粒子群算法是一种基于鸟类觅食开发出来的优化算法,它是从随机解出发,通过迭代寻找最优解,通过适应度来评价解的品质。

PSO算法的搜索性能取决于其全局探索和局部细化的平衡,这在很大程度上依赖于算法的控制参数,包括粒子群初始化、惯性因子w、最大飞翔速度和加速常数与等。
PSO算法具有以下优点:
不依赖于问题信息,采用实数求解,算法通用性强。
需要调整的参数少,原理简单,容易实现,这是PSO算法的最大优点。
协同搜索,同时利用个体局部信息和群体全局信息指导搜索。
收敛速度快, 算法对计算机内存和CPU要求不高。
更容易飞越局部最优信息。对于目标函数仅能提供极少搜索最优值的信息,在其他算法无法辨别搜索方向的情况下,PSO算法的粒子具有飞越性的特点使其能够跨过搜索平面上信息严重不足的障碍,飞抵全局最优目标值。比如Generalized Rosenbrock函数全局最小值在原占附近.但是此函数全局最优值与可到达的局部最优值之间右一条独长的山路,曲面山谷中点的最速下降方向几乎与到函数最小值的最佳方向垂直,找到全局最小值的可能性微乎其微, 但是PSO算法完全有可能找到全局最优值。
同时, PSO算法的缺点也是显而易见的:
算法局部搜索能力较差,搜索精度不够高。
算法不能绝对保证搜索到全局最优解。
PSO算法设计的具体步骤如下:
- 初始化粒子群(速度和位置)、惯性因子、加速常数、最大迭代次数、算法终止的最小允许误差。
- 评价每个粒子的初始适应值。
- 将初始适应值作为当前每个粒子的局部最优值,并将各适应值对应的位置作为每个粒子的局部最优值所在的位置。
- 将最佳初始适应值作为当前全局最优值,并将最佳适应值对应的位置作为全局最优值所在的位置。
- 依据公式更新每个粒子当前的飞翔速度。
- 对每个粒子的飞翔速度进行限幅处理,使之不能超过设定的最大飞翔速度。
- 依据公式更新每个粒子当前所在的位置。
- 比较当前每个粒子的适应值是否比历史局部最优值好,如果好,则将当前粒子适应值作为粒子的局部最优值,其对应的位置作为每个粒子的局部最优值所在的位置。
- 在当前群中找出全局最优值,并将当前全局最优值对应的位置作为粒子群的全局最优值所在的位置。
- 重复步骤(5)~(9),直到满足设定的最小误差或最大迭代次数
- 输出粒子群的全局最优值和其对应的位置以及每个粒子的局部最优值和其对应的位置。
本文中我们假设要求解一个维度为10的向量,这里的适应度函数采用简单的线性误差求和。
#基本粒子群算法
#vi+1 = w*vi+c1*r1*(pi-xi)+c2*r2*(pg-xi) 速度更新公式
#xi+1 = xi + a*vi+1 位置更新公式(一般a=1)
#w = wmax -(wmax-wmin)*iter/Iter 权重更新公式
#iter当前迭代次数 Iter最大迭代次数 c1、c2学习因子 r1、r2随机数 pi粒子当前最优位置 pg粒子群全局最优
#初始化 wmax=0.9 wmin=0.4 通常c1=c2=2 Iter对于小规模问题(10,20)对于大规模(100,200)
#算法优劣取决于w、c1和c2,迭代结束的条件是适应度函数的值符合具体问题的要求
#初始化粒子群,包括尺寸、速度和位置
#本算法假设想要的输出是长度为10的矩阵,y=[1.7]*10,适应度函数f(x)= |x-y| <=0.001符合要求
import numpy as np
swarmsize = 500
partlen = 10
wmax,wmin = 0.9,0.4
c1 = c2 = 2
Iter = 400
def getwgh(iter):
w = wmax - (wmax-wmin)*iter/Iter
return w
def getrange():
randompv = (np.random.rand()-0.5)*2
return randompv
def initswarm():
vswarm,pswarm = np.zeros((swarmsize,partlen)),np.zeros((swarmsize,partlen))
for i in range(swarmsize):
for j in range(partlen):
vswarm[i][j] = getrange()
pswarm[i][j] = getrange()
return vswarm,pswarm
def getfitness(pswarm):
pbest = np.zeros(partlen)
fitness = np.zeros(swarmsize)
for i in range(partlen):
pbest[i] = 1.7
for i in range(swarmsize):
yloss = pswarm[i] - pbest
for j in range(partlen):
fitness[i] += abs(yloss[j])
return fitness
def getpgfit(fitness,pswarm):
pgfitness = fitness.min()
pg = pswarm[fitness.argmin()].copy()
return pg,pgfitness
vswarm,pswarm = initswarm()
fitness = getfitness(pswarm)
pg,pgfit = getpgfit(fitness,pswarm)
pi,pifit = pswarm.copy(),fitness.copy()
for iter in range(Iter):
if pgfit <= 0.001:
break
#更新速度和位置
weight = getwgh(iter)
for i in range(swarmsize):
for j in range(partlen):
vswarm[i][j] = weight*vswarm[i][j] + c1*np.random.rand()*(pi[i][j]-pswarm[i][j]) + c2*np.random.rand()*(pg[j]-pswarm[i][j])
pswarm[i][j] = pswarm[i][j] + vswarm[i][j]
#更新适应值
fitness = getfitness(pswarm)
#更新全局最优粒子
pg,pgfit = getpgfit(fitness,pswarm)
#更新局部最优粒子
for i in range(swarmsize):
if fitness[i] < pifit[i]:
pifit[i] = fitness[i].copy()
pi[i] = pswarm[i].copy()
for j in range(swarmsize):
if pifit[j] < pgfit:
pgfit = pifit[j].copy()
pg = pi[j].copy()
print(pg)
print(pgfit)
下面的结果分别是迭代300次和400次的结果。
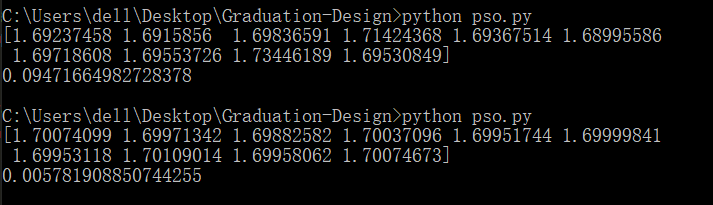
可以看到400次迭代虽然适应度没有达到预期,得到的向量已经很接近期望的结果了。
写在最后:粒子群算法最重要的参数就是惯性权重和学习因子,针对这两个参数有了新的优化粒子群算法(IPSO)。还有初始化粒子群时速度和位置范围的确定,包括种群的大小和迭代次数的选择,这些都是‘摸着石头过河',没有标准答案。
以上就是Python实现粒子群算法的示例的详细内容,更多关于Python 粒子群算法的资料请关注易盾网络其它相关文章!