集合(set)是一个无序的不重复元素序列。
可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
集合、是字典的表亲
{}并不是字典的特权
集合的特点:
1 具有唯一性
2 不支持索引
3 与字典相同,也是无序的
创建格式:
parame = {value01,value02,...}
或者
set(value)
创建方法
num1 = {1,2,3,4}
num2 = set(['q','w','e','r'])
print(num1,num2)
num3 = [1,2,3,4,2,4,2,1]
temp = num3.copy()
temp = set(temp)
print(temp)
实例
>>>basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
>>> print(basket) # 这里演示的是去重功能
{'orange', 'banana', 'pear', 'apple'}
>>> 'orange' in basket # 快速判断元素是否在集合内
True
>>> 'crabgrass' in basket
False
>>> # 下面展示两个集合间的运算.
...
>>> a = set('abracadabra')
>>> b = set('alacazam')
>>> a
{'a', 'r', 'b', 'c', 'd'}
>>> a - b # 集合a中包含而集合b中不包含的元素
{'r', 'd', 'b'}
>>> a | b # 集合a或b中包含的所有元素
{'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
>>> a & b # 集合a和b中都包含了的元素
{'a', 'c'}
>>> a ^ b # 不同时包含于a和b的元素
{'r', 'd', 'b', 'm', 'z', 'l'}
类似列表推导式,同样集合支持集合推导式(Set comprehension):
>>>a = {x for x in 'abracadabra' if x not in 'abc'}
>>> a
{'r', 'd'}
集合的基本操作
1、添加元素
语法格式如下:
s.add( x )
将元素 x 添加到集合 s 中,如果元素已存在,则不进行任何操作。
>>>thisset = set(("Baidu", "jb51", "Taobao"))
>>> thisset.add("Facebook")
>>> print(thisset)
{'Facebook', 'Taobao', 'Baidu', 'jb51'}
输出的内容都是随机的没有排序
还有一个方法,也可以添加元素,且参数可以是列表,元组,字典等,语法格式如下:
s.update( x )
x 可以有多个,用逗号分开。
>>>thisset = set(("Baidu", "Jb51", "Taobao"))
>>> thisset.update({1,3})
>>> print(thisset)
{1, 3, 'Baidu', 'Taobao', 'Jb51'}
>>> thisset.update([1,4],[5,6])
>>> print(thisset)
{1, 3, 4, 5, 6, 'Baidu', 'Taobao', 'Jb51'}
>>>
2、移除元素
语法格式如下:
s.remove( x )
将元素 x 从集合 s 中移除,如果元素不存在,则会发生错误。
实例(Python 3.0+)
>>>thisset = set(("Baidu", "Jb51", "Taobao"))
>>> thisset.remove("Taobao")
>>> print(thisset)
{'Baidu', 'Jb51'}
>>> thisset.remove("Facebook") # 不存在会发生错误
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'Facebook'
>>>
此外还有一个方法也是移除集合中的元素,且如果元素不存在,不会发生错误。格式如下所示:
s.discard( x )
实例(Python 3.0+)
>>>thisset = set(("Baidu", "Jb51", "Taobao"))
>>> thisset.discard("Facebook") # 不存在不会发生错误
>>> print(thisset)
{'Taobao', 'Baidu', 'Jb51'}
我们也可以设置随机删除集合中的一个元素,语法格式如下:
s.pop()
脚本模式实例(Python 3.0+)
thisset = set(("Baidu", "Jb51", "Taobao", "Facebook"))
x = thisset.pop()
print(x)
输出结果:
$ python3 test.py
Jb51
多次执行测试结果都不一样。
set 集合的 pop 方法会对集合进行无序的排列,然后将这个无序排列集合的左面第一个元素进行删除。
3、计算集合元素个数
语法格式如下:
len(s)
计算集合 s 元素个数。
实例(Python 3.0+)
>>>thisset = set(("Baidu", "Jb51", "Taobao"))
>>> len(thisset)
3
4、清空集合
语法格式如下:
s.clear()
清空集合 s。
实例(Python 3.0+)
>>>thisset = set(("Baidu", "Jb51", "Taobao"))
>>> thisset.clear()
>>> print(thisset)
set()
5、判断元素是否在集合中存在
语法格式如下:
x in s
判断元素 x 是否在集合 s 中,存在返回 True,不存在返回 False。
实例(Python 3.0+)
>>>thisset = set(("Baidu", "Jb51", "Taobao"))
>>> "Jb51" in thisset
True
>>> "Facebook" in thisset
False
>>>
集合内置方法完整列表
下面继续为大家补充一些实例
