grep命令是(global regular expression print,全局正则表达式输出)的缩写,它是Linux中功能最强大且最常用的命令之一。
grep在一个或多个输入文件中搜索与给定模式匹配的行,并将每条匹配行写入标准输出。 如果未指定文件,则grep将从标准输入读取,该输入通常是另一个命令的输出。
在本文中,我们将通过实际示例和最常见的GNU grep选项的详细说明,向您展示如何使用grep命令。
grep命令语法
grep命令的语法如下:
grep [OPTIONS] PATTERN [FILE...]
方括号中的项目是可选的。
- OPTIONS - 零个或多个选项。 Grep包含许多控制其行为的选项。
- PATTERN - 搜索模式。
- FILE - 零个或多个输入文件名。
为了能够搜索文件,运行命令的用户必须对该文件具有读取权限。
在文件中搜索字符串
grep命令最基本的用法是在文件中搜索字符串(文本)。
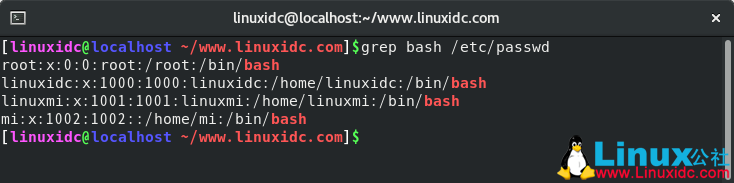
例如,要显示/etc/passwd文件中包含字符串bash的所有行,请运行以下命令:
[linuxidc@localhost ~/www.linuxidc.com]$ grep bash /etc/passwd
输出应如下所示:
如果字符串包含空格,则需要将其用单引号或双引号引起来:
[linuxidc@localhost ~/www.linuxidc.com]$grep "Gnome Display Manager" /etc/passwd
反转匹配(排除)
要显示与模式不匹配的行,请使用-v(或--invert-match)选项。
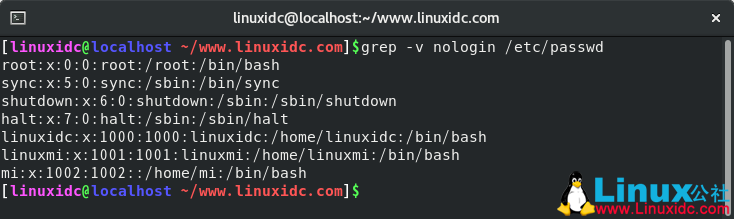
例如,要打印不包含字符串nologin的行,可以使用:
[linuxidc@localhost ~/www.linuxidc.com]$grep -v nologin /etc/passwd
使用Grep过滤命令的输出
可以使用grep通过管道过滤命令的输出,并且只有与给定模式匹配的行才会打印在终端上。
例如,要找出哪些系统以用户www-data的身份在系统上运行,可以使用以下ps命令:
[linuxidc@localhost ~/www.linuxidc.com]$ps -ef | grep www-data
linuxidc 3980 3865 0 22:26 pts/1 00:00:00 grep --color=auto www-data

您也可以在命令中链接多个管道。 如您在上面的输出中看到的,还有一行包含grep进程。 如果您不希望显示该行,则将输出传递到另一个grep实例,如下所示。
[linuxidc@localhost ~/www.linuxidc.com]$ps -ef | grep www-data | grep -v grep
递归搜索
要递归搜索模式,请使用-r选项(或--recursive)调用grep。 使用此选项时,grep将搜索指定目录中的所有文件,并跳过递归遇到的符号链接。
要跟随所有符号链接,请使用-R选项(或--dereference-recursive),而不是-r。
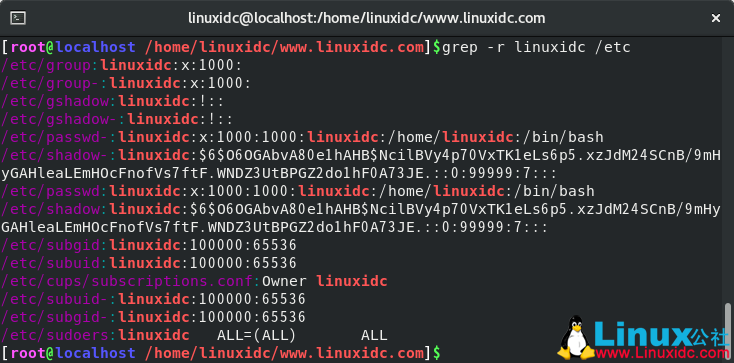
这是显示如何在/etc目录内的所有文件中搜索字符串linuxidc的示例:
[root@localhost /home/linuxidc/www.linuxidc.com]$grep -r linuxidc /etc
输出将包含以文件的完整路径为前缀的匹配行:
如果使用-R选项,则grep将跟随所有符号链接:
[root@ www.linuxidc.com]$grep -R linuxidc.com /etc
注意下面输出的最后一行。 当用-r调用grep时,不会打印该行,因为Nginx启用站点的目录中的文件是指向可用站点目录中的配置文件的符号链接。
