前言
硬要说这篇文章怎么来的,那得先从那几个吃野味的人开始说起…… 前天睡醒:假期还有几天;昨天睡醒:假期还有十几天;今天睡醒:假期还有一个月…… 每天过着几乎和每个假期一样的宅男生活,唯一不同的是玩手机已不再是看剧、看电影、打游戏了,而是每天都在关注着这次新冠肺炎疫情的新闻消息,真得希望这场战“疫”快点结束,让我们过上像以前一样的生活。武汉加油!中国加油!!
本次爬取的网站是丁香园点击跳转,相信大家平时都是看这个的吧。
一、准备
python3.7
- selenium:自动化测试框架,直接pip install selenium安装即可
- pyecharts:以一切皆可配置而闻名的python封装的js画图工具,其官方文档写的很详细了点击跳转。
- 直接pip install pyecharts安装即可,同时还需安装以下地图的包:
世界地图:pip install echarts-countries-pypkg 中国地图:pip install echarts-china-provinces-pypkg 中国城市地图:pip install echarts-china-cities-pypkg
云服务器
二、爬取数据+画图
第一步、分析页面
先用个requests模块请求一下,看能不能拿到数据:
import requests
url='https://ncov.dxy.cn/ncovh5/view/pneumonia_peopleapp?from=timeline&isappinstalled=0'
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'}
r=requests.get(url,headers=headers)
print(r.text)
发现数据是乱码的并且注意到末尾处有如下字样:
<noscript>You need to enable JavaScript to run this app.</noscript>
意思是需要执行js代码,百度了一下发现这个页面应该是用react.js来开发的。限于自身技术能力,这个时候,我就只能用selenium了,它是完全模拟浏览器的操作,也即能执行js代码。
并且我需要拿到的数据并不多,也就一个页面而已,所以耗时也可以接受。
那么我要拿哪些数据呢,如下:
- 截至当前时间的全国数据统计
- 病毒相关描述信息
- 全国各个省份及其城市的所有数据
- 全世界各个地区的数据
经过查看,发现这几处需要进行点击,才能获取到更多数据信息:

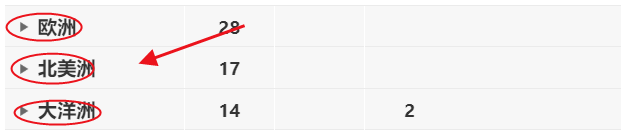
第二步、编写代码
导入相关包:
from selenium import webdriver from selenium.webdriver.common.action_chains import ActionChains from selenium.webdriver.common.keys import Keys import parsel import time import json import os import datetime import pyecharts from pyecharts import options as opts
定义爬取数据、保存数据的函数:
def get_save_data():
'''
部署到云服务器上时,注意:要安装pyvirtualdisplay模块,
并且把下面的前5条注释掉的代码给去掉注释,再运行,不然会报错。
'''
#from pyvirtualdisplay import Display
#display = Display(visible=0, size=(800, 600))
#display.start()
options=webdriver.ChromeOptions()
#options.add_argument('--disable-gpu')
#options.add_argument("--no-sandbox")
options.add_argument('--headless') #采用无头模式进行爬取
d=webdriver.Chrome(options=options)
d.get('https://ncov.dxy.cn/ncovh5/view/pneumonia_peopleapp?from=timeline&isappinstalled=0')
time.sleep(2)
ActionChains(d).move_to_element(d.find_element_by_xpath('//p[@class="mapTap___1k3MH"]')).perform()
time.sleep(2)
d.find_element_by_xpath('//span[@class="openIconView___3hcbn"]').click()
time.sleep(2)
for i in range(3):
mores=d.find_elements_by_xpath('//div[@class="areaBox___3jZkr"]')[1].find_elements_by_xpath('./div')[3:-1]
ActionChains(d).move_to_element(d.find_element_by_xpath('//div[@class="rumorTabWrap___2kiW4"]/p')).perform()
mores[i].click()
time.sleep(2)
response=parsel.Selector(d.page_source)
china=response.xpath('//div[@class="areaBox___3jZkr"]')[0]
world=response.xpath('//div[@class="areaBox___3jZkr"]')[1]
# 下面是病毒相关描述信息的获取与处理
content=response.xpath('//div[@class="mapTop___2VZCl"]/div[1]//text()').getall()
s=''
for i,j in enumerate(content):
s=s+j
if (i+1)%2 == 0:
s=s+'\n'
if j in ['确诊','疑似','重症','死亡','治愈']:
s=s+'\n'
now=s.strip()
msg=response.xpath('//div[@class="mapTop___2VZCl"]/div//text()').getall()
s=''
for i in msg:
if i not in now:
s=s+i+'\n'
msg=s.strip()
content=msg+'\n\n'+now
# 下面是全国数据的获取
china_data=[]
for div_list in china.xpath('./div')[2:-1]:
flag=0
city_list=[]
for div in div_list.xpath('./div'):
if flag == 0:
if div.xpath('./p[1]/text()').get() is not None:
item={}
