此操作目的是为了制作自己的数据集,深度学习框架进行数据准备,此操作步骤包括对文件夹进行操作,将两个文件夹合并至另一个文件夹 该实例为一个煤矿工人脸识别的案例;首先原
此操作目的是为了制作自己的数据集,深度学习框架进行数据准备,此操作步骤包括对文件夹进行操作,将两个文件夹合并至另一个文件夹
该实例为一个煤矿工人脸识别的案例;首先原始数据集(简化版的数据集旨在说明数据准备过程)如下图所示:
该数据集只有三个人的数据,A01代表工人甲的煤矿下的照片,B01代表工人甲下矿前的照片,同理A02、B02代表工人乙的矿下、矿上的照片数据。。。
如下图所示
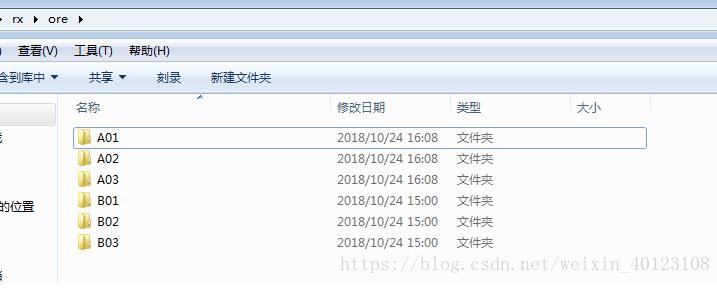
矿下
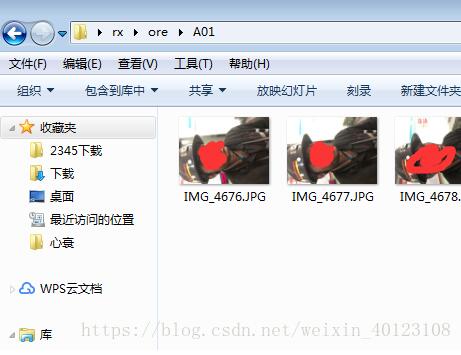
矿上
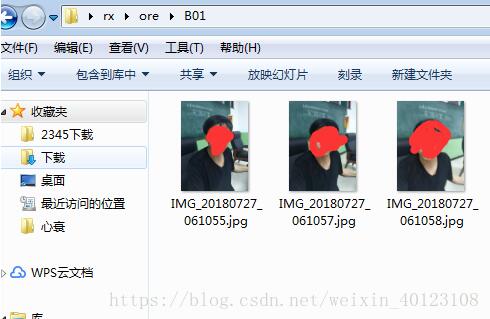
开始制作数据集:
首先建立训练集(0.7)和测试集(0.3),即建立一个空白文件夹
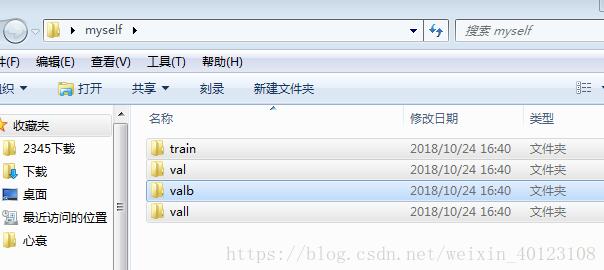
将该文件夹分为四个小文件夹(空),train代表训练集,val代表测试集,valb代表矿井下的测试集,vall代表矿井上的测试集,注:后边两个测试集可有可无
最终制作的数据集如下所示:
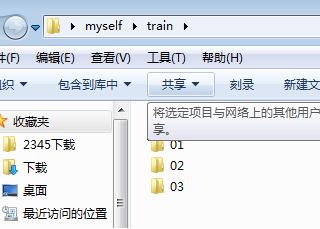
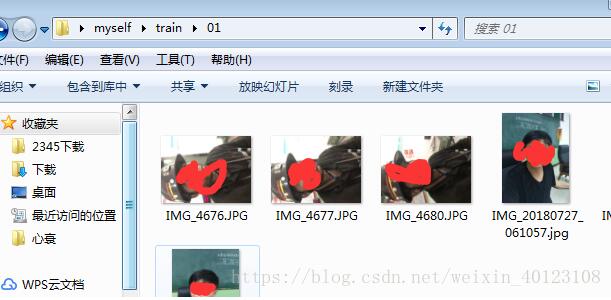
下面为所有的程序详解
#导入一些进行该操作需要的库 import numpy as np import os import random import shutil path=r'C:\Users\Administrator.SKY-20180518VHY\Desktop\rx\ore'#原始数据集的路径 data=os.listdir(path) #listdir该操作([添加链接描述](https://www.jb51.net/article/184106.htm))在我的上篇文章中有所介绍,此操作能读取的内容为A01、A02、A03、B01、B02、B03这些文件夹 #print(data) root=path#复制原始数据路径path
读取文件夹 A01、A02、A03、存入c列表中B01、B02、B03,将其存入d列表中
c=[] d=[]#创建两个空列表 for i in range(len(data)): a=data[i][0] if (a=='A'): c.append(data[i]) else: d.append(data[i]) #print(d)

导入路径四个空文件夹的路径
train_root='C:\\Users\\Administrator.SKY-20180518VHY\\Desktop\\myself\\train'
val_root='C:\\Users\\Administrator.SKY-20180518VHY\\Desktop\\myself\\val'
vall_root='C:\\Users\\Administrator.SKY-20180518VHY\\Desktop\\myself\\valb'
valb_root='C:\\Users\\Administrator.SKY-20180518VHY\\Desktop\\myself\\vall'
for i in range(len(c)):
qqq=os.path.exists(train_root+'/'+c[i][1:])
if (not qqq):
os.mkdir(train_root+'/'+c[i][1:])
qq=os.path.exists(val_root+'/'+c[i][1:])
if (not qq):
os.mkdir(val_root+'/'+c[i][1:])
qq=os.path.exists(vall_root+'/'+c[i][1:])
if (not qq):
os.mkdir(vall_root+'/'+c[i][1:])
qq=os.path.exists(valb_root+'/'+c[i][1:])
if (not qq):
os.mkdir(valb_root+'/'+c[i][1:])
#f=[]
#g=[]
aq='C:\\Users\\Administrator.SKY-20180518VHY\\Desktop\\rx\\ore\\'
train_root1='C:\\Users\\Administrator.SKY-20180518VHY\\Desktop\\myself\\train\\'
val_root1='C:\\Users\\Administrator.SKY-20180518VHY\\Desktop\\myself\\val\\'
