最小二乘法Least Square Method,做为分类回归算法的基础,有着悠久的历史(由马里·勒让德于1806年提出)。它通过最小化误差的平方和寻找数据的最佳函数匹配。利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小。最小二乘法还可用于曲线拟合。其他一些优化问题也可通过最小化能量或最大化熵用最小二乘法来表达。
那什么是最小二乘法呢?别着急,我们先从几个简单的概念说起。
假设我们现在有一系列的数据点 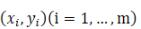 ,那么由我们给出的拟合函数h(x)得到的估计量就是
,那么由我们给出的拟合函数h(x)得到的估计量就是 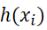 ,那么怎么评估我们给出的拟合函数与实际待求解的函数的拟合程度比较高呢?这里我们先定义一个概念:残差
,那么怎么评估我们给出的拟合函数与实际待求解的函数的拟合程度比较高呢?这里我们先定义一个概念:残差 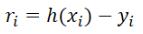 , 我们估计拟合程度都是在残差的基础上进行的。下面再介绍三种范数:
, 我们估计拟合程度都是在残差的基础上进行的。下面再介绍三种范数:
• ∞-范数:残差绝对值的最大值 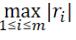 ,即所有数据点中残差距离的最大值
,即所有数据点中残差距离的最大值
• 1-范数:绝对残差和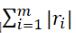 ,即所有数据点残差距离之和
,即所有数据点残差距离之和
• 2-范数:残差平方和 
前两种范数是最容易想到,最自然的,但是不利于进行微分运算,在数据量很大的情况下计算量太大,不具有可操作性。因此一般使用的是2-范数。
说了这么多,那范数和拟合有什么关系呢?拟合程度,用通俗的话来讲,就是我们的拟合函数h(x)与待求解的函数y之间的相似性。那么2-范数越小,自然相似性就比较高了。
由此,我们可以写出最小二乘法的定义了:
对于给定的数据 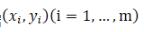 ,在取定的假设空间H中,求解h(x)∈H,使得残差
,在取定的假设空间H中,求解h(x)∈H,使得残差 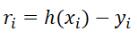 的2-范数最小,即
的2-范数最小,即
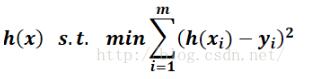
从几何上讲,就是寻找与给定点 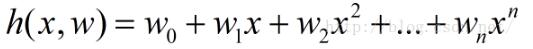 距离平方和最小的曲线y=h(x)。h(x)称为拟合函数或者最小二乘解,求解拟合函数h(x)的方法称为曲线拟合的最小二乘法。
距离平方和最小的曲线y=h(x)。h(x)称为拟合函数或者最小二乘解,求解拟合函数h(x)的方法称为曲线拟合的最小二乘法。
那么这里的h(x)到底应该长什么样呢?一般情况下,这是一条多项式曲线:
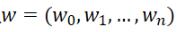
这里h(x,w)是一个n次多项式,w是其参数。
也就是说,最小二乘法就是要找到这样一组  ,使得
,使得 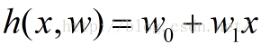 最小。
最小。
那么如何找到这样的w,使得其拟合函数h(x)与目标函数y具有最高拟合程度呢?即最小二乘法如何求解呢,这才是关键啊。
假设我们的拟合函数是一个线性函数,即:
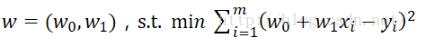
(当然,也可以是二次函数,或者更高维的函数,这里仅仅是作为求解范例,所以采用了最简单的线性函数)那么我们的目标就是找到这样的w,
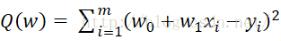
这里令 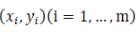 为样本
为样本 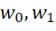 的平方损失函数
的平方损失函数
这里的Q(w)即为我们要进行最优化的风险函数。
学过微积分的同学应该比较清楚,这是一个典型的求解极值的问题,只需要分别对 18 求偏导数,然后令偏导数为0,即可求解出极值点,即:
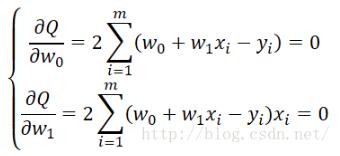
接下来只需要求解这个方程组即可解出w_i 的值
============ 分割分割 =============
上面我们讲解了什么是最小二乘法,以及如何求解最小二乘解,下面我们将通过Python来实现最小二乘法。
这里我们把目标函数选为y=sin(2πx),叠加上一个正态分布作为噪音干扰,然后使用多项式分布去拟合它。
代码:
# _*_ coding: utf-8 _*_ # 作者: yhao # 博客: http://blog.csdn.net/yhao2014 # 邮箱: yanhao07@sina.com import numpy as np # 引入numpy import scipy as sp import pylab as pl from scipy.optimize import leastsq # 引入最小二乘函数 n = 9 # 多项式次数 # 目标函数 def real_func(x): return np.sin(2 * np.pi * x) # 多项式函数 def fit_func(p, x): f = np.poly1d(p) return f(x) # 残差函数 def residuals_func(p, y, x): ret = fit_func(p, x) - y return ret x = np.linspace(0, 1, 9) # 随机选择9个点作为x x_points = np.linspace(0, 1, 1000) # 画图时需要的连续点 y0 = real_func(x) # 目标函数 y1 = [np.random.normal(0, 0.1) + y for y in y0] # 添加正太分布噪声后的函数 p_init = np.random.randn(n) # 随机初始化多项式参数 plsq = leastsq(residuals_func, p_init, args=(y1, x)) print 'Fitting Parameters: ', plsq[0] # 输出拟合参数 pl.plot(x_points, real_func(x_points), label='real') pl.plot(x_points, fit_func(plsq[0], x_points), label='fitted curve') pl.plot(x, y1, 'bo', label='with noise') pl.legend() pl.show()
输出拟合参数:

图像如下:

从图像上看,很明显我们的拟合函数过拟合了,下面我们尝试在风险函数的基础上加上正则化项,来降低过拟合的现象:
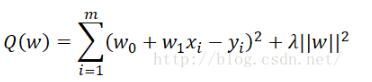
为此,我们只需要在残差函数中将lambda^(1/2)p加在了返回的array的后面
regularization = 0.1 # 正则化系数lambda # 残差函数 def residuals_func(p, y, x): ret = fit_func(p, x) - y ret = np.append(ret, np.sqrt(regularization) * p) # 将lambda^(1/2)p加在了返回的array的后面 return ret
输出拟合参数:

图像如下:
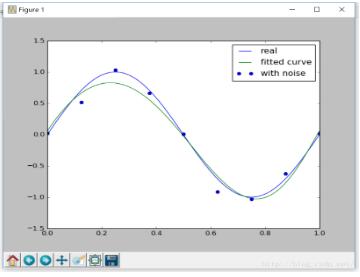
很明显,在适当的正则化约束下,可以比较好的拟合目标函数。
注意,如果正则化项的系数太大,会导致欠拟合现象(此时的惩罚项权重特别高)
如,设置regularization=0.1时,图像如下:
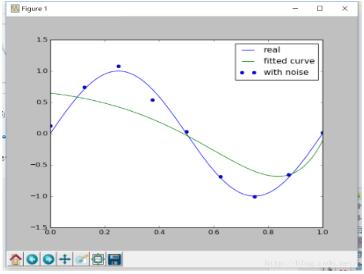
此时明显欠拟合。所以要慎重进行正则化参数的选择。
以上这篇最小二乘法及其python实现详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持易盾网络。