s.update( "字符串" ) 与 s.update( {"字符串"} ) 含义不同:
s.update( {"字符串"} ) 将字符串添加到集合中,有重复的会忽略。
s.update( "字符串" ) 将字符串拆分单个字符后,然后再一个个添加到集合中,有重复的会忽略。
>>> thisset = set(("Baidu", "Jb51", "Taobao"))
>>> print(thisset)
{'Baidu', 'Jb51', 'Taobao'}
>>> thisset.update({"Facebook"})
>>> print(thisset)
{'Baidu', 'Jb51', 'Taobao', 'Facebook'}
>>> thisset.update("Yahoo")
>>> print(thisset)
{'h', 'o', 'Facebook', 'Baidu', 'Y', 'Jb51', 'Taobao', 'a'}
>>>
set() 中参数注意事项
1.创建一个含有一个元素的集合
>>> my_set = set(('apple',))
>>> my_set
{'apple'}
2.创建一个含有多个元素的集合
>>> my_set = set(('apple','pear','banana'))
>>> my_set
{'apple', 'banana', 'pear'}
3.如无必要,不要写成如下形式
>>> my_set = set('apple')
>>> my_set
{'l', 'e', 'p', 'a'}
>>> my_set1 = set(('apple'))
>>> my_set1
{'l', 'e', 'p', 'a'}
集合用 set.pop() 方法删除元素的不一样的感想如下:
1、对于 python 中列表 list、tuple 类型中的元素,转换集合是,会去掉重复的元素如下:
>>> list = [1,1,2,3,4,5,3,1,4,6,5]
>>> set(list)
{1, 2, 3, 4, 5, 6}
>>> tuple = (2,3,5,6,3,5,2,5)
>>> set(tuple)
{2, 3, 5, 6}
2、集合对 list 和 tuple 具有排序(升序),举例如下:
>>> set([9,4,5,2,6,7,1,8])
{1, 2, 4, 5, 6, 7, 8, 9}
>>> set([9,4,5,2,6,7,1,8])
{1, 2, 4, 5, 6, 7, 8, 9}
3、集合的 set.pop() 的不同认为
有人认为 set.pop() 是随机删除集合中的一个元素、我在这里说句非也!对于是字典和字符转换的集合是随机删除元素的。当集合是由列表和元组组成时、set.pop() 是从左边删除元素的如下:
列表实例:
set1 = set([9,4,5,2,6,7,1,8])
print(set1)
print(set1.pop())
print(set1)
输出结果:
{1, 2, 4, 5, 6, 7, 8, 9}
1
{2, 4, 5, 6, 7, 8, 9}
元组实例:
set1 = set((6,3,1,7,2,9,8,0))
print(set1)
print(set1.pop())
print(set1)
输出结果:
{0, 1, 2, 3, 6, 7, 8, 9}
0
{1, 2, 3, 6, 7, 8, 9}
>>> thisset = set(("Baidu", "Jb51", "Taobao", "Facebook"))
>>> y=set({'python'})
>>> print(y.union(thisset))
{'python', 'Taobao', 'Baidu', 'Facebook', 'Jb51'}
输出结果:
{'python', 'Baidu', 'Taobao', 'Facebook', 'Jb51'}
y 的集合里此时只含有一个元素 'python',而如果不加花括号时,y 的集合里含有'p','y','t','h','o','n'五个元素。
>>> thisset = set(("Baidu", "Jb51", "Taobao", "Facebook"))
>>> y=set('python')
>>> print(y.union(thisset))
{'p', 'o', 'y', 'Taobao', 'h', 'Baidu', 'Facebook', 'Jb51', 'n', 't'}
也可以使用括号:
thisset = set(("Baidu", "Jb51", "Taobao", "Facebook"))
y=set(('python','love'))
print(y.union(thisset))
输出结果:
{'Facebook', 'Jb51', 'Taobao', 'python', 'love', 'Baidu'}
但是当 y 的集合里只有一个字符串时,结果与不加花括号一样。
列表的 sort 方法可以实现就地排序(无需创建新对象,字符串按首字母进行排序):
a=[1, 51, 31, -3, 10] a.sort() print(a) s=['a','ab','3e','z'] s.sort() print(s)
输出:
[-3, 1, 10, 31, 51]
['3e', 'a', 'ab', 'z']
按集合中的字符长度进行排序:
a=[1, 51, 31, -3, 10] a.sort() print(a) b=['a','ab','3ae','zaaa','1'] b.sort() print(b) c=['a','ab','3ae','zaaa','1'] c.sort(key=len) print(c)
输出:
[-3, 1, 10, 31, 51]
['1', '3ae', 'a', 'ab', 'zaaa']
['a', '1', 'ab', '3ae', 'zaaa']
下面是其他网友的补充图文
集合也也也也是python内置的一种数据结构,它是一个无序且元素不重复的序列。这里有两个关键词一个是无序,这一点和字典是一样的,另一个关键词是元素不重复,这一点和字典的key(键)是一样的。这么看来集合和字典还真像,事实上他们长的也很像:

集合和字典一样也是用{}包起来的,那么问题来了,如果只写一个{}那它是集合还是字典呢?