/etc/hosts:127.0.0.1 node2.linuxidc.com
/etc/nginx/sites-available/linuxidc.com: server_name linuxidc.com www.linuxidc.com;
/etc/nginx/sites-enabled/linuxidc.com: server_name linuxidc.com www.linuxidc.com;
仅显示文件名
要取消默认grep输出并仅打印包含匹配模式的文件名,请使用-l(或--files-with-matches)选项。
以下命令在当前工作目录中搜索所有以.conf结尾的文件,并仅显示包含字符串linuxidc.com的文件的名称:
$grep -l linuxidc.com *.conf
输出将如下所示:
tmux.conf
haproxy.conf
-l选项通常与递归选项-R结合使用:
$grep -Rl linuxidc.com /tmp
不区分大小写的搜索
默认情况下,grep区分大小写。 这意味着将大写和小写字符视为不同的字符。
要在搜索时忽略大小写,请使用-i选项(或--ignore-case)调用grep。
例如,当搜索不带任何选项的Zebra时,以下命令将不显示任何输出,即有匹配的行:
$grep Zebra /usr/share/words
但是,如果使用-i选项执行不区分大小写的搜索,则它将同时匹配大小写字母:
$grep -i Zebra /usr/share/words
指定“ Zebra”将匹配该字符串的“ zebra”,“ ZEbrA”或任何其他大小写字母组合。
zebra
zebra's
zebras
搜索全词
搜索字符串时,grep将显示该字符串嵌入较大字符串中的所有行。
例如,如果您搜索“ gnu”,则将以较大的单词(例如“ cygnus”或“ magnum”)嵌入“ gnu”的所有行都将匹配:
$grep gnu /usr/share/words
cygnus
gnu
interregnum
lgnu9d
lignum
magnum
magnuson
sphagnum
wingnut
要仅返回指定字符串是整个单词(用非单词字符括起来)的那些行,请使用-w(或--word-regexp)选项。
文字字符包括字母数字字符(a-z,A-Z和0-9)和下划线(_)。 所有其他字符均视为非单词字符。
如果您运行与上述相同的命令,包括-w选项,则grep命令将仅返回其中包含gnu作为单独单词的那些行。
$grep -w gnu /usr/share/words
gnu
显示行号
-n(或--line-number)选项告诉grep显示包含与模式匹配的字符串的行的行号。 使用此选项时,grep将匹配项打印到以行号为前缀的标准输出。
例如,要显示/etc/services文件中的包含字符串bash并带有匹配行号的行,可以使用以下命令:
[linuxidc@localhost etc]$ grep -n 10000 /etc/services
下面的输出显示在行10423和10424上找到匹配项。
10445:ndmp 10000/tcp # Network Data Management Protocol
10446:ndmp 10000/udp # Network Data Management Protocol

Count函数匹配
若要将匹配行数打印到标准输出,请使用-c(或 --count)选项。
在下面的示例中,我们将计算以/usr/bin/zsh作为shell的帐户数量。
$regular expression$grep -c '/usr/bin/zsh' /etc/passwd
输出
4
安静模式
-q(或--quiet)告诉grep在安静模式下运行,不要在标准输出上显示任何内容。 如果找到匹配项,则该命令以状态0退出。这在要检查文件是否包含字符串并根据结果执行某些操作的shell脚本中使用grep时非常有用。
