基础
以下操作基于python 3.6 windows 10 环境下 通过
将通过实例来演示三者的区别
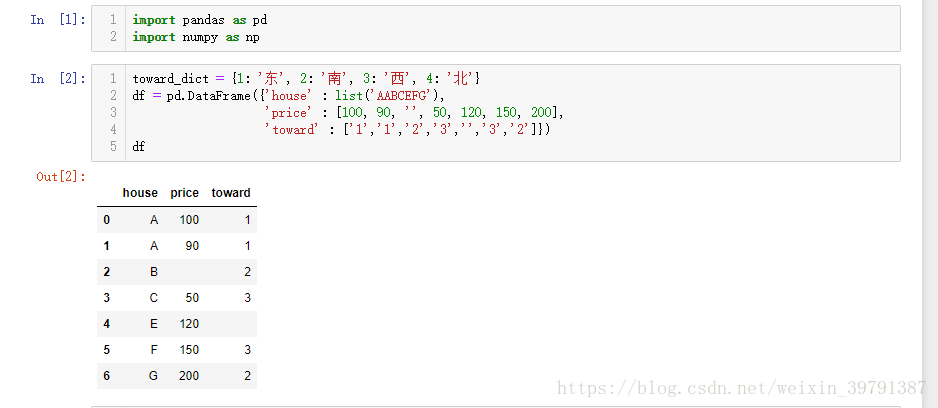
toward_dict = {1: '东', 2: '南', 3: '西', 4: '北'}
df = pd.DataFrame({'house' : list('AABCEFG'),
'price' : [100, 90, '', 50, 120, 150, 200],
'toward' : ['1','1','2','3','','3','2']})
df
map()方法
通过df.(tab)键,发现df的属性列表中有apply() 和 applymap(),但没有map().
map()是python 自带的方法, 可以对df某列内的元素进行操作, 我个人最常用的场景就是有toward_dict的映射关系 ,为df中的toward匹配出结果,
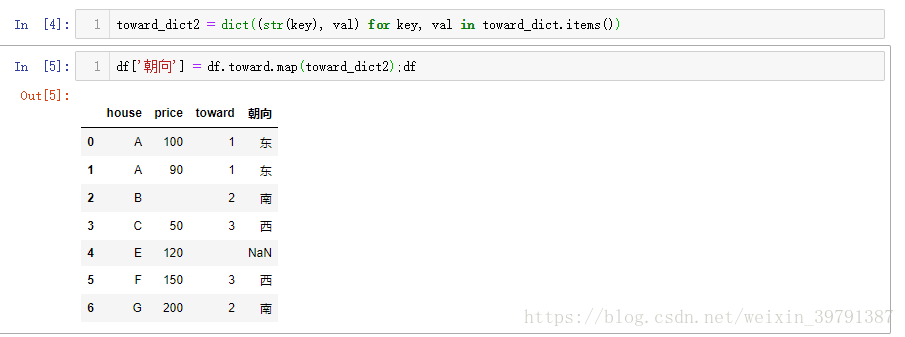
df['朝向'] = df.toward.map(toward_dict);df

结果就是没有匹配出来, why???
因为df.toward这列数字是str型的, toward_dict中的key是int型,下面修正操作下:两个思路:
第一种思路:`toward_dict`的key转换为str型 toward_dict2 = dict((str(key), val) for key, val in toward_dict.items())
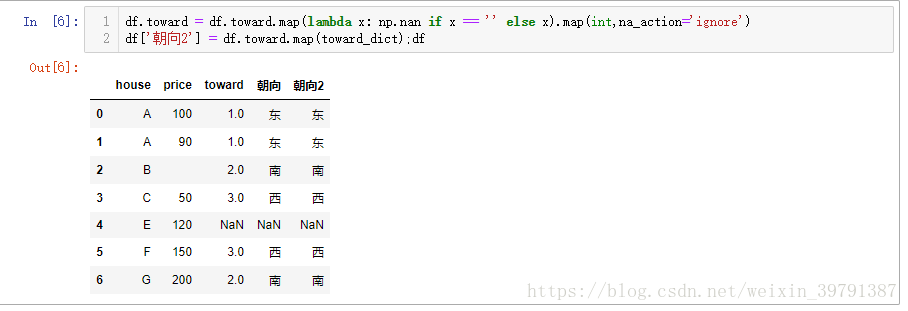
# 第二种思路, 将df.toward转为int型 df.toward = df.toward.map(lambda x: np.nan if x == '' else x).map(int,na_action='ignore') df['朝向2'] = df.toward.map(toward_dict);df
apply() 方法
更新时间: 2018-08-10
我目前的实际工作中使用apply()方法比较少, 所以整理的内容比较简陋, 后续涉及到数据分析方面可能会应用比较多些.
