起步
Python3 起,str 就采用了 Unicode 编码(注意这里并不是 utf8 编码,尽管 .py 文件默认编码是 utf8 )。 每个标准 Unicode 字符占用 4 个字节。这对于内存来说,无疑是一种浪费。
Unicode 是表示了一种字符集,而为了传输方便,衍生出里如 utf8 , utf16 等编码方案来节省存储空间。Python内部存储字符串也采用了类似的形式。
三种内部表示Unicode字符串
为了减少内存的消耗,Python使用了三种不同单位长度来表示字符串:
- 每个字符 1 个字节(Latin-1)
- 每个字符 2 个字节(UCS-2)
- 每个字符 4 个字节(UCS-4)
源码中定义字符串结构体:
# Include/unicodeobject.h
typedef uint32_t Py_UCS4;
typedef uint16_t Py_UCS2;
typedef uint8_t Py_UCS1;
# Include/cpython/unicodeobject.h
typedef struct {
PyCompactUnicodeObject _base;
union {
void *any;
Py_UCS1 *latin1;
Py_UCS2 *ucs2;
Py_UCS4 *ucs4;
} data; /* Canonical, smallest-form Unicode buffer */
} PyUnicodeObject;
如果字符串中所有字符都在 ascii 码范围内,那么就可以用占用 1 个字节的 Latin-1 编码进行存储。而如果字符串中存在了需要占用两个字节(比如中文字符),那么整个字符串就将采用占用 2 个字节 UCS-2 编码进行存储。
这点可以通过 sys.getsizeof 函数外部窥探来验证这个结论:
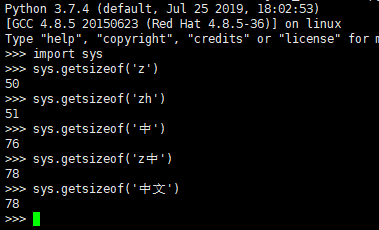
如图,存储 'zh' 所需的存储空间比 'z' 多 1 个字节, h 在这里占了 1 个字节;
存储 'z中' 所需的存储空间比 '中' 多了 2 个字节,z 在这里占了 2 个字节。
大多数的自然语言采用 2 字节的编码就够了。但如果有一个 1G 的 ascii 文本加载到内存后,在文本中插入了一个 emoji 表情,那么字符串所需的空间将扩大到 4 倍,是不是很惊喜。
为什么内部不采用 utf8 进行编码
最受欢迎的 Unicode 编码方案,Python内部却不使用它,为什么?
这里就得说下 utf8 编码带来的缺点。这种编码方案每个字符的占用字节长度是变化的,这就导致了无法按所以随机访问单个字符,例如 string[n] (使用utf8编码)则需要先统计前n个字符占用的字节长度。所以由 O(1) 变成了 O(n) ,这更无法让人接受。
因此Python内部采用了定长的方式存储字符串。
字符串驻留机制
另一个节省内存的方式就是将一些短小的字符串做成池,当程序要创建字符串对象前检查池中是否有满足的字符串。在内部中,仅包含下划线(_)、字母 和 数字 的长度不高过 20 的字符串才能驻留。驻留是在代码编译期间进行的,代码中的如下会进行驻留检查:
- 空字符串 '' 及所有;
- 变量名;
- 参数名;
- 字符串常量(代码中定义的所有字符串);
- 字典键;
- 属性名称;
驻留机制节省大量的重复字符串内存。在内部,字符串驻留池由一个全局的 dict 维护,该字段将字符串用作键:
void PyUnicode_InternInPlace(PyObject **p)
{
PyObject *s = *p;
PyObject *t;
if (s == NULL || !PyUnicode_Check(s))
return;
// 对PyUnicodeObjec进行类型和状态检查
if (!PyUnicode_CheckExact(s))
return;
if (PyUnicode_CHECK_INTERNED(s))
return;
// 创建intern机制的dict
if (interned == NULL) {
interned = PyDict_New();
if (interned == NULL) {
PyErr_Clear(); /* Don't leave an exception */
return;
}
}
// 对象是否存在于inter中
t = PyDict_SetDefault(interned, s, s);
// 存在, 调整引用计数
if (t != s) {
Py_INCREF(t);
Py_SETREF(*p, t);
return;
}
/* The two references in interned are not counted by refcnt.
The deallocator will take care of this */
Py_REFCNT(s) -= 2;
_PyUnicode_STATE(s).interned = SSTATE_INTERNED_MORTAL;
}
变量 interned 就是全局存放字符串池的字典的变量名 interned = PyDict_New(),为了让 intern 机制中的字符串不被回收,设置字典时 PyDict_SetDefault(interned, s, s); 将字符串作为键同时也作为值进行设置,这样对于字符串对象的引用计数就会进行两次 +1 操作,这样存于字典中的对象在程序结束前永远不会为 0,这也是 y_REFCNT(s) -= 2; 将计数减 2 的原因。
从函数参数中可以看到其实字符串对象还是被创建了,内部其实始终会为字符串创建对象,但经过 inter 机制检查后,临时创建的字符串会因引用计数为 0 而被销毁,临时变量在内存中昙花一现然后迅速消失。
字符串缓冲池
除了字符串驻留池,Python 还会保存所有 ascii 码内的单个字符:
static PyObject *unicode_latin1[256] = {NULL};
如果字符串其实是一个字符,那么优先从缓冲池中获取:
[unicodeobjec.c]
PyObject * PyUnicode_DecodeUTF8Stateful(const char *s,
Py_ssize_t size,
const char *errors,
Py_ssize_t *consumed)
{
...
/* ASCII is equivalent to the first 128 ordinals in Unicode. */
if (size == 1 && (unsigned char)s[0] < 128) {
return get_latin1_char((unsigned char)s[0]);
}
...
}
然后再经过 intern 机制后被保存到 intern 池中,这样驻留池中和缓冲池中,两者都是指向同一个字符串对象了。
严格来说,这个单字符缓冲池并不是省内存的方案,因为从中取出的对象几乎都会保存到缓冲池中,这个方案是为了减少字符串对象的创建。
总结
本文介绍了两种是节省内存的方案。一个字符串的每个字符在占用空间大小是相同的,取决于字符串中的最大字符。
短字符串会放到一个全局的字典中,该字典中的字符串成了单例模式,从而节省内存。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持易盾网络。