今日热榜:https://tophub.today/ 爬取数据及保存格式: 爬取后保存为.txt文件: 部分内容: 源码及注释: import requestsfrom bs4 import BeautifulSoupdef download_page(url): headers = {"User-Agent": "Mozilla/5.0
今日热榜:https://tophub.today/
爬取数据及保存格式:
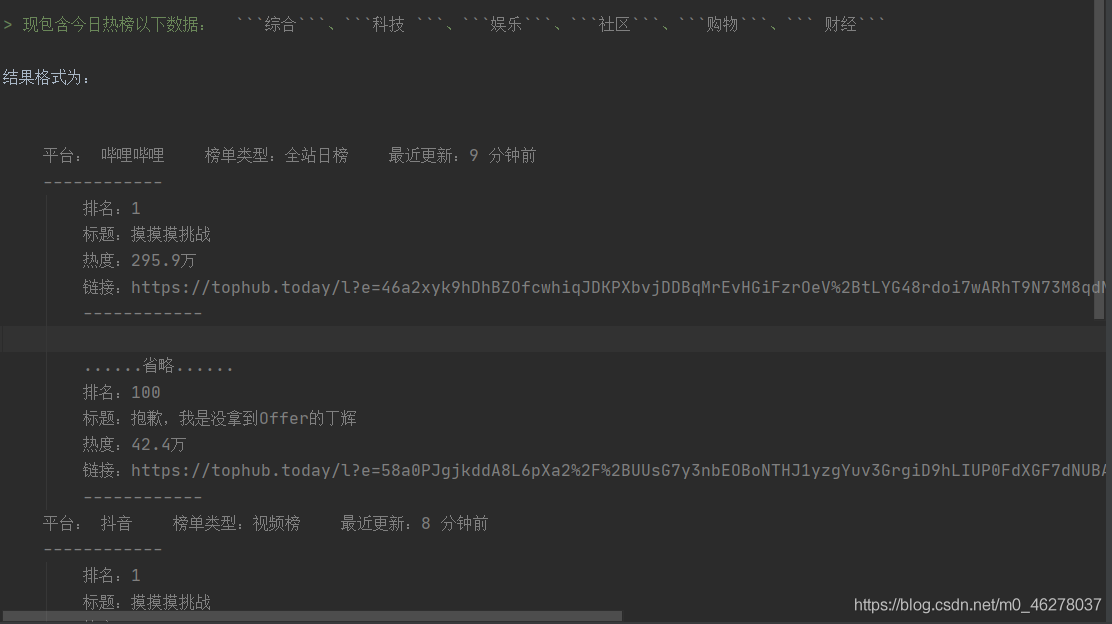
爬取后保存为.txt文件:
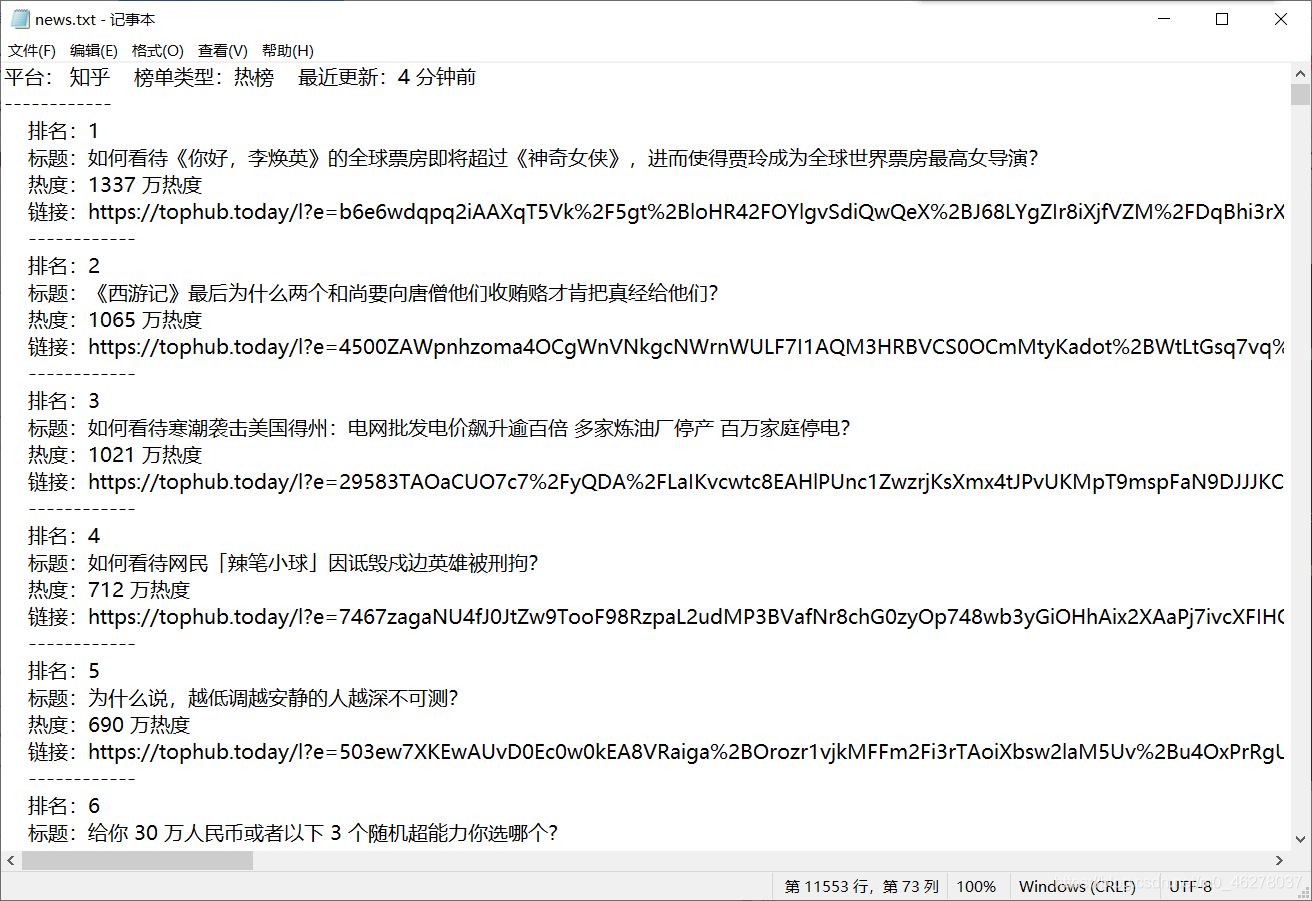
部分内容:
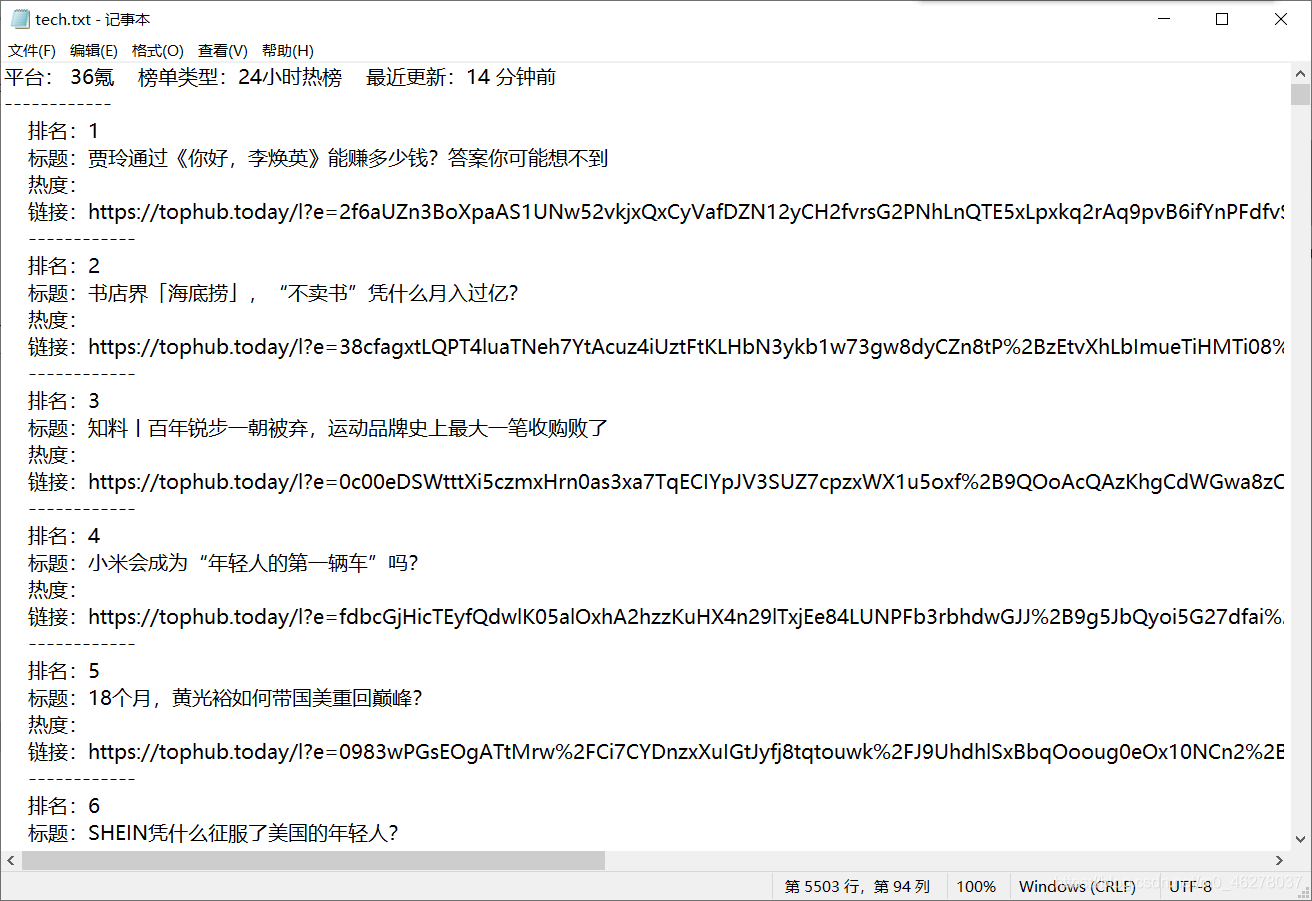
源码及注释:
import requests
from bs4 import BeautifulSoup
def download_page(url):
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}
try:
r = requests.get(url,timeout = 30,headers=headers)
return r.text
except:
return "please inspect your url or setup"
def get_content(html,tag):
