kaggle是一个为开发商和数据科学家提供举办机器学习竞赛、托管数据库、编写和分享代码的平台,在这上面有非常多的好项目、好资源可供机器学习、深度学习爱好者学习之用。
碰巧最近入门了一门非常的深度学习框架:pytorch,所以今天我和大家一起用pytorch实现一个图像识别领域的入门项目:猫狗图像识别。
深度学习的基础就是数据,咱们先从数据谈起。此次使用的猫狗分类图像一共25000张,猫狗分别有12500张,我们先来简单的瞅瞅都是一些什么图片。
我们从下载文件里可以看到有两个文件夹:train和test,分别用于训练和测试。以train为例,打开文件夹可以看到非常多的小猫图片,图片名字从0.jpg一直编码到9999.jpg,一共有10000张图片用于训练。
而test中的小猫只有2500张。仔细看小猫,可以发现它们姿态不一,有的站着,有的眯着眼睛,有的甚至和其他可识别物体比如桶、人混在一起。
同时,小猫们的图片尺寸也不一致,有的是竖放的长方形,有的是横放的长方形,但我们最终需要是合理尺寸的正方形。小狗的图片也类似,在这里就不重复了。
紧接着我们了解一下特别适用于图像识别领域的神经网络:卷积神经网络。学习过神经网络的同学可能或多或少地听说过卷积神经网络。这是一种典型的多层神经网络,擅长处理图像特别是大图像的相关机器学习问题。
卷积神经网络通过一系列的方法,成功地将大数据量的图像识别问题不断降维,最终使其能够被训练。CNN最早由Yann LeCun提出并应用在手写体识别上。
一个典型的CNN网络架构如下:
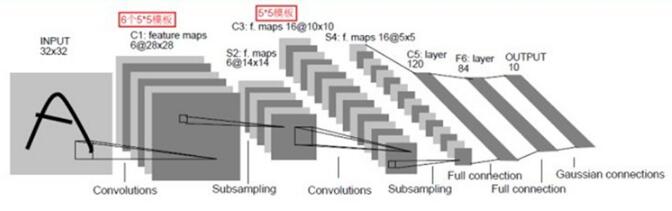
这是一个典型的CNN架构,由卷基层、池化层、全连接层组合而成。其中卷基层与池化层配合,组成多个卷积组,逐层提取特征,最终完成分类。
听到上述一连串的术语如果你有点蒙了,也别怕,因为这些复杂、抽象的技术都已经在pytorch中一一实现,我们要做的不过是正确的调用相关函数,
我在粘贴代码后都会做更详细、易懂的解释。
import os
import shutil
import torch
import collections
from torchvision import transforms,datasets
from __future__ import print_function, division
import os
import torch
import pylab
import pandas as pd
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from skimage import io, transform
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
# Ignore warnings
import warnings
warnings.filterwarnings("ignore")
plt.ion() # interactive mode
一个正常的CNN项目所需要的库还是蛮多的。
import math from PIL import Image class Resize(object): """Resize the input PIL Image to the given size. Args: size (sequence or int): Desired output size. If size is a sequence like (h, w), output size will be matched to this. If size is an int, smaller edge of the image will be matched to this number. i.e, if height > width, then image will be rescaled to (size * height / width, size) interpolation (int, optional): Desired interpolation. Default is ``PIL.Image.BILINEAR`` """ def __init__(self, size, interpolation=Image.BILINEAR): # assert isinstance(size, int) or (isinstance(size, collections.Iterable) and len(size) == 2) self.size = size self.interpolation = interpolation def __call__(self, img): w,h = img.size min_edge = min(img.size) rate = min_edge / self.size new_w = math.ceil(w / rate) new_h = math.ceil(h / rate) return img.resize((new_w,new_h))