先将上面的测试中的map替换为apply,看看怎么样?
结果报错了, ValueError, 还是老老实实写实际操作例子吧 ?
参考DataFrame.apply官方文档
文档中第一个参数:
func : function
Function to apply to each column or row.
意思即是, 将传入的func应用到每一列或每一行,进行元素级别的运算
第二个参数:
axis : {0 or ‘index', 1 or ‘columns'}, default 0
Axis along which the function is applied:
0 or ‘index': apply function to each column. # 注意这里的解释
1 or ‘columns': apply function to each row.
举例:
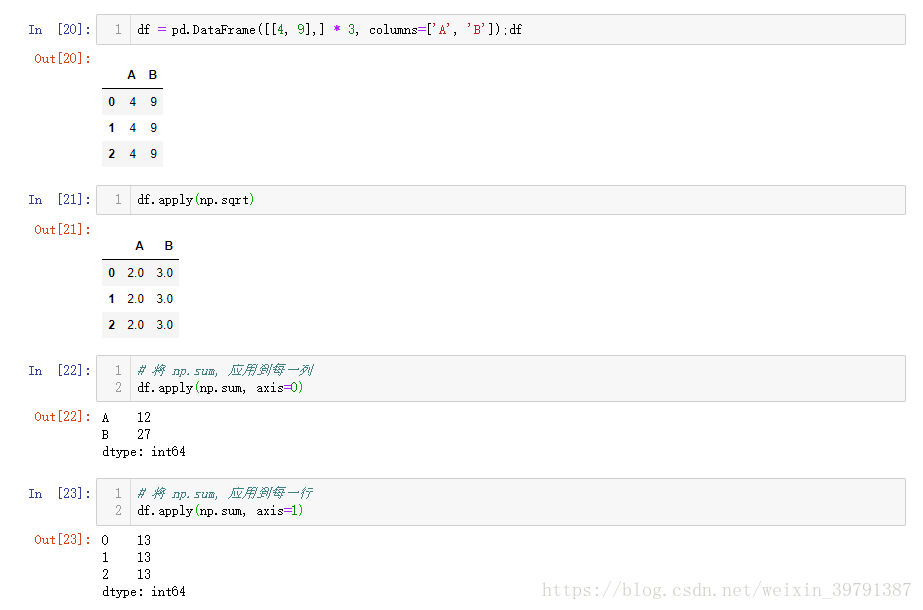
这个要特别注意的,
没有继续使用map里的DF, 是因为df.house是字符串, 不能进行np.sum运算,会报错.
2018年12月3日 新增:
最近在工作中使用到了pandas.apply()方法,更新如下:
背景介绍:
一个 df 有三个列需要进行计算,change_type 值 为1和0, 1为涨价,0为降价, price为现价, changed为涨降价的绝对值, 现求:涨降价的比例, 精确到0位,无小数位,
解决思路:
1.最主要的计算是: 涨降价的绝对值/ 原价
2.最主要的难点是: 涨价的原价 = 现价 - 绝对值
降价的原价 = 现价 + 绝对值
伪代码如下: 涨降价比例 = round(changed/(price 加上或减去 changed), 0)
就是我需求的结果了.
解决方案 如下:
以下代码经过win 10 环境 python3.6 版本测试通过
import pandas as pd
df = pd.DataFrame({'change_type' : [1,1,0,0,1,0],
'price' : [100, 90, 50, 120, 150, 200],
'changed' : [10,8,4,11,14,10]})
def get_round(change_type, price, changed_val):
"""
策略设计
"""
if change_type == 0:
return round(changed_val/(price + changed_val) * 100, 2)
elif change_type == 1:
return round(changed_val/(price - changed_val) * 100, 2)
else:
print(f'{change} is not exists')
# 策略实现
df['round'] = df.apply(lambda x: get_round(x['change_type'], x['price'], x['changed']),axis=1)
若有问题, 欢迎指正, 谢谢
applymap()
参考DataFrame.applymap官方文档:
func : callable
Python function, returns a single value from a single value.
文档很简单, 只有一个参数, 即传入的func方法
样例参考文档吧, 没有比这个更简单了
总结:
map() 方法是pandas.series.map()方法, 对DF中的元素级别的操作, 可以对df的某列或某多列, 可以参考文档
apply(func) 是DF的属性, 对DF中的行数据或列数据应用func操作.
applymap(func) 也是DF的属性, 对整个DF所有元素应用func操作
到此这篇关于pandas map(),apply(),applymap()区别解析的文章就介绍到这了,更多相关pandas map(),apply(),applymap()内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!