这两天在测试过程中,遇到这样的问题: 数据量很大,一份csv文件的数据与另外一个文件的数据进行对比,但是csv中的文件数据量很大,并且进行统计 ,如果手动单个去对比,会很花
这两天在测试过程中,遇到这样的问题:
数据量很大,一份csv文件的数据与另外一个文件的数据进行对比,但是csv中的文件数据量很大,并且进行统计 ,如果手动单个去对比,会很花时间,吃力不讨好,还容易出错。
比如说,这样的数据
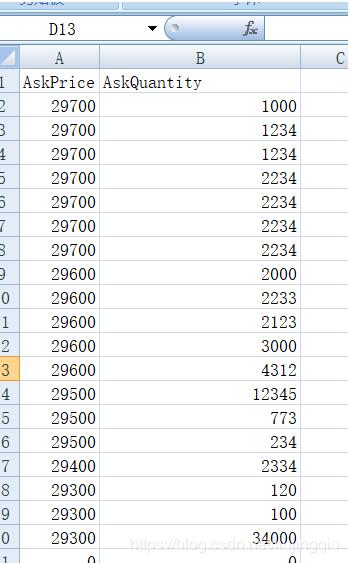
需要对AskPrice值相同对应的AskQuantity 统计出来。
直接上脚本 :
import pandas as pd
import csv
df=pd.read_csv('D:\test\orderBook.csv')
df_sum = df.groupby('AskPrice')['AskQuantity'].sum()
df_sum.to_csv('D:\test\orderBook2.csv')
然后运行得到:
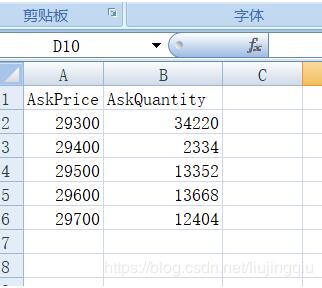
这对于大数据量的处理特别方便。
补充知识:python处理csv文件(场景分类)
最近做一个关于场景分类的比赛,总共有20类,不到2万张图片,首先要做的就是把20类图片分到每个文件夹下。
import numpy as np
import os
import xlrd
import pandas as pd
import shutil
list_0 = []
list_file = []
flag = []
filename = os.listdir('F:\工作\比赛\未来杯\image_scene_training\data')
af = pd.read_excel('19.xlsx')
ww = af.values.tolist()
for i in ww:
for j in i:
list_0.append(j)
for name in filename:
list_file.append(name[0:-4])
for name in list_file:
if name in list_0:
flag.append(True)
else:
flag.append(False)
for name in list_file:
if flag[list_file.index(name)]:
oldname = u'F:\工作\比赛\未来杯\image_scene_training\data\\'+name+'.jpg'
newname = u'F:\工作\比赛\未来杯\image_scene_training\\train_data\\beach\\'+name+'.jpg'
shutil.copyfile(oldname,newname)
unicodeDecodeError:'utf-8' codec can't decode byte 0xce in position 72: invalid continuation byte
1:升级pip python -m pip install --upgrade pip
2:改python文件内容:找到lib\site-packages\pip\compat\__init__.py
return s.decode('utf-8')
将‘utf-8'改成'gbk'
以上这篇python 实现读取csv数据,分类求和 再写进 csv就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持易盾网络。