这个称为Resize的库用于给图像进行缩放操作,本来是不需要亲自定义的,因为transforms.Resize已经实现这个功能了,但是由于目前还未知的原因,我的库里没有提供这个函数,所以我需要亲自实现用来代替transforms.Resize。
如果你的torch里面已经有了这个Resize函数就不用像我这样了。
data_transform = transforms.Compose([ Resize(84), transforms.CenterCrop(84), transforms.ToTensor(), transforms.Normalize(mean = [0.5,0.5,0.5],std = [0.5,0.5,0.5]) ]) train_dataset = datasets.ImageFolder(root = 'train/',transform = data_transform) train_loader = torch.utils.data.DataLoader(train_dataset,batch_size = 4,shuffle = True,num_workers = 4) test_dataset = datasets.ImageFolder(root = 'test/',transform = data_transform) test_loader = torch.utils.data.DataLoader(test_dataset,batch_size = 4,shuffle = True,num_workers = 4)
transforms是一个提供针对数据(这里指的是图像)进行转化的操作库,Resize就是上上段代码提供的那个类,主要用于把一张图片缩放到某个尺寸,在这里我们把需求暂定为要把图像缩放到84 x 84这个级别,这个就是可供调整的参数,大家为部署好项目以后可以试着修改这个参数,比如改成200 x 200,你就发现你可以去玩一盘游戏了~_~。
CenterCrop用于从中心裁剪图片,目标是一个长宽都为84的正方形,方便后续的计算。
ToTenser()就比较重要了,这个函数的目的就是读取图片像素并且转化为0-1的数字。
Normalize作为垫底的一步也很关键,主要用于把图片数据集的数值转化为标准差和均值都为0.5的数据集,这样数据值就从原来的0到1转变为-1到1。
class Net(nn.Module): def __init__(self): super(Net,self).__init__() self.conv1 = nn.Conv2d(3,6,5) self.pool = nn.MaxPool2d(2,2) self.conv2 = nn.Conv2d(6,16,5) self.fc1 = nn.Linear(16 * 18 * 18,800) self.fc2 = nn.Linear(800,120) self.fc3 = nn.Linear(120,2) def forward(self,x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1,16 * 18 * 18) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x net = Net()
好了,最复杂的一步就是这里了。在这里,我们首先定义了一个Net类,它封装了所以训练的步骤,包括卷积、池化、激活以及全连接操作。
__init__函数首先定义了所需要的所有函数,这些函数都会在forward中调用。我们从conv1说起。conv1实际上就是定义一个卷积层,3,6,5分别是什么意思?
3代表的是输入图像的像素数组的层数,一般来说就是你输入的图像的通道数,比如这里使用的小猫图像都是彩色图像,由R、G、B三个通道组成,所以数值为3;6代表的是我们希望进行6次卷积,每一次卷积都能生成不同的特征映射数组,用于提取小猫和小狗的6种特征。
每一个特征映射结果最终都会被堆叠在一起形成一个图像输出,再作为下一步的输入;5就是过滤框架的尺寸,表示我们希望用一个5 * 5的矩阵去和图像中相同尺寸的矩阵进行点乘再相加,形成一个值。
定义好了卷基层,我们接着定义池化层。池化层所做的事说来简单,其实就是因为大图片生成的像素矩阵实在太大了,我们需要用一个合理的方法在降维的同时又不失去物体特征,所以深度学习学者们想出了一个称为池化的技术,说白了就是从左上角开始,每四个元素(2 * 2)合并成一个元素,用这一个元素去代表四个元素的值,所以图像体积一下子降为原来的四分之一。
再往下一行,我们又一次碰见了一个卷基层:conv2,和conv1一样,它的输入也是一个多层像素数组,输出也是一个多层像素数组,不同的是这一次完成的计算量更大了,我们看这里面的参数分别是6,16,5。
之所以为6是因为conv1的输出层数为6,所以这里输入的层数就是6;16代表conv2的输出层数,和conv1一样,16代表着这一次卷积操作将会学习小猫小狗的16种映射特征,特征越多理论上能学习的效果就越好,大家可以尝试一下别的值,看看效果是否真的编变好。
conv2使用的过滤框尺寸和conv1一样,所以不再重复。最后三行代码都是用于定义全连接网络的,接触过神经网络的应该就不再陌生了,主要是需要解释一下fc1。
