Tensorflow是目前最流行的深度学习框架,我们可以用它来搭建自己的卷积神经网络并训练自己的分类器,本文介绍怎样使用Tensorflow构建自己的CNN,怎样训练用于简单的验证码识别的分类
Tensorflow是目前最流行的深度学习框架,我们可以用它来搭建自己的卷积神经网络并训练自己的分类器,本文介绍怎样使用Tensorflow构建自己的CNN,怎样训练用于简单的验证码识别的分类器。本文假设你已经安装好了Tensorflow,了解过CNN的一些知识。
下面将分步介绍怎样获得训练数据,怎样使用tensorflow构建卷积神经网络,怎样训练,以及怎样测试训练出来的分类器
1. 准备训练样本
使用Python的库captcha来生成我们需要的训练样本,代码如下:
import sys
import os
import shutil
import random
import time
#captcha是用于生成验证码图片的库,可以 pip install captcha 来安装它
from captcha.image import ImageCaptcha
#用于生成验证码的字符集
CHAR_SET = ['0','1','2','3','4','5','6','7','8','9']
#字符集的长度
CHAR_SET_LEN = 10
#验证码的长度,每个验证码由4个数字组成
CAPTCHA_LEN = 4
#验证码图片的存放路径
CAPTCHA_IMAGE_PATH = 'E:/Tensorflow/captcha/images/'
#用于模型测试的验证码图片的存放路径,它里面的验证码图片作为测试集
TEST_IMAGE_PATH = 'E:/Tensorflow/captcha/test/'
#用于模型测试的验证码图片的个数,从生成的验证码图片中取出来放入测试集中
TEST_IMAGE_NUMBER = 50
#生成验证码图片,4位的十进制数字可以有10000种验证码
def generate_captcha_image(charSet = CHAR_SET, charSetLen=CHAR_SET_LEN, captchaImgPath=CAPTCHA_IMAGE_PATH):
k = 0
total = 1
for i in range(CAPTCHA_LEN):
total *= charSetLen
for i in range(charSetLen):
for j in range(charSetLen):
for m in range(charSetLen):
for n in range(charSetLen):
captcha_text = charSet[i] + charSet[j] + charSet[m] + charSet[n]
image = ImageCaptcha()
image.write(captcha_text, captchaImgPath + captcha_text + '.jpg')
k += 1
sys.stdout.write("\rCreating %d/%d" % (k, total))
sys.stdout.flush()
#从验证码的图片集中取出一部分作为测试集,这些图片不参加训练,只用于模型的测试
def prepare_test_set():
fileNameList = []
for filePath in os.listdir(CAPTCHA_IMAGE_PATH):
captcha_name = filePath.split('/')[-1]
fileNameList.append(captcha_name)
random.seed(time.time())
random.shuffle(fileNameList)
for i in range(TEST_IMAGE_NUMBER):
name = fileNameList[i]