output = """ 排名:{}\n 标题:{} \n 热度:{}\n 链接:{}\n ------------\n"""
output2 = """平台:{} 榜单类型:{} 最近更新:{}\n------------\n"""
num=[]
title=[]
hot=[]
href=[]
soup = BeautifulSoup(html, 'html.parser')
con = soup.find('div',attrs={'class':'bc-cc'})
con_list = con.find_all('div', class_="cc-cd")
for i in con_list:
author = i.find('div', class_='cc-cd-lb').get_text() # 获取平台名字
time = i.find('div', class_='i-h').get_text() # 获取最近更新
link = i.find('div', class_='cc-cd-cb-l').find_all('a') # 获取所有链接
gender = i.find('span', class_='cc-cd-sb-st').get_text() # 获取类型
save_txt(tag,output2.format(author, gender,time))
for k in link:
href.append(k['href'])
num.append(k.find('span', class_='s').get_text())
title.append(str(k.find('span', class_='t').get_text()))
hot.append(str(k.find('span', class_='e').get_text()))
for h in range(len(num)):
save_txt(tag,output.format(num[h], title[h], hot[h], href[h]))
def save_txt(tag,*args):
for i in args:
with open(tag+'.txt', 'a', encoding='utf-8') as f:
f.write(i)
def main():
# 综合 科技 娱乐 社区 购物 财经
page=['news','tech','ent','community','shopping','finance']
for tag in page:
url = 'https://tophub.today/c/{}'.format(tag)
html = download_page(url)
get_content(html,tag)
if __name__ == '__main__':
main()
到此这篇关于python爬虫今日热榜数据到txt文件的源码的文章就介绍到这了,更多相关python爬虫今日热榜数据内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!