一、前言 有一定数量类似如下截图所示的账单,利用 Python 批量识别电子账单数据,并将数据保存到Excel。 百度智能云接口 打开https://cloud.baidu.com/,如未注册请先注册,然后登录点击管
一、前言
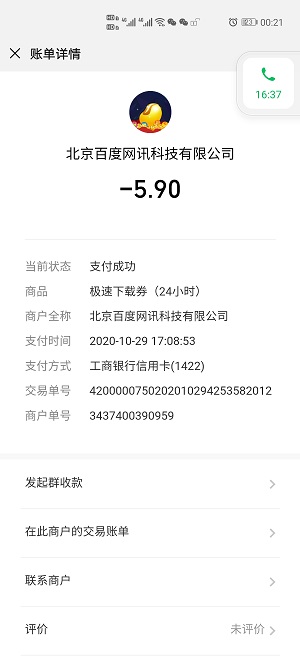
有一定数量类似如下截图所示的账单,利用 Python 批量识别电子账单数据,并将数据保存到Excel。
百度智能云接口
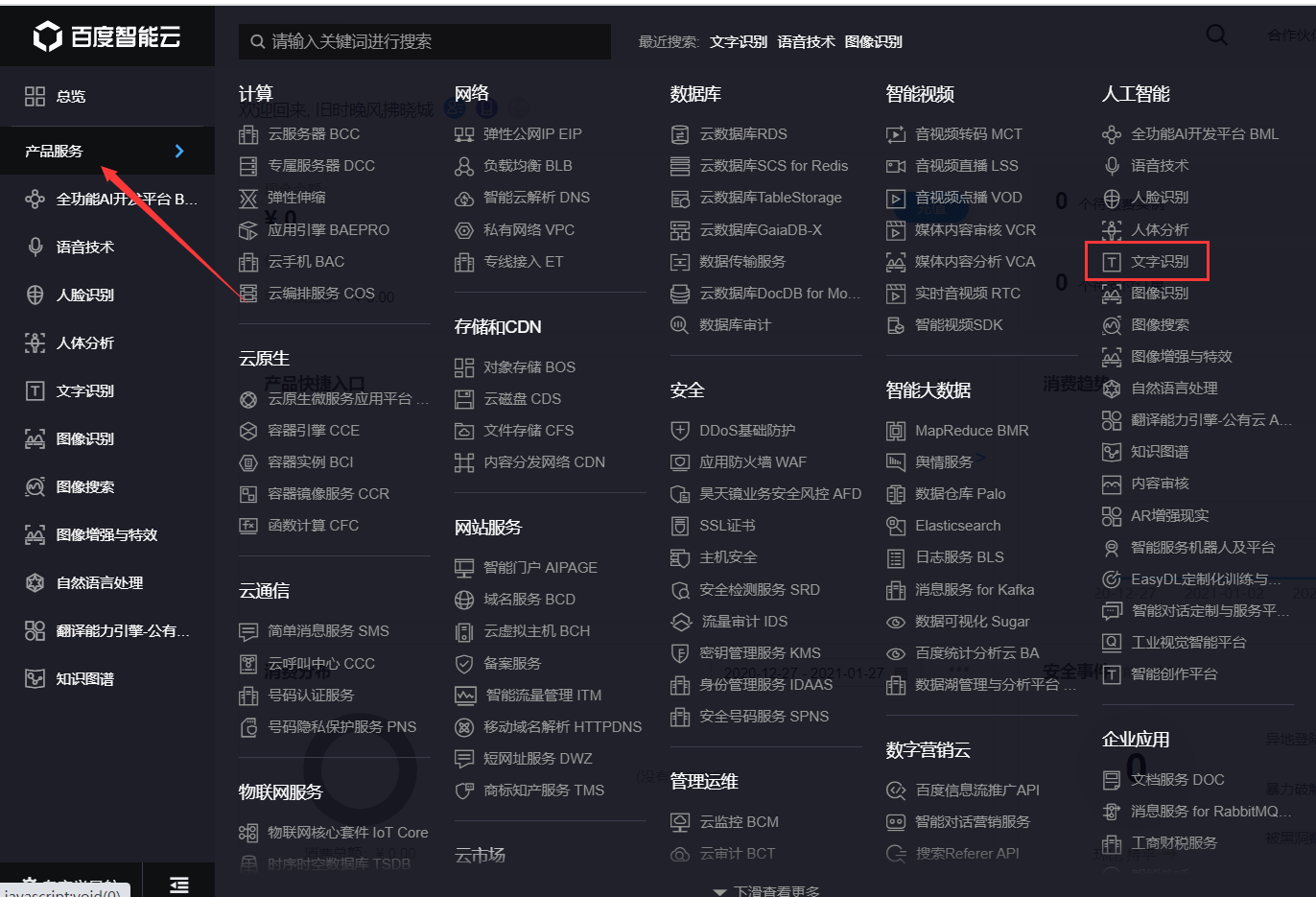
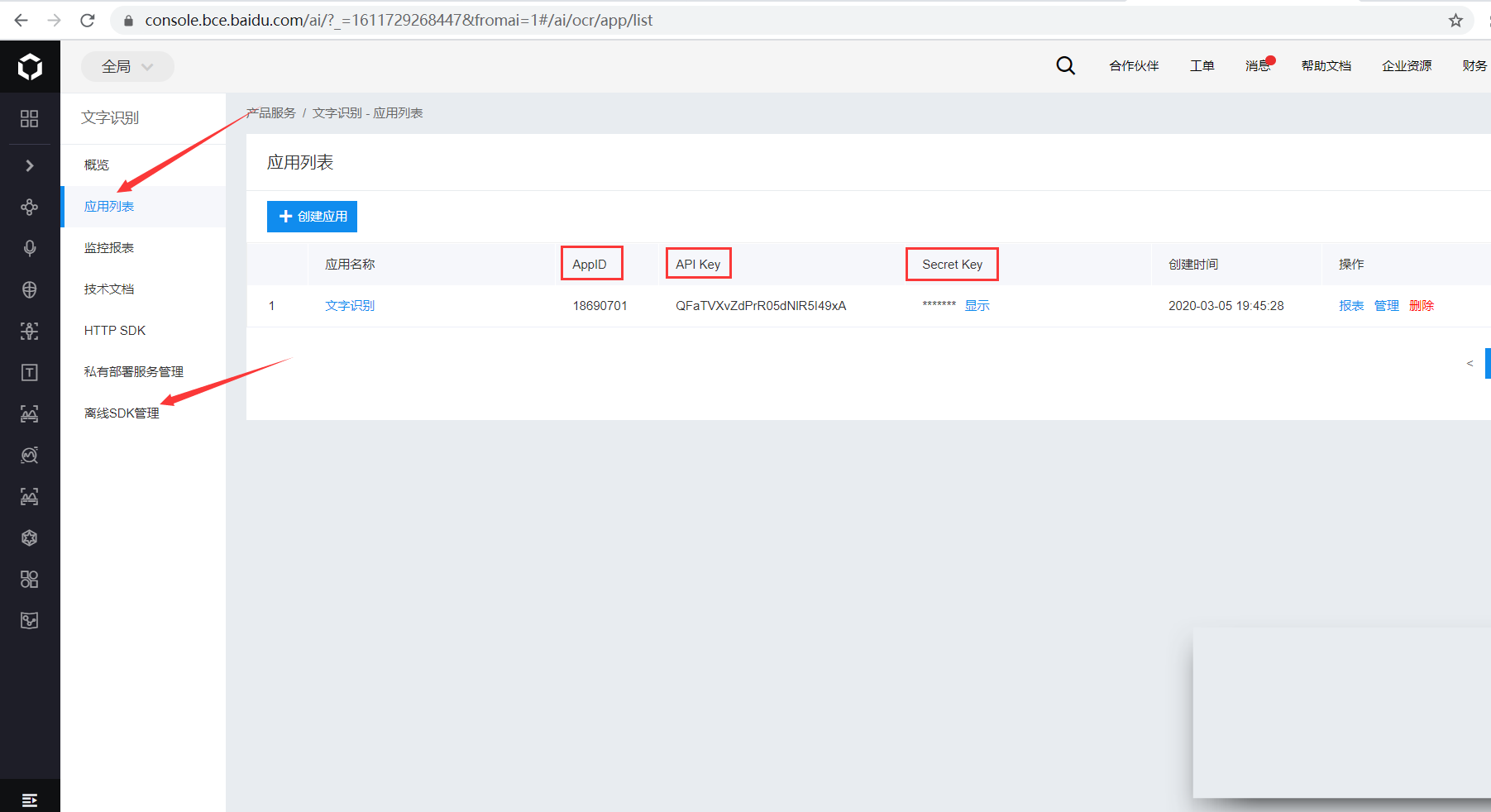
打开https://cloud.baidu.com/,如未注册请先注册,然后登录点击管理控制台,点击左侧产品服务→人工智能→文字识别,点击创建应用,输入应用名称如Baidu_OCR,选择用途如学习办公,最后进行简单应用描述,即可点击立即创建。