shutil.move(CAPTCHA_IMAGE_PATH + name, TEST_IMAGE_PATH + name)
if __name__ == '__main__':
generate_captcha_image(CHAR_SET, CHAR_SET_LEN, CAPTCHA_IMAGE_PATH)
prepare_test_set()
sys.stdout.write("\nFinished")
sys.stdout.flush()
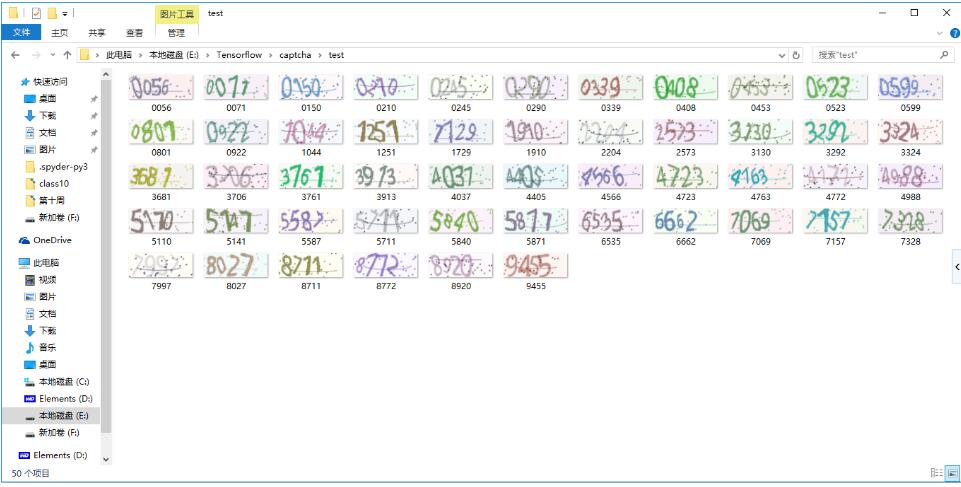
运行上面的代码,可以生成验证码图片,
生成的验证码图片如下图所示:

2. 构建CNN,训练分类器
代码如下:
import tensorflow as tf
import numpy as np
from PIL import Image
import os
import random
import time
#验证码图片的存放路径
CAPTCHA_IMAGE_PATH = 'E:/Tensorflow/captcha/images/'
#验证码图片的宽度
CAPTCHA_IMAGE_WIDHT = 160
#验证码图片的高度
CAPTCHA_IMAGE_HEIGHT = 60
CHAR_SET_LEN = 10
CAPTCHA_LEN = 4
#60%的验证码图片放入训练集中
TRAIN_IMAGE_PERCENT = 0.6
#训练集,用于训练的验证码图片的文件名
TRAINING_IMAGE_NAME = []
#验证集,用于模型验证的验证码图片的文件名
VALIDATION_IMAGE_NAME = []
#存放训练好的模型的路径
MODEL_SAVE_PATH = 'E:/Tensorflow/captcha/models/'
def get_image_file_name(imgPath=CAPTCHA_IMAGE_PATH):
fileName = []
total = 0
for filePath in os.listdir(imgPath):
captcha_name = filePath.split('/')[-1]
fileName.append(captcha_name)
total += 1
return fileName, total
#将验证码转换为训练时用的标签向量,维数是 40
#例如,如果验证码是 ‘0296' ,则对应的标签是
# [1 0 0 0 0 0 0 0 0 0
# 0 0 1 0 0 0 0 0 0 0
# 0 0 0 0 0 0 0 0 0 1
# 0 0 0 0 0 0 1 0 0 0]
def name2label(name):
label = np.zeros(CAPTCHA_LEN * CHAR_SET_LEN)
for i, c in enumerate(name):
idx = i*CHAR_SET_LEN + ord(c) - ord('0')
label[idx] = 1
return label
#取得验证码图片的数据以及它的标签
def get_data_and_label(fileName, filePath=CAPTCHA_IMAGE_PATH):
pathName = os.path.join(filePath, fileName)
img = Image.open(pathName)
#转为灰度图
img = img.convert("L")
image_array = np.array(img)
image_data = image_array.flatten()/255
image_label = name2label(fileName[0:CAPTCHA_LEN])
return image_data, image_label
#生成一个训练batch