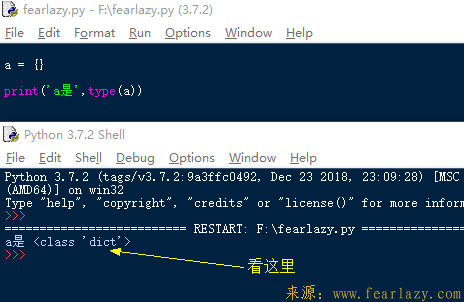
{}里没有元素创建的是字典,那么问题又来了,空集合又该怎么创建呢?我们可以使用set()函数创建。既然集合已经创建出来了,接着就看看集合的一些用法吧。
1.往集合里增加元素:
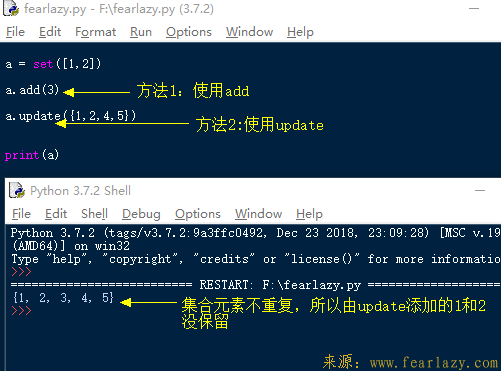
集合的add函数可以往集合里添加一个元素,update可以更新一个或多个元素,其参数可以是列表、集合等等。
2.删除集合里的元素。
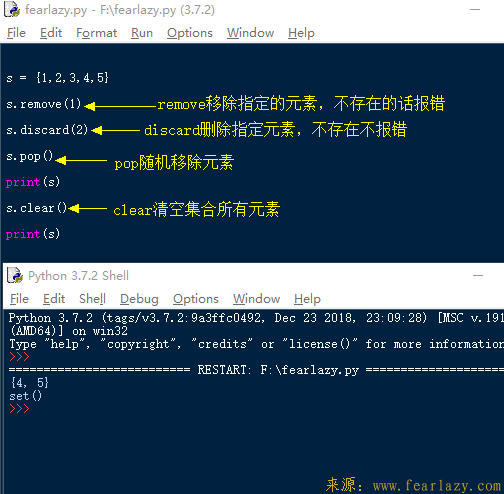
要删除集合中的元素方法还挺多的啊,不过那个pop函数是认真的吗?随机移除元素也太随意了吧...
由于集合是无序的,所以没办法用下标来获取集合的元素,也没办法像字典一样通过key来获取值。这就尴尬了。看来集合就像貔貅一样只能存数据不能取数据。
3.集合的运算
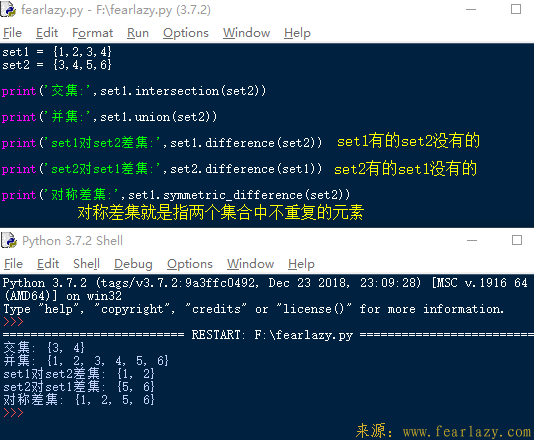
交集和并集很好理解,差集是个相对的概念,集合1相对集合2差集和集合2相对集合1的差集是不一样的,需要特别注意。所以对称差集可以理解为非交集元素组成的那部分。
4.集合的包含关系
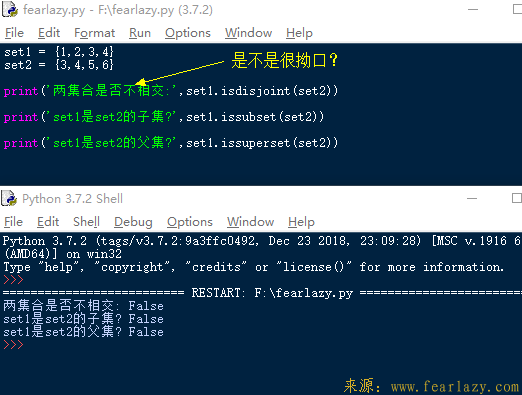
集合的几种关系:相交/不相交 ,包含/不包含(相对而言)。isdisjoint函数是判断不相交的,不相交才返回True。