1 算术运算
add(other)
比如进行数学运算加上具体的一个数字
data['open'].add(1) 2018-02-27 24.53 2018-02-26 23.80 2018-02-23 23.88 2018-02-22 23.25 2018-02-14 22.49
sub(other)
2 逻辑运算
2.1 逻辑运算符号
例如筛选data[“open”] > 23的日期数据
data[“open”] > 23返回逻辑结果
data["open"] > 23 2018-02-27 True 2018-02-26 False 2018-02-23 False 2018-02-22 False 2018-02-14 False # 逻辑判断的结果可以作为筛选的依据 data[data["open"] > 23].head()
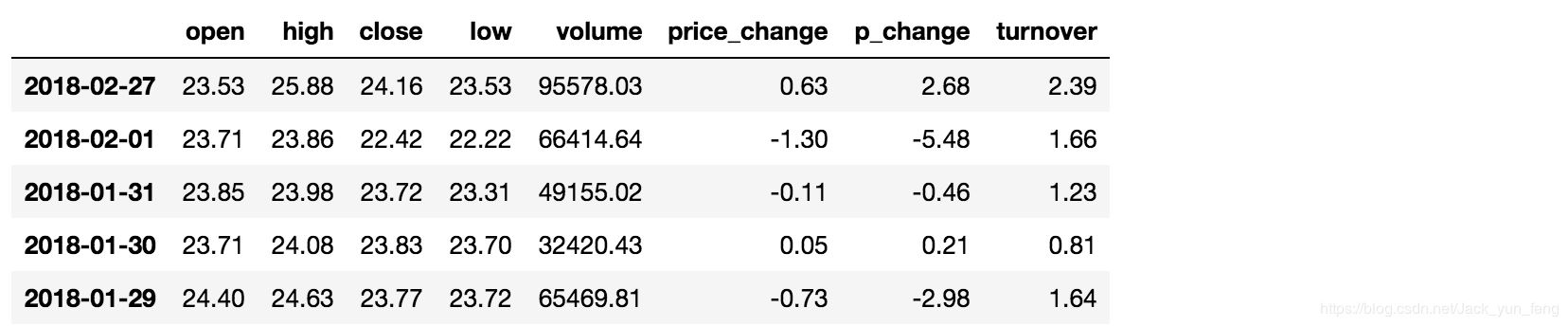
完成多个逻辑判断,
data[(data["open"] > 23) & (data["open"] < 24)].head()
2.2 逻辑运算函数
query(expr)
expr:查询字符串
通过query使得刚才的过程更加方便简单
# 以字符串形式
data.query("open<24 & open>23").head()
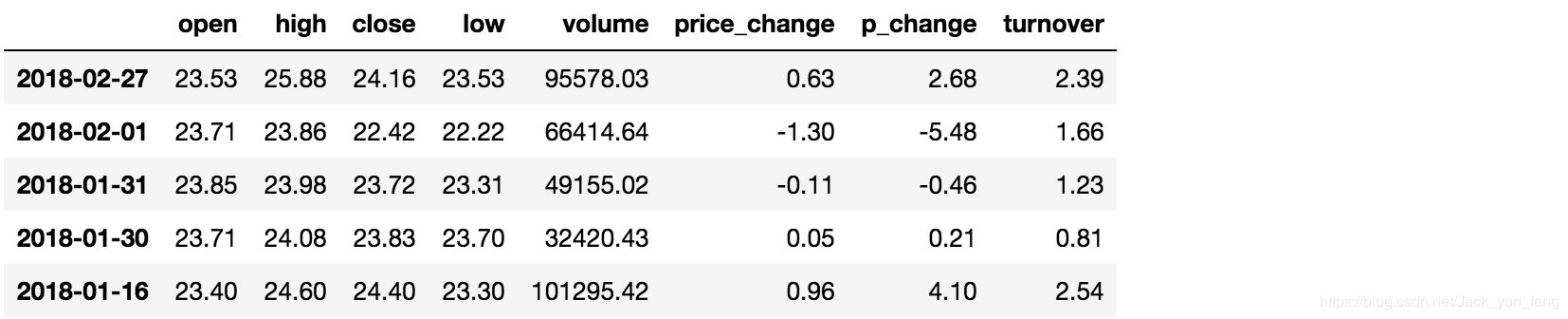
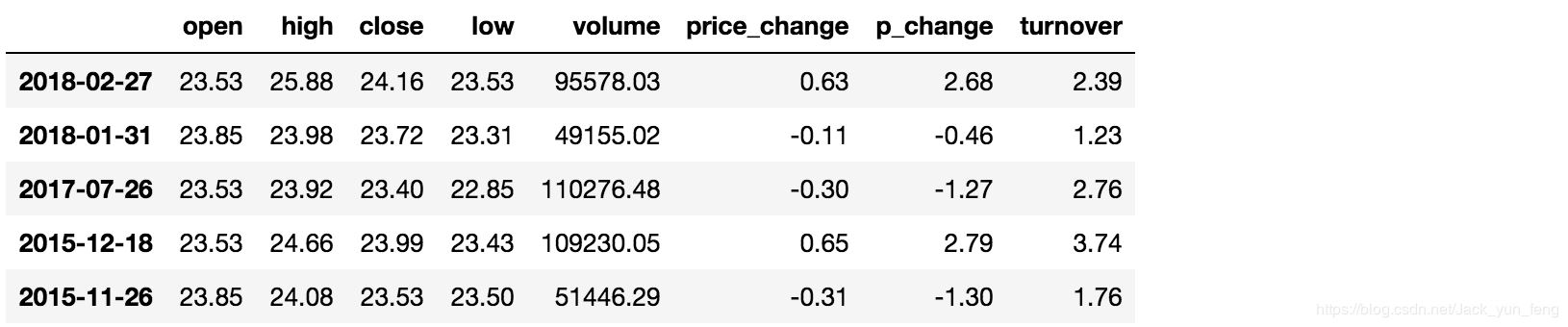
isin(values)
例如判断'open'是否为23.53和23.85
# 可以指定值进行一个判断,从而进行筛选操作 data[data["open"].isin([23.53, 23.85])]
3 统计运算
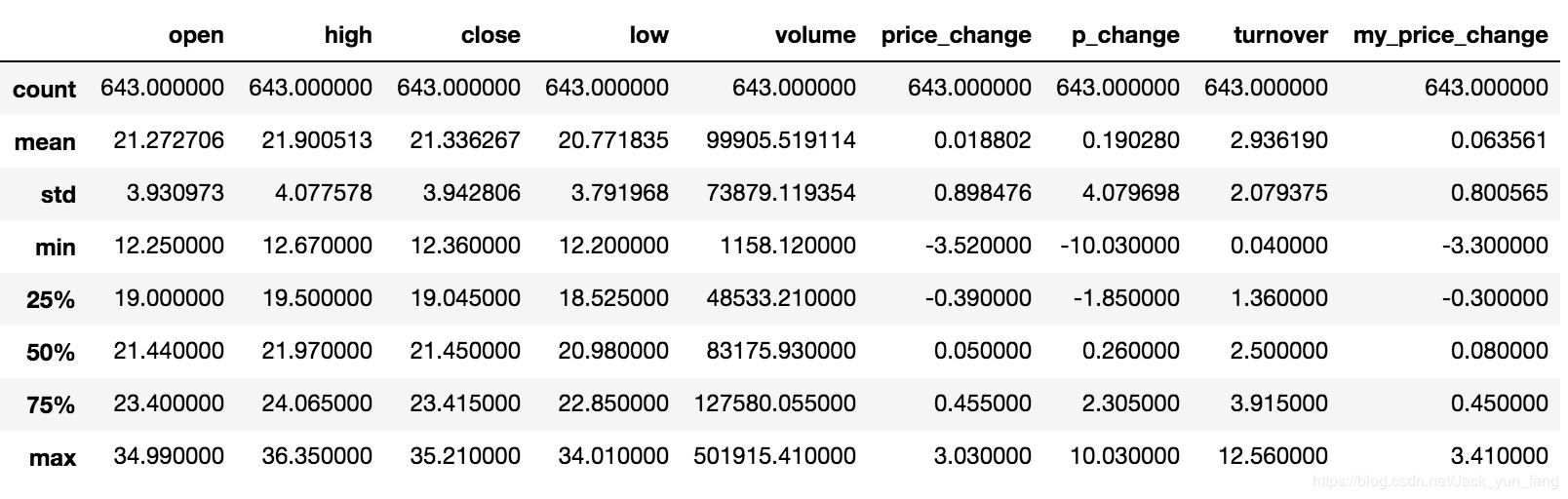
3.1 describe
综合分析: 能够直接得出很多统计结果,count, mean, std, min, max 等
