这几天考了大大小小几门课,教务系统又没有成绩通知功能,为了急切想知道自己挂了多少门,于是我写下这个脚本。 设计思路: 设计思路很简单,首先对已有的成绩进行处理,变为
这几天考了大大小小几门课,教务系统又没有成绩通知功能,为了急切想知道自己挂了多少门,于是我写下这个脚本。
设计思路:
设计思路很简单,首先对已有的成绩进行处理,变为list集合,然后定时爬取教务系统查成绩的页面,对爬取的成绩也处理成list集合,如果newList的长度增加了,就找出增加的部分,并通过邮件通知我。
脚本运行效果:
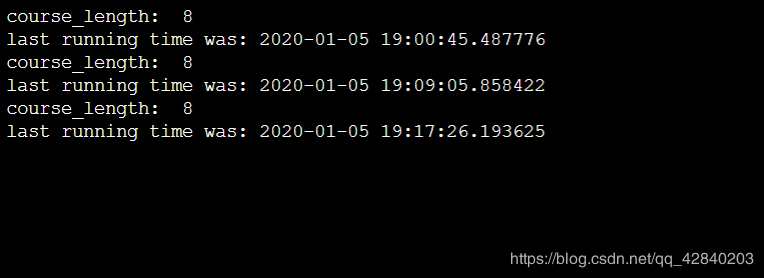
服务器:
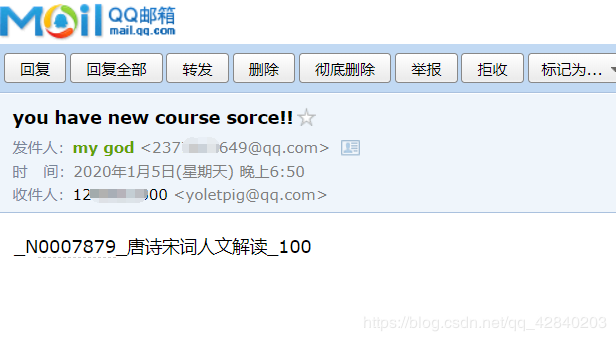
发送邮件通知:
代码如下:
import datetime
import time
from email.header import Header
import requests
import re
import smtplib
from email.mime.text import MIMEText
from bs4 import BeautifulSoup
def listener():
#在这里我通过模拟登陆的方式登陆
#一般来说这里填写的是username跟password
#但我们学校后台将用户名和密码进行了加密
#通过观察浏览器的请求数据跟页面源码猜出学校后台的加密方式
data={
#出于学校安全考虑,这里就不给出加密方式了
'encoded':'xxxxxxxxxxxxxxxxxxx'
}
session = requests.Session()
session.post('http://jwc.sgu.edu.cn/jsxsd/xk/LoginToXk',data=data)
#请求2019-2020-1学期的所有成绩
r_data = {
'kksj': '2019-2020-1',
'kcxz': '',
'kcmc': '',
'xsfs': 'all'
}
r = session.post('http://jwc.sgu.edu.cn/jsxsd/kscj/cjcx_list', data=r_data)
#对爬回来数据进行封装
soup = BeautifulSoup(r.text, 'html.parser')
#返回已有的成绩列表
oldList = toList(soup)
max = len(oldList)
#这里用死循环定时爬取成绩页面分析是否分布新成绩
while (True):
#post跟get方式不能乱用,不然数据会出错
r = session.post('http://jwc.sgu.edu.cn/jsxsd/kscj/cjcx_list',data=r_data)
soup = BeautifulSoup(r.text, 'lxml')
#print(soup.prettify())
length = len(soup.find_all(string=re.compile('2019-2020-1')))-1
print("course_length: ",length)
if (r.status_code == 200 and length != 0):
if (length > max):
#查询新出的成绩列表
newlist = toList(soup)
#获取两个列表不同之处,不同的就是新成绩
diflist = compareTwoList(oldList, newlist)
oldList=newlist
if diflist=='':
send("unkowned Error","unkowned Error")
else:
#有新成绩了,发送邮件通知我
send('you have new course sorce!!', diflist)
max = length
print('last running time was:',datetime.datetime.now())
#定时作用,500s查一次
time.sleep(500)
else:
# 发送邮件断开连接了 print("had disconnected...")
send("your server is disconnected!!!","your server is disconnected!!!")
break
def send(title,msg):
mail_host = 'smtp.qq.com'
# 你的qq邮箱名,没有.com
mail_user = '你的qq邮箱名,没有.com'
# 密码(部分邮箱为授权码)
mail_pass = '授权码'
# 邮件发送方邮箱地址
sender = '发送方邮箱地址'
# 邮件接受方邮箱地址,注意需要[]包裹,这意味着你可以写多个邮件地址群发
receivers = ['yoletpig@qq.com']
# 设置email信息
# 邮件内容设置
message = MIMEText(msg, 'plain', 'utf-8')
# 邮件主题
message['Subject'] = Header(title,'utf-8')
# 发送方信息
message['From'] = sender
# 接受方信息
message['To'] = receivers[0]
# 登录并发送邮件
try:
# smtpObj = smtplib.SMTP()
# # 连接到服务器
# smtpObj.connect(mail_host, 25)
smtpObj = smtplib.SMTP_SSL(mail_host)
# 登录到服务器
smtpObj.login(mail_user, mail_pass)
# 发送
smtpObj.sendmail(
sender,receivers,message.as_string())
# 退出
smtpObj.quit()
print('success')
except smtplib.SMTPException as e:
print('error', e) # 打印错误
def toList(soup):
flag = True
list = []
strs = ''
#对tr标签下的td进行遍历并取值
for tr in soup.find_all('tr'):
if flag:
flag = False;
continue
i = 1
for td in tr.stripped_strings:
if (i == 1 or i == 2):
i += 1
continue
strs += "_" + td
i += 1
list.append(strs)
strs = ''
return list
def compareTwoList(oldList,newList):
diflist=''
for sub in newList:
#判断是否唯一
if(oldList.count(sub)==0):
diflist = sub
break
return diflist
if __name__ == '__main__':
listener()
这个脚本不出意外的话要运行到我所有成绩出来为止,但我电脑肯定不会这么多天不关机呀,于是我就将这个脚本放到服务器上运行,如何在ubuntu下运行python文件,大家可以看一下我的另一篇文章:
yoletPig的博客:Ubuntu下运行python文件
总结
以上所述是小编给大家介绍的python爬虫爬取监控教务系统的思路详解,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对易盾网络网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!