vall_root1='C:\\Users\\Administrator.SKY-20180518VHY\\Desktop\\myself\\valb\\'
valb_root1='C:\\Users\\Administrator.SKY-20180518VHY\\Desktop\\myself\\vall\\'
for i in range(len(c)):
a=c[i]
data_0=os.listdir(aq+a)
# f.append(data_0)
# g.append(aq+a)
#print(f)
#print(g)
random.shuffle(data_0)#打乱A中数据
for j in range(len(d)):
b=d[j]
if(a[1:]==b[1:]):
data_1=os.listdir(aq+b)
#print(aq+b);
random.shuffle(data_1)
#print(data_1)
#print(data_0,data_1)
for z in range(len(data_0)):
#print(z)
pic_path=aq+a+'/'+data_0[z]
if z<int(len(data_0)*0.7):
obj_path=train_root1+a[1:]+'/'+data_0[z]
else:
obj_path=val_root1+a[1:]+'/'+data_0[z]
obl_path=vall_root1+a[1:]+'/'+data_0[z]
shutil.copyfile(pic_path,obl_path)
#print(len(data_0),len(data_0)*0.7)
#if (os.path.exists(pic_path)):
shutil.copyfile(pic_path,obj_path)
for z in range(len(data_1)):
pic_path=aq+b+'/'+data_1[z]
if z<int(len(data_1)*0.7):
obj_path=train_root1+b[1:]+'/'+data_1[z]
else:
obj_path=val_root1+b[1:]+'/'+data_1[z]
obl_path=valb_root1+a[1:]+'/'+data_1[z]
shutil.copyfile(pic_path,obl_path)
#if (os.path.exists(pic_path)):
shutil.copyfile(pic_path,obj_path)#shutil.copyfile( src, dst)
从源src复制到dst中去。当然前提是目标地址是具备可写权限。抛出的异常信息为IOException. 如果当前的dst已存在的话就会被覆盖掉
将数据送入pytorch中,对数据进行迭代
from __future__ import print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy
import math
import torch.nn.functional as F
D=299
data_transforms = {
'train': transforms.Compose([
# transforms.RandomResizedCrop(D),
transforms.Resize(D),
transforms.RandomCrop(D),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(D),
transforms.CenterCrop(D),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
data_dir = r'C:\Users\Administrator.SKY-20180518VHY\Desktop\myself'
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train', 'val']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=200,
shuffle=True, num_workers=4)
for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#print(image_datasets['train'][0])
img, label = image_datasets['val'][11]
print(label)#输出为2即第三类
以上这篇python实现将两个文件夹合并至另一个文件夹(制作数据集)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持易盾网络。