def get_next_batch(batchSize=32, trainOrTest='train', step=0):
batch_data = np.zeros([batchSize, CAPTCHA_IMAGE_WIDHT*CAPTCHA_IMAGE_HEIGHT])
batch_label = np.zeros([batchSize, CAPTCHA_LEN * CHAR_SET_LEN])
fileNameList = TRAINING_IMAGE_NAME
if trainOrTest == 'validate':
fileNameList = VALIDATION_IMAGE_NAME
totalNumber = len(fileNameList)
indexStart = step*batchSize
for i in range(batchSize):
index = (i + indexStart) % totalNumber
name = fileNameList[index]
img_data, img_label = get_data_and_label(name)
batch_data[i, : ] = img_data
batch_label[i, : ] = img_label
return batch_data, batch_label
#构建卷积神经网络并训练
def train_data_with_CNN():
#初始化权值
def weight_variable(shape, name='weight'):
init = tf.truncated_normal(shape, stddev=0.1)
var = tf.Variable(initial_value=init, name=name)
return var
#初始化偏置
def bias_variable(shape, name='bias'):
init = tf.constant(0.1, shape=shape)
var = tf.Variable(init, name=name)
return var
#卷积
def conv2d(x, W, name='conv2d'):
return tf.nn.conv2d(x, W, strides=[1,1,1,1], padding='SAME', name=name)
#池化
def max_pool_2X2(x, name='maxpool'):
return tf.nn.max_pool(x, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME', name=name)
#输入层
#请注意 X 的 name,在测试model时会用到它
X = tf.placeholder(tf.float32, [None, CAPTCHA_IMAGE_WIDHT * CAPTCHA_IMAGE_HEIGHT], name='data-input')
Y = tf.placeholder(tf.float32, [None, CAPTCHA_LEN * CHAR_SET_LEN], name='label-input')
x_input = tf.reshape(X, [-1, CAPTCHA_IMAGE_HEIGHT, CAPTCHA_IMAGE_WIDHT, 1], name='x-input')
#dropout,防止过拟合
#请注意 keep_prob 的 name,在测试model时会用到它
keep_prob = tf.placeholder(tf.float32, name='keep-prob')
#第一层卷积
W_conv1 = weight_variable([5,5,1,32], 'W_conv1')
B_conv1 = bias_variable([32], 'B_conv1')