item['省份']=div.xpath('./p[1]/text()').get()
item['确诊']=div.xpath('./p[2]/text()').get() if div.xpath('./p[2]/text()').get() is not None else '0'
item['死亡']=div.xpath('./p[3]/text()').get() if div.xpath('./p[3]/text()').get() is not None else '0'
item['治愈']=div.xpath('./p[4]/text()').get() if div.xpath('./p[4]/text()').get() is not None else '0'
flag=1
else:
if div.xpath('./p[1]/span/text()').get() is not None:
temp={}
temp['城市']=div.xpath('./p[1]/span/text()').get()
temp['确诊']=div.xpath('./p[2]/text()').get() if div.xpath('./p[2]/text()').get() is not None else '0'
temp['死亡']=div.xpath('./p[3]/text()').get() if div.xpath('./p[3]/text()').get() is not None else '0'
temp['治愈']=div.xpath('./p[4]/text()').get() if div.xpath('./p[4]/text()').get() is not None else '0'
city_list.append(temp)
item.update({'city_list':city_list})
china_data.append(item)
# 下面是全球数据的获取
world_data=[]
for div_list in world.xpath('./div')[2:-1]:
flag=0
country_list=[]
for div in div_list.xpath('./div'):
if flag == 0:
if div.xpath('./p[1]/text()').get() is not None:
item={}
item['地区']=div.xpath('./p[1]/text()').get()
item['确诊']=div.xpath('./p[2]/text()').get() if div.xpath('./p[2]/text()').get() is not None else '0'
item['死亡']=div.xpath('./p[3]/text()').get() if div.xpath('./p[3]/text()').get() is not None else '0'
item['治愈']=div.xpath('./p[4]/text()').get() if div.xpath('./p[4]/text()').get() is not None else '0'
flag=1
else:
if div.xpath('./p[1]/span/text()').get() is not None:
temp={}
temp['国家']=div.xpath('./p[1]/span/text()').get()
temp['确诊']=div.xpath('./p[2]/text()').get() if div.xpath('./p[2]/text()').get() is not None else '0'
temp['死亡']=div.xpath('./p[3]/text()').get() if div.xpath('./p[3]/text()').get() is not None else '0'
temp['治愈']=div.xpath('./p[4]/text()').get() if div.xpath('./p[4]/text()').get() is not None else '0'
country_list.append(temp)
item.update({'country_list':country_list})
world_data.append(item)
d.quit()
# 下面是保存数据的操作
if not os.path.exists('./json'):
os.makedirs('./json')
if not os.path.exists('./txt'):
os.makedirs('./txt')
now_time=datetime.datetime.now().strftime("%Y-%m-%d") #获取当前日期
index=list(range(len(china_data)))
data=dict(zip(index,china_data))
json_str = json.dumps(data, indent=4,ensure_ascii=False)
with open(f'./json/{now_time}.json', 'w', encoding='utf-8') as f:
f.write(json_str)
index=list(range(len(world_data)))
data=dict(zip(index,world_data))
json_str = json.dumps(data, indent=4,ensure_ascii=False)
with open(f'{now_time}.json', 'w', encoding='utf-8') as f:
f.write(json_str)
with open(f'./txt/{now_time}.txt', 'w', encoding='utf-8') as f:
f.write(content)
定义画地图的函数,输出是一个html文件:
def get_html():
# 首先是加载爬取到的数据
json_files=os.listdir('./json')
json_data=[]
date=[]
for i in json_files:
with open(f'./json/{i}','r',encoding='utf-8') as f:
date.append(i.split('.')[0])
temp=json.load(f)
json_data.append(list(temp.values()))
txt_files=os.listdir('./txt')
content_list=[]
for i in txt_files:
with open(f'./txt/{i}','r',encoding='utf-8') as f:
content_list.append(f.read())
# 下面开始画图
t=pyecharts.charts.Timeline(init_opts=opts.InitOpts(width='1400px',height='1400px',page_title='武汉加油!中国加油!!'))