这是一个在安静模式下使用grep作为if语句中的测试命令的示例:
if grep -q PATTERN filename
then
echo pattern found
else
echo pattern not found
fi
Basic正则表达式
GNU Grep具有三个正则表达式功能集,Basic、 Extended 和 perl 兼容
默认情况下,grep将模式解释为基本的正则表达式,其中除元字符之外的所有字符实际上都是与自己匹配的正则表达式。
以下是最常用的元字符的列表:
使用^(插入符号)符号可在行首匹配表达式。 在下面的示例中,仅当字符串kangaroo出现在行的开头时才匹配。
$grep "^kangaroo" file.txt
使用$(美元)符号来匹配行尾的表达式。 在下面的示例中,仅当字符串kangaroo出现在行的最后时才匹配。
$grep "kangaroo$" file.txt
使用.(点)符号以匹配任何单个字符。 例如,要匹配以kan开头,然后有两个字符并以字符串roo结尾的任何内容,可以使用以下模式:
$grep "kan..roo" file.txt
使用[](括号)来匹配括号中包含的任何单个字符。 例如,找到包含accept或“ accent”的行,可以使用以下模式:
$grep "acce[np]t" file.txt
使用[^]来匹配不在括号内的任何单个字符。下面的模式将匹配任何包含co(any_letter_except_l)a的字符串组合,如coca、cobalt等,但不匹配包含cola的行,
$grep "co[^l]a" file.txt
要转义下一个字符的特殊含义,请使用\(反斜杠)符号。
Extended正则表达式
要将模式解释为扩展的正则表达式,请使用-E(或--extended-regexp)选项。 扩展的正则表达式包括所有基本元字符,以及用于创建更复杂和更强大的搜索模式的其他元字符。 以下是一些示例:
匹配并提取给定文件中的所有电子邮件地址:
$grep -E -o "\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,6}\b" file.txt
匹配并提取给定文件中的所有有效IP地址:
$grep -E -o '(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)' file.txt
-o选项仅用于打印匹配的字符串。
搜索多个字符串(模式)
可以使用OR运算符|将两个或多个搜索模式结合在一起。
默认情况下,grep将模式解释为基本正则表达式,其中的元字符(例如|) 失去其特殊含义,必须使用反斜杠版本。
在以下示例中,我们正在Nginx日志错误文件中搜索所有出现的致命,错误和严重的单词:
$grep 'fatal\|error\|critical' /var/log/nginx/error.log
如果使用扩展正则表达式选项-E,则不应转义运算符|,如下所示:
$grep -E 'fatal|error|critical' /var/log/nginx/error.log
在匹配之前打印行
要在匹配行之前打印特定数量的行,请使用-B(或 --before-context)选项。
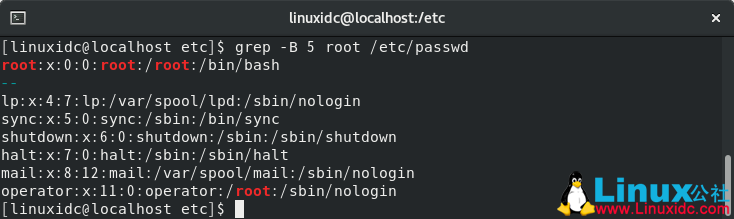
例如,要在匹配行之前显示5行前奏上下文,可以使用以下命令:
$grep -B 5 root /etc/passwd
匹配后打印行
若要在匹配行之后打印特定数量的行,请使用-A(或 --after-context)选项。
例如,要在匹配行之后显示尾随上下文的五行,可以使用以下命令:
$grep -A 5 root /etc/passwd
总结
grep命令允许您在文件内部搜索模式。 如果找到匹配项,则grep打印包含指定模式的行。
在Grep用户手册页上,还有更多有关Grep的知识。
如果您有任何问题或反馈,请随时发表评论。