conv1 = tf.nn.relu(conv2d(x_input, W_conv1, 'conv1') + B_conv1)
conv1 = max_pool_2X2(conv1, 'conv1-pool')
conv1 = tf.nn.dropout(conv1, keep_prob)
#第二层卷积
W_conv2 = weight_variable([5,5,32,64], 'W_conv2')
B_conv2 = bias_variable([64], 'B_conv2')
conv2 = tf.nn.relu(conv2d(conv1, W_conv2,'conv2') + B_conv2)
conv2 = max_pool_2X2(conv2, 'conv2-pool')
conv2 = tf.nn.dropout(conv2, keep_prob)
#第三层卷积
W_conv3 = weight_variable([5,5,64,64], 'W_conv3')
B_conv3 = bias_variable([64], 'B_conv3')
conv3 = tf.nn.relu(conv2d(conv2, W_conv3, 'conv3') + B_conv3)
conv3 = max_pool_2X2(conv3, 'conv3-pool')
conv3 = tf.nn.dropout(conv3, keep_prob)
#全链接层
#每次池化后,图片的宽度和高度均缩小为原来的一半,进过上面的三次池化,宽度和高度均缩小8倍
W_fc1 = weight_variable([20*8*64, 1024], 'W_fc1')
B_fc1 = bias_variable([1024], 'B_fc1')
fc1 = tf.reshape(conv3, [-1, 20*8*64])
fc1 = tf.nn.relu(tf.add(tf.matmul(fc1, W_fc1), B_fc1))
fc1 = tf.nn.dropout(fc1, keep_prob)
#输出层
W_fc2 = weight_variable([1024, CAPTCHA_LEN * CHAR_SET_LEN], 'W_fc2')
B_fc2 = bias_variable([CAPTCHA_LEN * CHAR_SET_LEN], 'B_fc2')
output = tf.add(tf.matmul(fc1, W_fc2), B_fc2, 'output')
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=Y, logits=output))
optimizer = tf.train.AdamOptimizer(0.001).minimize(loss)
predict = tf.reshape(output, [-1, CAPTCHA_LEN, CHAR_SET_LEN], name='predict')
labels = tf.reshape(Y, [-1, CAPTCHA_LEN, CHAR_SET_LEN], name='labels')
#预测结果
#请注意 predict_max_idx 的 name,在测试model时会用到它
predict_max_idx = tf.argmax(predict, axis=2, name='predict_max_idx')
labels_max_idx = tf.argmax(labels, axis=2, name='labels_max_idx')
predict_correct_vec = tf.equal(predict_max_idx, labels_max_idx)
accuracy = tf.reduce_mean(tf.cast(predict_correct_vec, tf.float32))