for s,(i,data) in enumerate(zip(date,json_data)):
value=[] # 储存确诊人数
attr=[] # 储存城市名字
for each in data:
attr.append(each['省份'])
value.append(int(each['确诊']))
map0 = (
pyecharts.charts.Map()
.add(
series_name='该省份确诊数',data_pair=list(zip(attr,value)),maptype='china',is_map_symbol_show=True,zoom=1.1
)
.set_global_opts(title_opts=opts.TitleOpts(title="武汉加油!中国加油!!", # 标题
subtitle=content_list[s], # 副标题
title_textstyle_opts=opts.TextStyleOpts(color='red',font_size=30), # 标题文字
subtitle_textstyle_opts=opts.TextStyleOpts(color='black',font_size=20),item_gap=20), # 副标题文字
visualmap_opts=opts.VisualMapOpts(pieces=[{"max": 9, "min": 1,'label':'1-9','color':'#FFEBCD'},
{"max": 99, "min": 10,'label':'10-99','color':'#F5DEB3'},
{"max": 499, "min": 100,'label':'100-499','color':'#F4A460'},
{"max": 999, "min": 500,'label':'500-999','color':'#FA8072'},
{"max": 9999,"min": 1000,'label':'1000-9999','color':'#ee2c0f'},
{"min": 10000,'label':'≥10000','color':'#5B5B5B'}],
is_piecewise=True,item_width=45,item_height=30,textstyle_opts=opts.TextStyleOpts(font_size=20))
)
)
t.add(map0, "{}".format(i))
# 将这幅图保存为html文件
t.render('武汉加油!中国加油!!.html')
程序入口:
if __name__ == '__main__': get_save_data() get_html()
第三步、结果展示
运行该程序之后,会在当前目录下生成一个武汉加油!中国加油!!.html的文件,打开之后如下:
ps:因为只能上传图片,所以我就将html转为图片了,html是动态的,有时间轴可以拖动,由于昨天才刚开始爬数据,所以只有两天的数据。下面附上转图片的代码:
ps:又因为这个Timeline时间线轮播多图,配置不了背景颜色,发现生成的图片放大看变成黑色背景的,于是研究了一下源码,自己修改了一下js那块的代码,然后就生成可以设置背景颜色的图片了
from selenium import webdriver
import base64
import os
options=webdriver.ChromeOptions()
options.add_argument('--headless') #采用无头模式进行爬取
d=webdriver.Chrome(options=options)
url='file://'+os.path.abspath('武汉加油!中国加油!!.html')
d.get(url)
def decode_base64(data: str) -> bytes:
"""Decode base64, padding being optional.
:param data: Base64 data as an ASCII byte string
:returns: The decoded byte string.
