [[100. 1. 2. 3. 4.]
# [ 10. 15. 20. 25. 100.]
# [100. 5. 8. 10. 20.]]
2. 按列进行条件替换
当利用'3σ准则'或者箱型图进行异常值判断时,通常需要对 > upper 或 < lower的值进行处理,这时就需要按列进行条件替换了。
print(data) # [[100. 1. 2. 3. 4.] # [ 10. 15. 20. 25. 100.] # [100. 5. 8. 10. 20.]] data[:, 1][data[:, 1] < 5] = 5 # 对第2列小于 5 的替换为5 print(data) # [[100. 5. 2. 3. 4.] # [ 10. 15. 20. 25. 100.] # [100. 5. 8. 10. 20.]] data[:, 2][data[:, 2] > 15] = 10 # 对第3列大于 15 的替换为10 print(data) # [[100. 5. 2. 3. 4.] # [ 10. 15. 10. 25. 100.] # [100. 5. 8. 10. 20.]]
补充知识:Python之dataframe修改异常值—按行判断值是否大于平均值的指定倍数,如果是则用均值替换
如下所示:
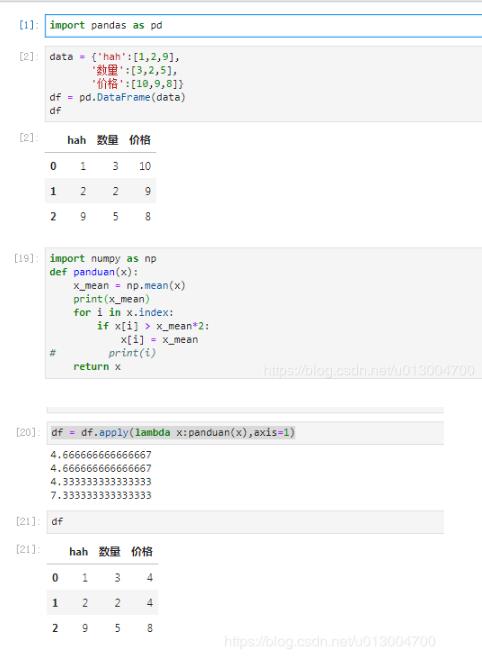
import pandas as pd
data = {'hah':[1,2,9],
'数量':[3,2,5],
'价格':[10,9,8]}
df = pd.DataFrame(data)
df
import numpy as np
def panduan(x):
x_mean = np.mean(x)
print(x_mean)
for i in x.index:
if x[i] > x_mean*2:
x[i] = x_mean
# print(i)
return x
df = df.apply(lambda x:panduan(x),axis=1)
以上这篇使用Numpy对特征中的异常值进行替换及条件替换方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持易盾网络。