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
steps = 0
for epoch in range(6000):
train_data, train_label = get_next_batch(64, 'train', steps)
sess.run(optimizer, feed_dict={X : train_data, Y : train_label, keep_prob:0.75})
if steps % 100 == 0:
test_data, test_label = get_next_batch(100, 'validate', steps)
acc = sess.run(accuracy, feed_dict={X : test_data, Y : test_label, keep_prob:1.0})
print("steps=%d, accuracy=%f" % (steps, acc))
if acc > 0.99:
saver.save(sess, MODEL_SAVE_PATH+"crack_captcha.model", global_step=steps)
break
steps += 1
if __name__ == '__main__':
image_filename_list, total = get_image_file_name(CAPTCHA_IMAGE_PATH)
random.seed(time.time())
#打乱顺序
random.shuffle(image_filename_list)
trainImageNumber = int(total * TRAIN_IMAGE_PERCENT)
#分成测试集
TRAINING_IMAGE_NAME = image_filename_list[ : trainImageNumber]
#和验证集
VALIDATION_IMAGE_NAME = image_filename_list[trainImageNumber : ]
train_data_with_CNN()
print('Training finished')
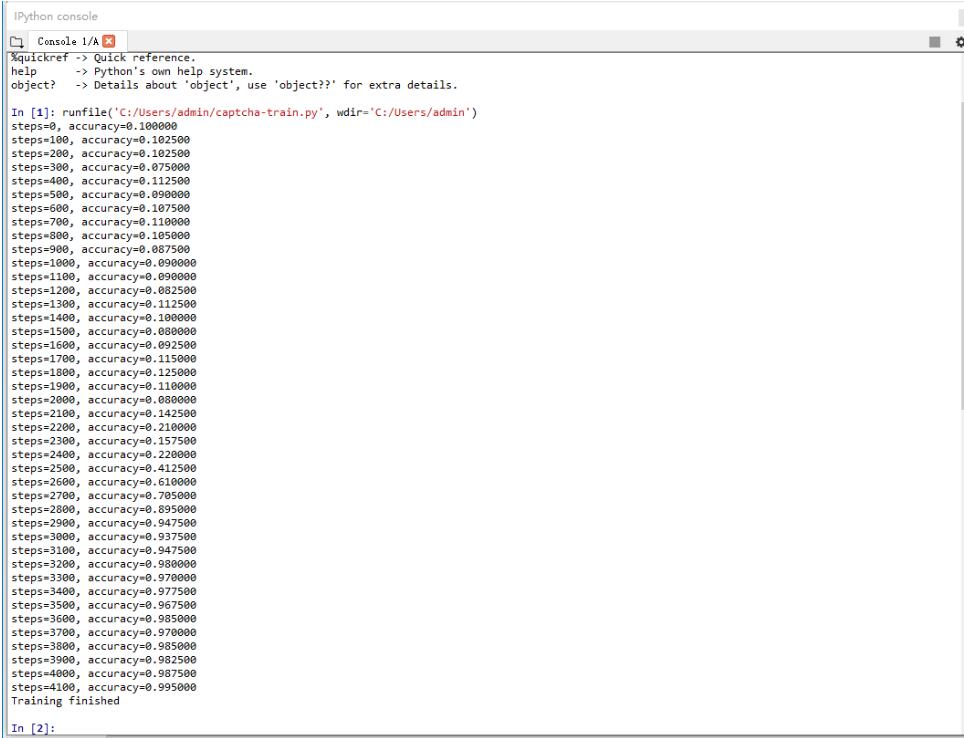
运行上面的代码,开始训练,训练要花些时间,如果没有GPU的话,会慢些,
训练完后,输出如下结果,经过4100次的迭代,训练出来的分类器模型在验证集上识别的准确率为99.5%
生成的模型文件如下,在模型测试时将用到这些文件
3. 测试模型
编写代码,对训练出来的模型进行测试
import tensorflow as tf
import numpy as np
from PIL import Image
import os
import matplotlib.pyplot as plt
CAPTCHA_LEN = 4
MODEL_SAVE_PATH = 'E:/Tensorflow/captcha/models/'
TEST_IMAGE_PATH = 'E:/Tensorflow/captcha/test/'
def get_image_data_and_name(fileName, filePath=TEST_IMAGE_PATH):
pathName = os.path.join(filePath, fileName)
img = Image.open(pathName)
#转为灰度图
img = img.convert("L")
image_array = np.array(img)
image_data = image_array.flatten()/255
image_name = fileName[0:CAPTCHA_LEN]
return image_data, image_name
