OCR简介
OCR,即Optical Character Recognition,光学字符识别,是指通过扫描字符,然后通过其形状将其翻译成电子文本的过程,对应图形验证码来说,它们都是一些不规则的字符,这些字符是由字符稍加扭曲变换得到的内容,我们可以使用OCR技术来讲其转化为电子文本,然后将结果提取交给服务器,便可以达到自动识别验证码的过程。
window环境
环境材料准备
- Window10
- Python-3.7.3.tgz
- tesserocr安装包
安装tesserocr
1、打开链接,https://digi.bib.uni-mannheim.de/tesseract/,见下图。
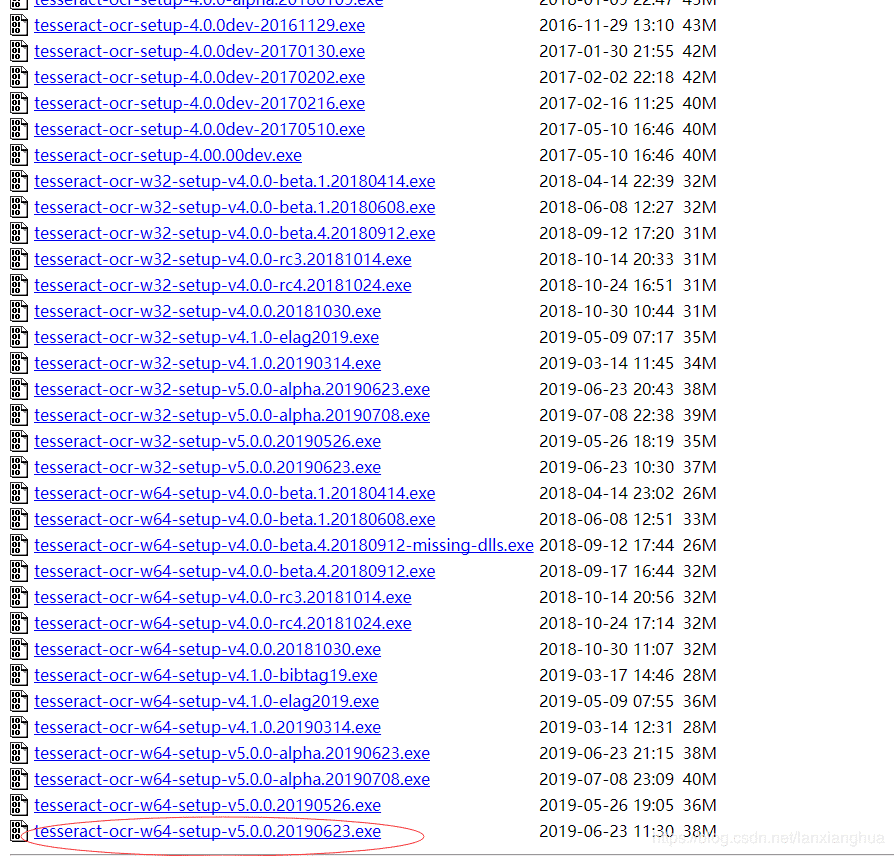
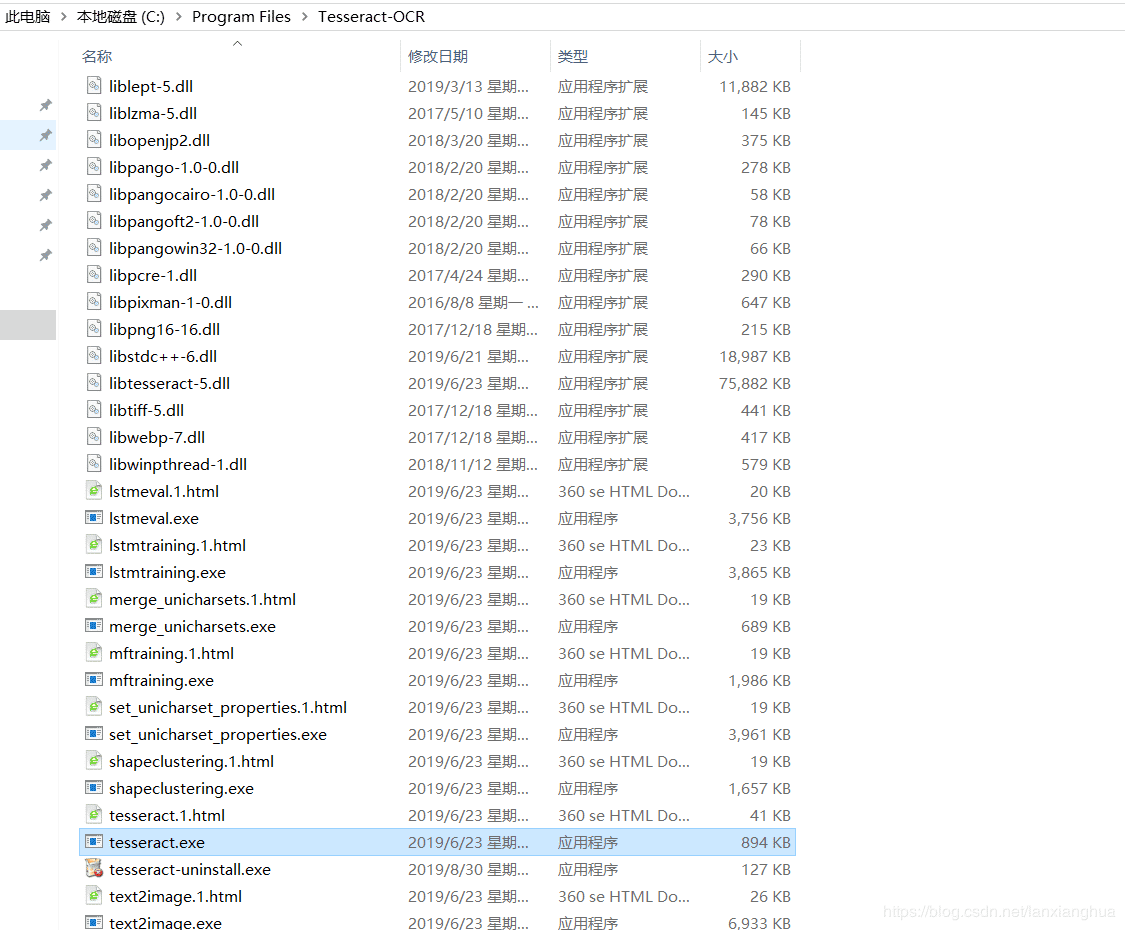
下载最新版的tesseract-ocr-w64-setup-v5.0.0.20190623.exe,然后安装,本人直接安装在C盘目录下。安装完毕后,如下图。
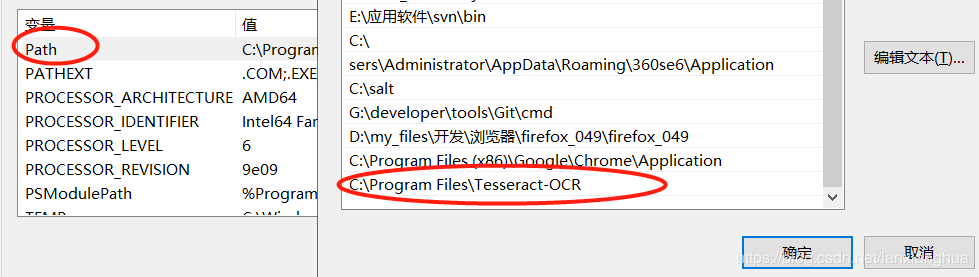
