本文实例为大家分享了pytorch实现MNIST手写体识别的具体代码,供大家参考,具体内容如下 实验环境 pytorch 1.4 Windows 10 python 3.7 cuda 10.1(我笔记本上没有可以使用cuda的显卡) 实验过程
本文实例为大家分享了pytorch实现MNIST手写体识别的具体代码,供大家参考,具体内容如下
实验环境
pytorch 1.4
Windows 10
python 3.7
cuda 10.1(我笔记本上没有可以使用cuda的显卡)
实验过程
1. 确定我们要加载的库
import torch import torch.nn as nn import torchvision #这里面直接加载MNIST数据的方法 import torchvision.transforms as transforms # 将数据转为Tensor import torch.optim as optim import torch.utils.data.dataloader as dataloader
2. 加载数据
这里使用所有数据进行训练,再使用所有数据进行测试
train_set = torchvision.datasets.MNIST( root='./data', # 文件存储位置 train=True, transform=transforms.ToTensor(), download=True ) train_dataloader = dataloader.DataLoader(dataset=train_set,shuffle=False,batch_size=100)# dataset可以省 ''' dataloader返回(images,labels) 其中, images维度:[batch_size,1,28,28] labels:[batch_size],即图片对应的 ''' test_set = torchvision.datasets.MNIST( root='./data', train=False, transform=transforms.ToTensor(), download=True ) test_dataloader = dataloader.DataLoader(test_set,batch_size=100,shuffle=False) # dataset可以省
3. 定义神经网络模型
这里使用全神经网络作为模型
class NeuralNet(nn.Module): def __init__(self,in_num,h_num,out_num): super(NeuralNet,self).__init__() self.ln1 = nn.Linear(in_num,h_num) self.ln2 = nn.Linear(h_num,out_num) self.relu = nn.ReLU() def forward(self,x): return self.ln2(self.relu(self.ln1(x)))
4. 模型训练
in_num = 784 # 输入维度 h_num = 500 # 隐藏层维度 out_num = 10 # 输出维度 epochs = 30 # 迭代次数 learning_rate = 0.001 USE_CUDA = torch.cuda.is_available() # 定义是否可以使用cuda model = NeuralNet(in_num,h_num,out_num) # 初始化模型 optimizer = optim.Adam(model.parameters(),lr=learning_rate) # 使用Adam loss_fn = nn.CrossEntropyLoss() # 损失函数 for e in range(epochs): for i,data in enumerate(train_dataloader): (images,labels) = data images = images.reshape(-1,28*28) # [batch_size,784] if USE_CUDA: images = images.cuda() # 使用cuda labels = labels.cuda() # 使用cuda y_pred = model(images) # 预测 loss = loss_fn(y_pred,labels) # 计算损失 optimizer.zero_grad() loss.backward() optimizer.step() n = e * i +1 if n % 100 == 0: print(n,'loss:',loss.item())
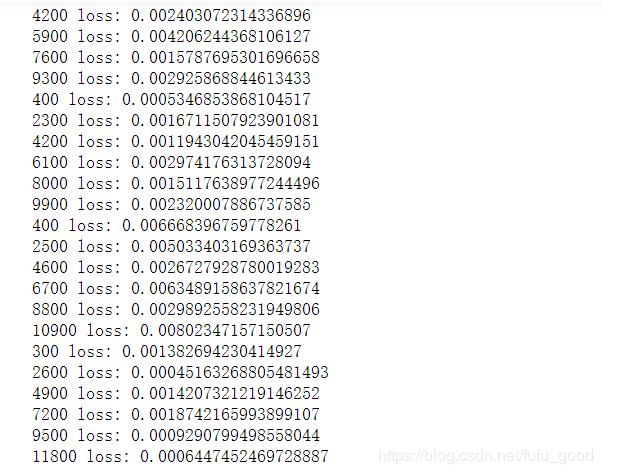
训练模型的loss部分截图如下:
5. 测试模型
with torch.no_grad():
total = 0
correct = 0
for (images,labels) in test_dataloader:
images = images.reshape(-1,28*28)
if USE_CUDA:
images = images.cuda()
labels = labels.cuda()
result = model(images)
prediction = torch.max(result, 1)[1] # 这里需要有[1],因为它返回了概率还有标签
total += labels.size(0)
correct += (prediction == labels).sum().item()
print("The accuracy of total {} images: {}%".format(total, 100 * correct/total))
实验结果
最终实验的正确率达到:98.22%
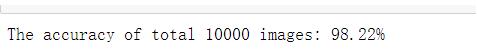
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持易盾网络。