# 计算平均值、标准差、最大值、最小值 data.describe()
3.2 统计函数
Numpy当中已经详细介绍,在这里我们演示min(最小值), max(最大值), mean(平均值), median(中位数), var(方差), std(标准差),mode(众数)结果:
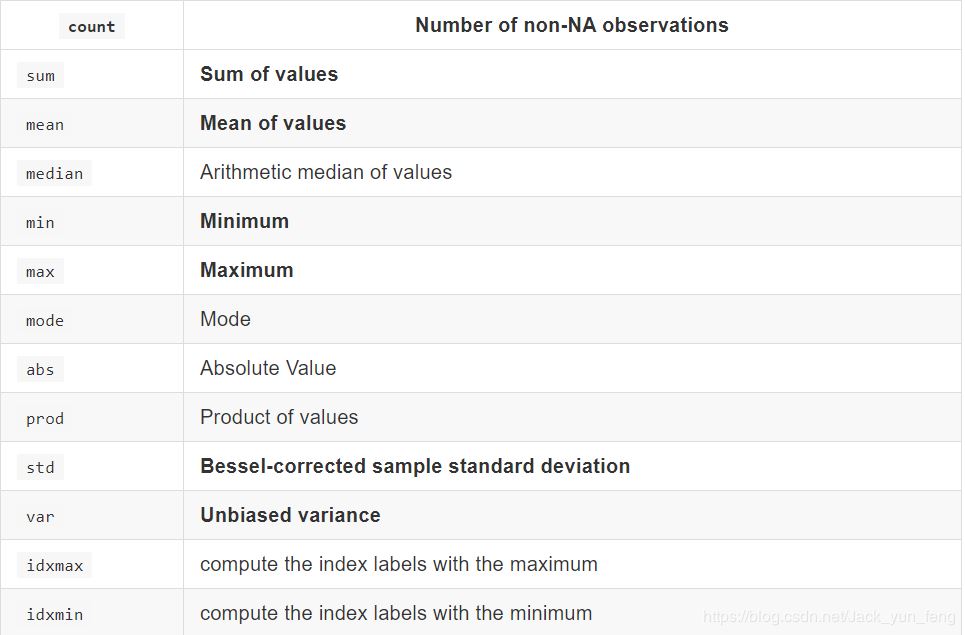
对于单个函数去进行统计的时候,坐标轴还是按照默认列“columns” (axis=0, default),如果要对行“index” 需要指定(axis=1)
max()、min()
# 使用统计函数:0 代表列求结果, 1 代表行求统计结果 data.max(0) open 34.99 high 36.35 close 35.21 low 34.01 volume 501915.41 price_change 3.03 p_change 10.03 turnover 12.56 my_price_change 3.41 dtype: float64
std()、var()
# 方差 data.var(0) open 1.545255e+01 high 1.662665e+01 close 1.554572e+01 low 1.437902e+01 volume 5.458124e+09 price_change 8.072595e-01 p_change 1.664394e+01 turnover 4.323800e+00 my_price_change 6.409037e-01 dtype: float64 # 标准差 data.std(0) open 3.930973 high 4.077578 close 3.942806 low 3.791968 volume 73879.119354 price_change 0.898476 p_change 4.079698 turnover 2.079375 my_price_change 0.800565 dtype: float64
median():中位数
