编程的生活愈发不容易了,工作越来越难找,说多了都是泪还是给大家贡献些代码比较实际。
python3 链接数据库需要下载名为pymysql的第三方库
python3 读写xlsx需要下载名为openpyxl的第三方库
在此我只贡献链接数据库和写入xlsx的代码
import pymysql.cursors
from fj.util import logger
from openpyxl import Workbook
from openpyxl.compat import range
from openpyxl.utils import get_column_letter
# 链接数据库的游标
connect = pymysql.Connect(
host="localhost",
port=3306,
user='root',
passwd='123456',
db='zyDB',
charset='utf8',
)
cursor = connect.cursor()
# 关闭数据库链接操作
def clos_cursor():
return cursor.close();
# 读取数据库数据
def query_all():
select_sql = "select*from fj_date where fj_id not in" \
"( select a.fj_id from ( select * from fj_date where mj_id>0 ) a " \
"join ( SELECT * from fj_date where jb_id>0 ) b" \
" on a.fjzz = b.fjzz and a.fj_add=b.fj_add) and mj_id>0"
cursor.execute(select_sql);
return cursor.fetchall();
# 关闭数据库链接操作
def clos_cursor():
cursor.close();
connect.close()
def read_mysql_to_xlsx():
#要创建的xlsx名称
dest_filename = 'jb_data.xlsx'
wb = Workbook()
ws1 = wb.active
ws1.title = "fj_date"
# 列名
ws1.cell(row=1,column=1,value="fj_id(数据库编号)")
ws1.cell(row=1,column=2,value="jb_id(疾病编号)")
ws1.cell(row=1,column=3,value="mj_id(名医编号)")
ws1.cell(row=1,column=4,value="fj_name(方剂名称)")
ws1.cell(row=1,column=5,value="fjcc(出处)")
ws1.cell(row=1,column=6,value="fjdm(代码)")
ws1.cell(row=1,column=7,value="fjzc(加减)")
ws1.cell(row=1,column=8,value="fjgx(功效)")
ws1.cell(row=1,column=9,value="fj_add(组成)")
ws1.cell(row=1,column=10,value="fjjj(禁忌)")
ws1.cell(row=1,column=11,value="fjzy(方剂治验)")
ws1.cell(row=1,column=12,value="fjzz(主治)")
ws1.cell(row=1,column=13,value="fjyf(用法)")
ws1.cell(row=1,column=14,value="ylzy(药理作用)")
ws1.cell(row=1,column=15,value="gjls(各家论述)")
ws1.cell(row=1,column=16,value="fj(方解)")
ws1.cell(row=1,column=17,value="ks(科室)")
ws1.cell(row=1,column=18,value="ckzl(参考资料)")
ws1.cell(row=1,column=19,value="lcyy(临床应用)")
ws1.cell(row=1,column=20,value="tjbq(推荐标签)")
ws1.cell(row=1,column=21,value="zysx(注意事项)")
ws1.cell(row=1,column=22,value="fjzb(制备方法)")
ws1.cell(row=1,column=23,value="fg(方歌)")
ws1.cell(row=1,column=24,value="path(路径)")
# 循环数据写入内容
jb_date_list = query_all()
for i in range(2,len(jb_date_list)+1):
ws1.cell(row=i, column=1, value=jb_date_list[i-1][0])
ws1.cell(row=i, column=2, value=jb_date_list[i-1][1])
ws1.cell(row=i, column=3, value=jb_date_list[i-1][2])
ws1.cell(row=i, column=4, value=jb_date_list[i-1][3])
ws1.cell(row=i, column=5, value=jb_date_list[i-1][4])
ws1.cell(row=i, column=6, value=jb_date_list[i-1][5])
ws1.cell(row=i, column=7, value=jb_date_list[i-1][6])
ws1.cell(row=i, column=8, value=jb_date_list[i-1][7])
ws1.cell(row=i, column=9, value=jb_date_list[i-1][8])
ws1.cell(row=i, column=10, value=jb_date_list[i-1][9])
ws1.cell(row=i, column=11, value=jb_date_list[i-1][10])
ws1.cell(row=i, column=12, value=jb_date_list[i-1][11])
ws1.cell(row=i, column=13, value=jb_date_list[i-1][12])
ws1.cell(row=i, column=14, value=jb_date_list[i-1][13])
ws1.cell(row=i, column=15, value=jb_date_list[i-1][14])
ws1.cell(row=i, column=16, value=jb_date_list[i-1][15])
ws1.cell(row=i, column=17, value=jb_date_list[i-1][16])
ws1.cell(row=i, column=18, value=jb_date_list[i-1][17])
ws1.cell(row=i, column=19, value=jb_date_list[i-1][18])
ws1.cell(row=i, column=20, value=jb_date_list[i-1][19])
ws1.cell(row=i, column=21, value=jb_date_list[i-1][20])
ws1.cell(row=i, column=22, value=jb_date_list[i-1][21])
ws1.cell(row=i, column=23, value=jb_date_list[i-1][22])
ws1.cell(row=i, column=24, value=jb_date_list[i-1][23])
# 创建xlsx
wb.save(filename=dest_filename)
if __name__ == '__main__':
read_mysql_to_xlsx()
补充知识:Python 关闭文件释放内存的疑惑
我用with语句打开了一个4g的文件读取内容,然后程序末尾设置一个死循环,按理说with语句不是应该自动关闭文件释放资源吗?
但是系统内存一直没有释放。应该是被文件读取到的变量content一直占用吗?把content删除就会释放内存。或者去掉死循环,程序退出资源就自动释放了
既然这样的话关闭文件貌似没啥作用呢?具体释放了什么资源?
Python一直占用着将近5G的内存:
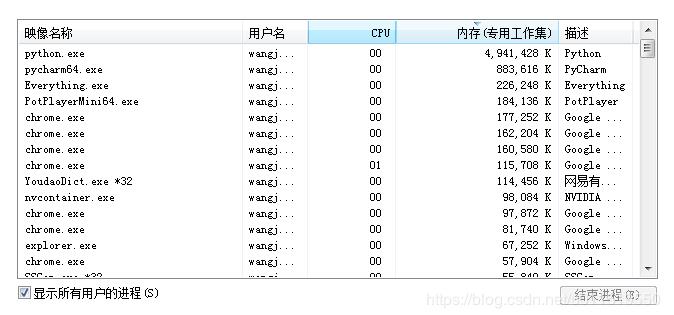
官方文档:
If you're not using the with keyword, then you should call f.close() to close the file and immediately free up any system resources used by it. If you don't explicitly close a file, Python's garbage collector will eventually destroy the object and close the open file for you, but the file may stay open for a while. Another risk is that different Python implementations will do this clean-up at different times.
After a file object is closed, either by a with statement or by calling f.close(), attempts to use the file object will automatically fail.
代码如下:
import sys with open(r'H:\BaiduNetdiskDownload\4K.mp4','rb') as f: print(f.closed) content=f.read() print(f.closed) print(sys.getrefcount(f)) while True: pass
以上这篇python3 使用openpyxl将mysql数据写入xlsx的操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持易盾网络。