配置环境变量,有两个步骤。
在系统变量里,修改path,如下图。
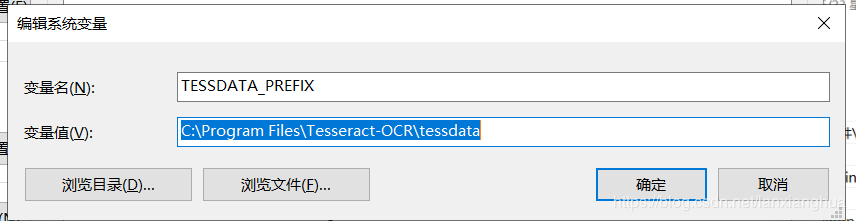
在系统变量里,创建一个新的变量名为:TESSDATA_PREFIX,值为:C:\Program Files\Tesseract-OCR\tessdata(根据自己安装的tesserocr安装路径为准),如下图。
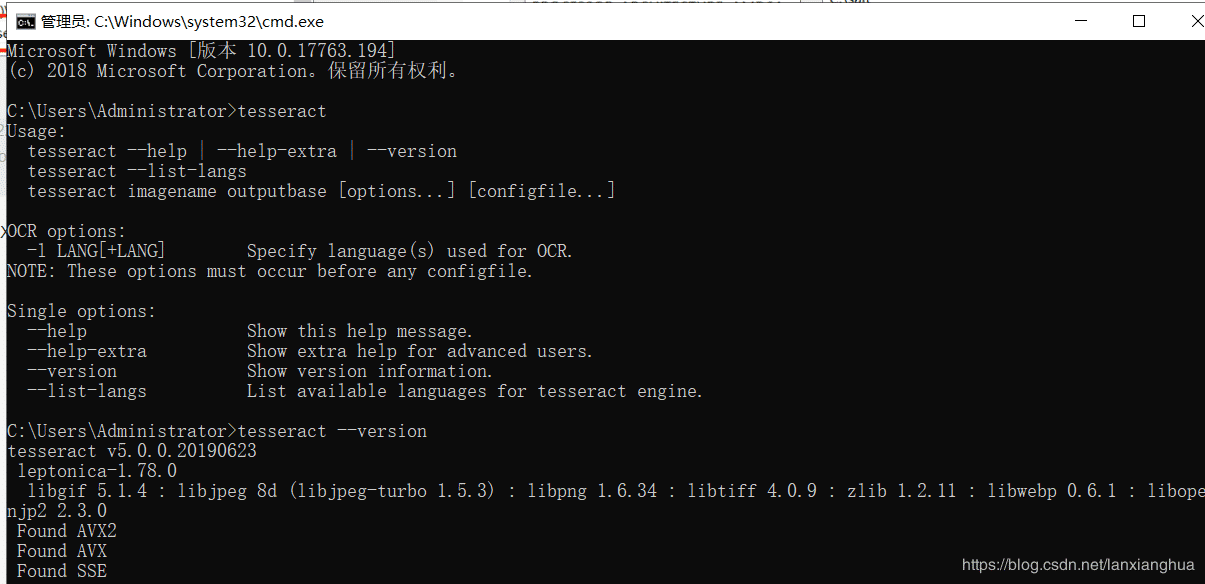
检查Tesseract-OCR是否安装完成,如下图。
Python3.7加载tesserocr
1、安装Python的OCR识别库
pip install Pillow
pip install pytesseract
2、python加载Window的tesserocr应用,要修改pytesseract三方库的pytesseract.py脚本。
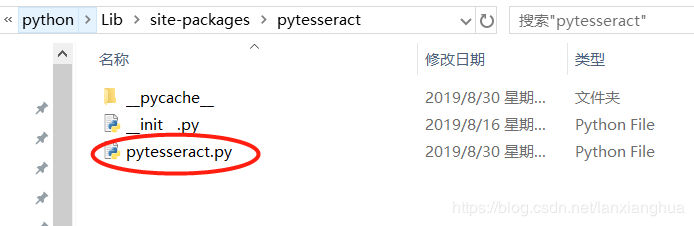
打开pytesseract.py,将Window的tesserocr应用的tesserocr.exe绑定好。
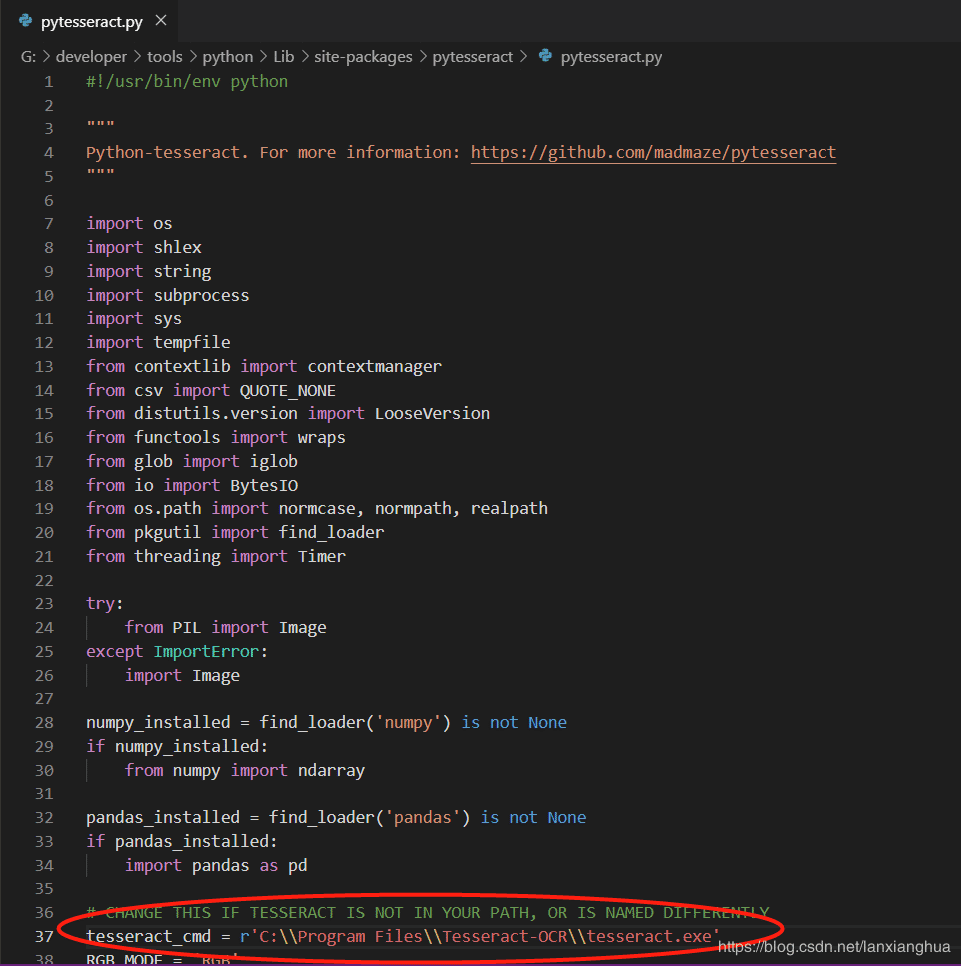