之前在学习的时候比较不理解的也是这一行,为什么是16 * 18 * 18呢?16很好理解,因为最后一次卷积生成的图像矩阵的高度就是16层,那18 * 18是怎么来的呢?我们回过头去看一行代码
transforms.CenterCrop(84)
在这行代码里我们把训练图像裁剪成一个84 * 84的正方形尺寸,所以图像最早输入就是一个3 * 84 * 84的数组。经过第一次5 * 5的卷积之后,我们可以得出卷积的结果是一个6 * 80 * 80的矩阵,这里的80就是因为我们使用了一个5 * 5的过滤框,当它从左上角第一个元素开始卷积后,过滤框的中心是从2到78,并不是从0到79,所以结果就是一个80 * 80的图像了。
经过一个池化层之后,图像尺寸的宽和高都分别缩小到原来的1/2,所以变成40 * 40。
紧接着又进行了一次卷积,和上一次一样,长宽都减掉4,变成36 * 36,然后应用了最后一层的池化,最终尺寸就是18 * 18。
所以第一层全连接层的输入数据的尺寸是16 * 18 * 18。三个全连接层所做的事很类似,就是不断训练,最后输出一个二分类数值。
net类的forward函数表示前向计算的整个过程。forward接受一个input,返回一个网络输出值,中间的过程就是一个调用init函数中定义的层的过程。
F.relu是一个激活函数,把所有的非零值转化成零值。此次图像识别的最后关键一步就是真正的循环训练操作。
import torch.optim as optim
cirterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(),lr = 0.0001,momentum = 0.9)
for epoch in range(3):
running_loss = 0.0
for i,data in enumerate(train_loader,0):
inputs,labels = data
inputs,labels = Variable(inputs),Variable(labels)
optimizer.zero_grad()
outputs = net(inputs)
loss = cirterion(outputs,labels)
loss.backward()
optimizer.step()
running_loss += loss.data[0]
if i % 2000 == 1999:
print('[%d %5d] loss: %.3f' % (epoch + 1,i + 1,running_loss / 2000))
running_loss = 0.0
print('finished training!')
[1 2000] loss: 0.691 [1 4000] loss: 0.687 [2 2000] loss: 0.671 [2 4000] loss: 0.657 [3 2000] loss: 0.628 [3 4000] loss: 0.626 finished training!
在这里我们进行了三次训练,每次训练都是批量获取train_loader中的训练数据、梯度清零、计算输出值、计算误差、反向传播并修正模型。我们以每2000次计算的平均误差作为观察值。可以看到每次训练,误差值都在不断变小,逐渐学习如何分类图像。代码相对性易懂,这里就不再赘述了。
correct = 0
total = 0
for data in test_loader:
images,labels = data
outputs = net(Variable(images))
_,predicted = torch.max(outputs.data,1)
total += labels.size(0)
correct += (predicted == labels).sum()
print('Accuracy of the network on the 5000 test images: %d %%' % (100 * correct / total))
终于来到模型准确度验证了,这也是开篇提到的test文件夹的用途之所在。程序到这一步时,net是一个已经训练好的神经网络了。传入一个images矩阵,它会输出相应的分类值,我们拿到这个分类值与真实值做一个比较计算,就可以获得准确率。在我的计算机上当前准确率是66%,在你的机器上可能值有所不同但不会相差太大。
最后我们做一个小总结。在pytorch中实现CNN其实并不复杂,理论性的底层都已经完成封装,我们只需要调用正确的函数即可。当前模型中的各个参数都没有达到相对完美的状态,有兴趣的小伙伴可以多调整参数跑几次,训练结果不出意外会越来越好。
另外,由于在一篇文章中既要阐述CNN,又要贴项目代码会显得没有重点,我就没有两件事同时做,因为网上已经有很多很好的解释CNN的文章了,如果看了代码依然是满头雾水的小伙伴可以先去搜关于CNN的文章,再回过头来看项目代码应该会更加清晰。
第一次写关于自己的神经网络方面的文章,如有写得不好的地方请大家多多见谅。
以上这篇使用pytorch完成kaggle猫狗图像识别方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持易盾网络。