中位数为将数据从小到大排列,在最中间的那个数为中位数。如果没有中间数,取中间两个数的平均值。
df = pd.DataFrame({'COL1' : [2,3,4,5,4,2],
'COL2' : [0,1,2,3,4,2]})
df.median()
COL1 3.5
COL2 2.0
dtype: float64
idxmax()、idxmin()
# 求出最大值的位置 data.idxmax(axis=0) open 2015-06-15 high 2015-06-10 close 2015-06-12 low 2015-06-12 volume 2017-10-26 price_change 2015-06-09 p_change 2015-08-28 turnover 2017-10-26 my_price_change 2015-07-10 dtype: object # 求出最小值的位置 data.idxmin(axis=0) open 2015-03-02 high 2015-03-02 close 2015-09-02 low 2015-03-02 volume 2016-07-06 price_change 2015-06-15 p_change 2015-09-01 turnover 2016-07-06 my_price_change 2015-06-15 dtype: object
3.3 累计统计函数
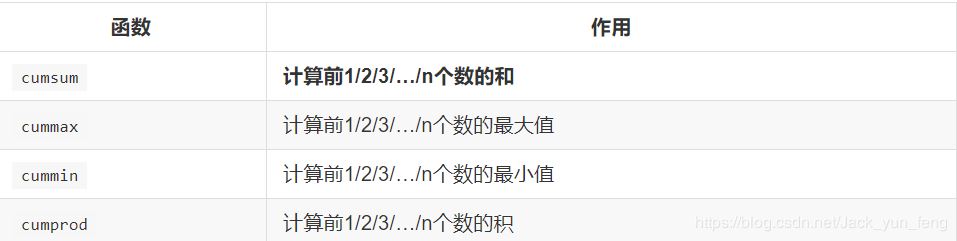
那么这些累计统计函数怎么用?
以上这些函数可以对series和dataframe操作
这里我们按照时间的从前往后来进行累计
排序
# 排序之后,进行累计求和 data = data.sort_index()
对p_change进行求和