def digitalStr2Array(digitalStr):
digitalList = []
for c in digitalStr:
digitalList.append(ord(c) - ord('0'))
return np.array(digitalList)
def model_test():
nameList = []
for pathName in os.listdir(TEST_IMAGE_PATH):
nameList.append(pathName.split('/')[-1])
totalNumber = len(nameList)
#加载graph
saver = tf.train.import_meta_graph(MODEL_SAVE_PATH+"crack_captcha.model-4100.meta")
graph = tf.get_default_graph()
#从graph取得 tensor,他们的name是在构建graph时定义的(查看上面第2步里的代码)
input_holder = graph.get_tensor_by_name("data-input:0")
keep_prob_holder = graph.get_tensor_by_name("keep-prob:0")
predict_max_idx = graph.get_tensor_by_name("predict_max_idx:0")
with tf.Session() as sess:
saver.restore(sess, tf.train.latest_checkpoint(MODEL_SAVE_PATH))
count = 0
for fileName in nameList:
img_data, img_name = get_image_data_and_name(fileName, TEST_IMAGE_PATH)
predict = sess.run(predict_max_idx, feed_dict={input_holder:[img_data], keep_prob_holder : 1.0})
filePathName = TEST_IMAGE_PATH + fileName
print(filePathName)
img = Image.open(filePathName)
plt.imshow(img)
plt.axis('off')
plt.show()
predictValue = np.squeeze(predict)
rightValue = digitalStr2Array(img_name)
if np.array_equal(predictValue, rightValue):
result = '正确'
count += 1
else:
result = '错误'
print('实际值:{}, 预测值:{},测试结果:{}'.format(rightValue, predictValue, result))
print('\n')
print('正确率:%.2f%%(%d/%d)' % (count*100/totalNumber, count, totalNumber))
if __name__ == '__main__':
model_test()
对模型的测试结果如下,在测试集上识别的准确率为 94%
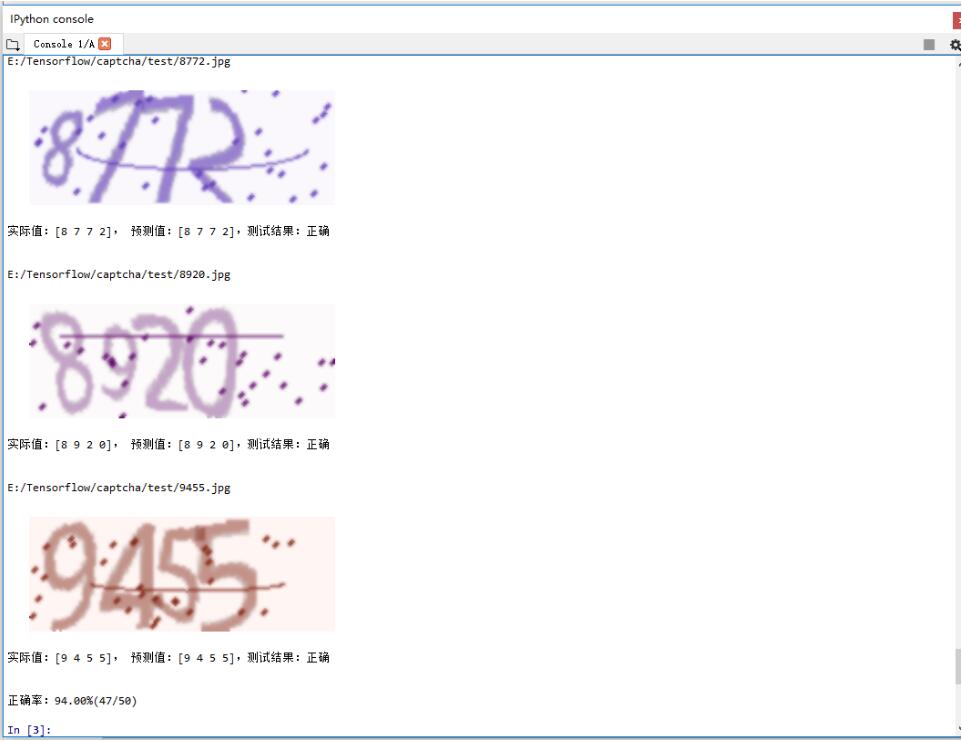
下面是两个识别错误的验证码
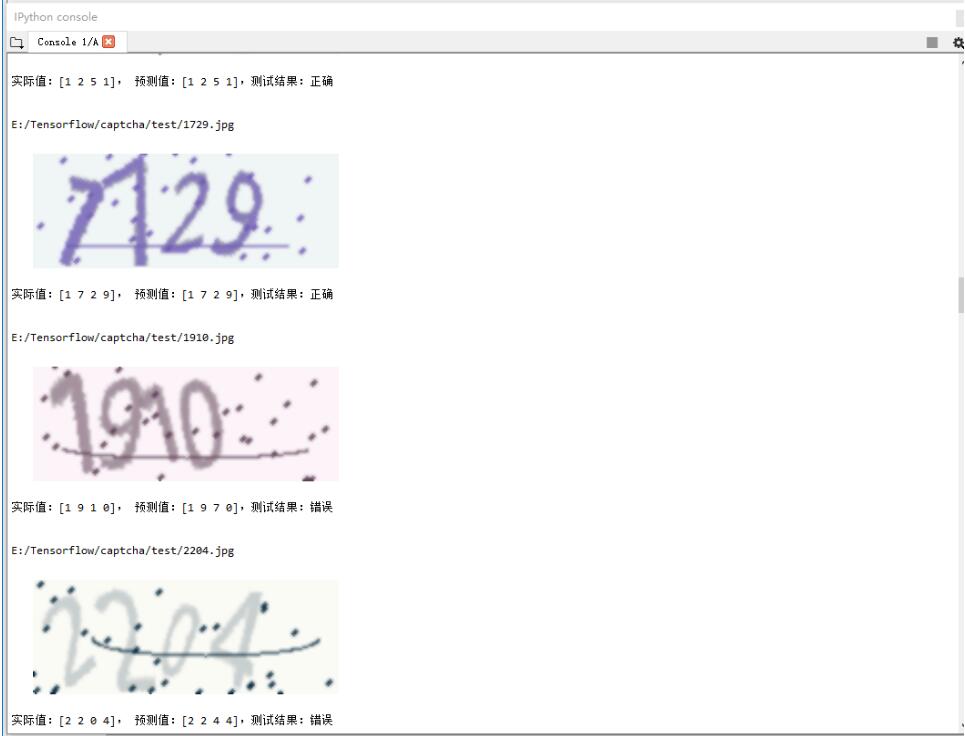
以上这篇利用Tensorflow构建和训练自己的CNN来做简单的验证码识别方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持易盾网络。