3、到这里Python的绑定window的tesserocr应用已经完成。
读取验证码图片
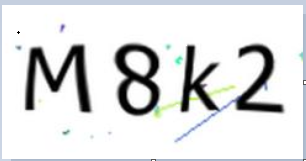
from PIL import Image
import pytesseract
def read_text(text_path):
"""
传入文本(jpg、png)的绝对路径,读取文本
:param text_path:
:return: 文本内容
"""
# 验证码图片转字符串
im = Image.open(text_path)
# 转化为8bit的黑白图片
imgry = im.convert('L')
# 二值化,采用阈值分割算法,threshold为分割点
threshold = 140
table = []
for j in range(256):
if j < threshold:
table.append(0)
else:
table.append(1)
out = imgry.point(table, '1')
# 识别文本
text = pytesseract.image_to_string(out, lang="eng", config='--psm 6')
return text
if __name__ == '__main__':
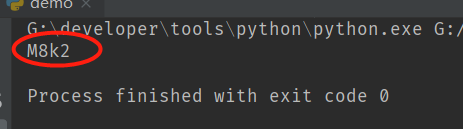
print(read_text("d://v3.png"))
输出:
读取中文文本图片
1、因为OCR读取不同语言需要加载语言包,因此需要下载简体中文语言包。
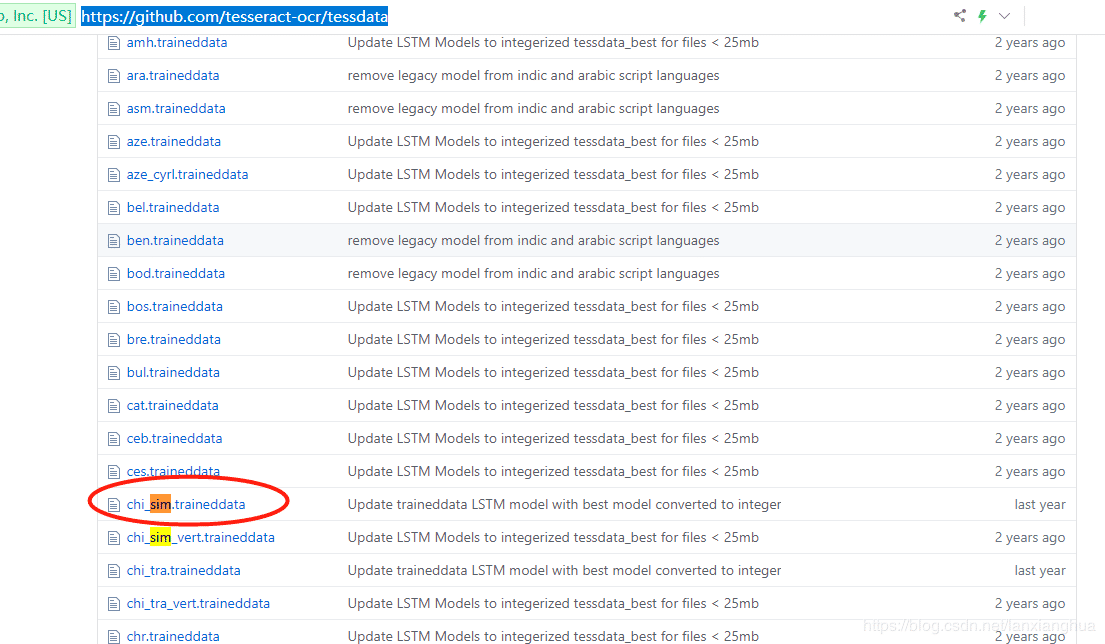
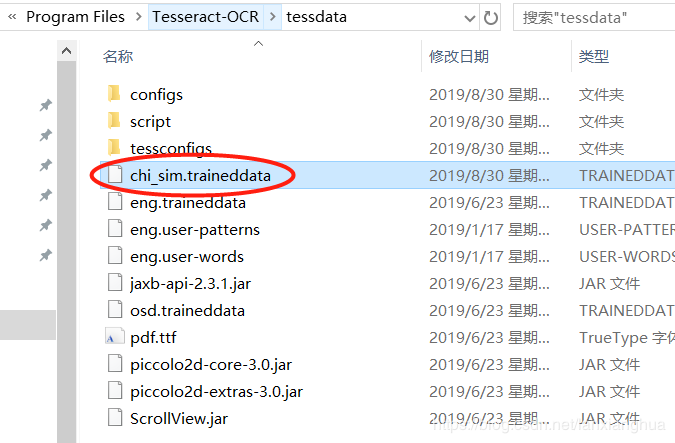
从这个链接下载:https://github.com/tesseract-ocr/tessdata,下载红圈的简体中文包。然后将此文件放置window的安装目录下。如下两个图。
现在,我们来读取如下图片的中文文本内容。

代码如下:
from PIL import Image
import pytesseract
def read_text(text_path):
"""
传入文本(jpg、png)的绝对路径,读取文本
:param text_path:
:return: 文本内容
"""
# 验证码图片转字符串
im = Image.open(text_path)
# 转化为8bit的黑白图片
imgry = im.convert('L')
# 二值化,采用阈值分割算法,threshold为分割点
threshold = 140
table = []
for j in range(256):
if j < threshold:
table.append(0)
else:
table.append(1)
out = imgry.point(table, '1')
# 识别文本,lang参数改为chi_sim,其他代码与上面的读取验证码代码一致。
text = pytesseract.image_to_string(out, lang="chi_sim", config='--psm 6')
return text
if __name__ == '__main__':
print(read_text("d://v7.png"))

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持易盾网络。