"""
missing_padding = len(data) % 4
if missing_padding != 0:
data += "=" * (4 - missing_padding)
return base64.decodebytes(data.encode("utf-8"))
def save_as_png(image_data: bytes, output_name: str):
with open(output_name, "wb") as f:
f.write(image_data)
js = """
var ele = document.querySelector('div[_echarts_instance_]');
var mychart = echarts.getInstanceByDom(ele);
return mychart.getDataURL({
type: 'png',
pixelRatio: 2,
backgroundColor:'#FFFFFF',
excludeComponents: ['toolbox']
});
"""
content=d.execute_script(js)
content_array = content.split(",")
image_data = decode_base64(content_array[1])
save_as_png(image_data, '武汉加油!中国加油!!.png')
d.quit()
三、部署到云服务器
1.定时运行获取数据
首先将爬取数据的函数,即get_save_data()单独放到一个py文件中(我命名为:2019-nCoV.py)。然后修改定时任务/etc/crontab文件,如下:
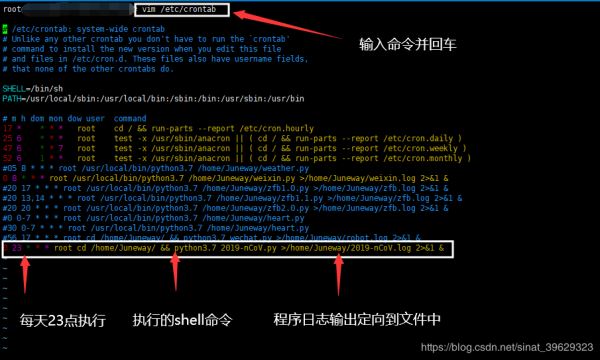
2.通过微信获取地图(html文件)
把画地图的函数,即get_html()添加到个人微信机器人当中,然后设置特定判断条件,在手机微信上向文件传输助手发送设定好的指令,执行get_html()函数,然后把执行函数后生成的html文件发给文件传输助手,从而获取到当前的疫情地图。
个人微信机器人的代码我就不再展示了,可以看我之前的文章:python实现微信自动回复机器人
特定判断的语句如下:
if '2019' == msg['Text']:
get_html()
itchat.send('@fil@%s'%'武汉加油!中国加油!!.html',toUserName='filehelper')
同时,也可以把刚刚的获取数据的函数一起添加进去的,然后同样通过发送特定指令运行函数,而获取数据,我这里不加进去呢,是因为我要设置个定时任务,定时获取就行了;并且我也可以通过给文件传输助手发送shell命令,执行py文件。
把下面的代码加进个人微信机器人py文件里就行了。
import subprocess def cmd(command): output=subprocess.getoutput(command) return output
并给出我的特定判断语句:
if 'cmd' in msg['Text']: output=cmd(msg['Text'][3:]) if output != '': itchat.send(output, toUserName='filehelper')
四、运行展示
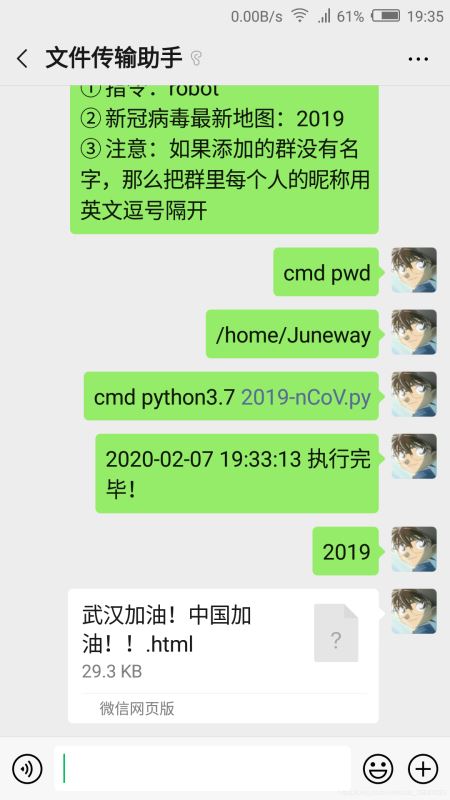
如上图所示:我先是执行了爬取数据的函数,即我调用了云服务器上的定时爬取数据的py文件,然后再输入指令获取当前的疫情地图,打开后像上面的疫情地图一样。
写在最后
世界的疫情地图我没有画,是因为pyecharts的世界地图各个地区是用英文命名的,跟获取到的地区匹配不上,其实可以加个中文转英文给它,那就可以了,我懒的弄了,有兴趣的朋友可以试一试哦
一开始,我只是在那些爬虫微信群上看到:今天这谁在爬丁香园的数据,过几天又看到那谁又在爬丁香园的数据,而且还提出各种问题来讨论。我实在是看不下去了,于是就有了这一篇文章(反正在家闲着也是闲着)
然后呢,今天学校发通知说校外的大四学生也可以申请vpn,然后在家就可以查看和下载知网的文献了。准备毕业的我突然惊了,我的论文还未开始写呢!看来是时候了……
其实我是想回学校再写的,但是这次的新冠肺炎疫情来势凶猛,真的希望快点好起来啊~
武汉加油!中国加油!!
总结
以上所述是小编给大家介绍的python+selenium定时爬取丁香园的新冠病毒每天的数据并制作出类似的地图(部署到云服务器),希望对大家有所帮助!