stock_rise = data['p_change'] # plot方法集成了前面直方图、条形图、饼图、折线图 stock_rise.cumsum() 2015-03-02 2.62 2015-03-03 4.06 2015-03-04 5.63 2015-03-05 7.65 2015-03-06 16.16 2015-03-09 16.37 2015-03-10 18.75 2015-03-11 16.36 2015-03-12 15.03 2015-03-13 17.58 2015-03-16 20.34 2015-03-17 22.42 2015-03-18 23.28 2015-03-19 23.74 2015-03-20 23.48 2015-03-23 23.74
那么如何让这个连续求和的结果更好的显示呢?
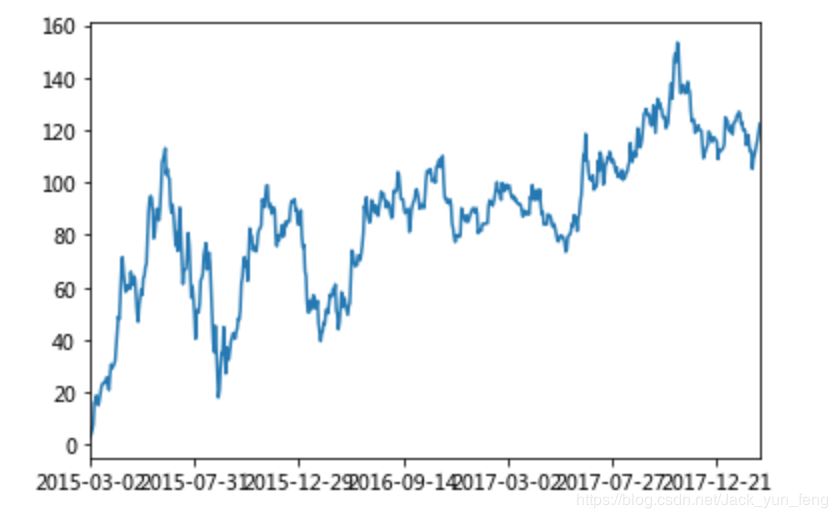
如果要使用plot函数,需要导入matplotlib.
import matplotlib.pyplot as plt # plot显示图形 stock_rise.cumsum().plot() # 需要调用show,才能显示出结果 plt.show()
关于plot,稍后会介绍API的选择
4 自定义运算
apply(func, axis=0)
- func:自定义函数
- axis=0:默认是列,axis=1为行进行运算
定义一个对列,最大值-最小值的函数
data[['open', 'close']].apply(lambda x: x.max() - x.min(), axis=0) open 22.74 close 22.85 dtype: float64
到此这篇关于pandas DataFrame运算的实现的文章就介绍到这了,更多相关pandas DataFrame运算内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!