会出现应用列表,包括AppID、API Key、Secret Key等信息,这些稍后会用到。
二、调用Baidu aip识别
首先需要安装百度的接口,命令行输入如下:
pip install baidu-aip -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
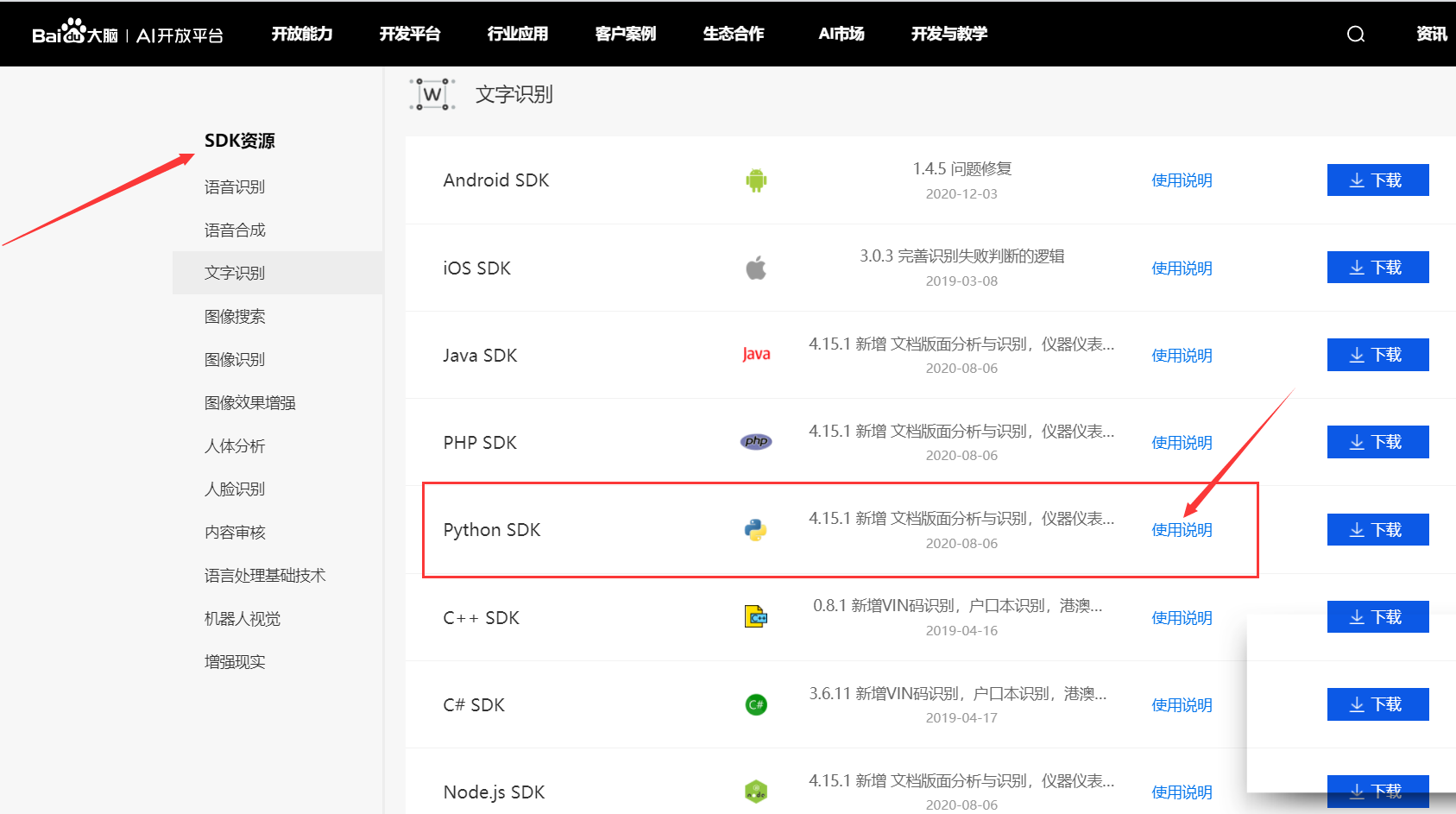
查看 Python 的 SDK 文档:
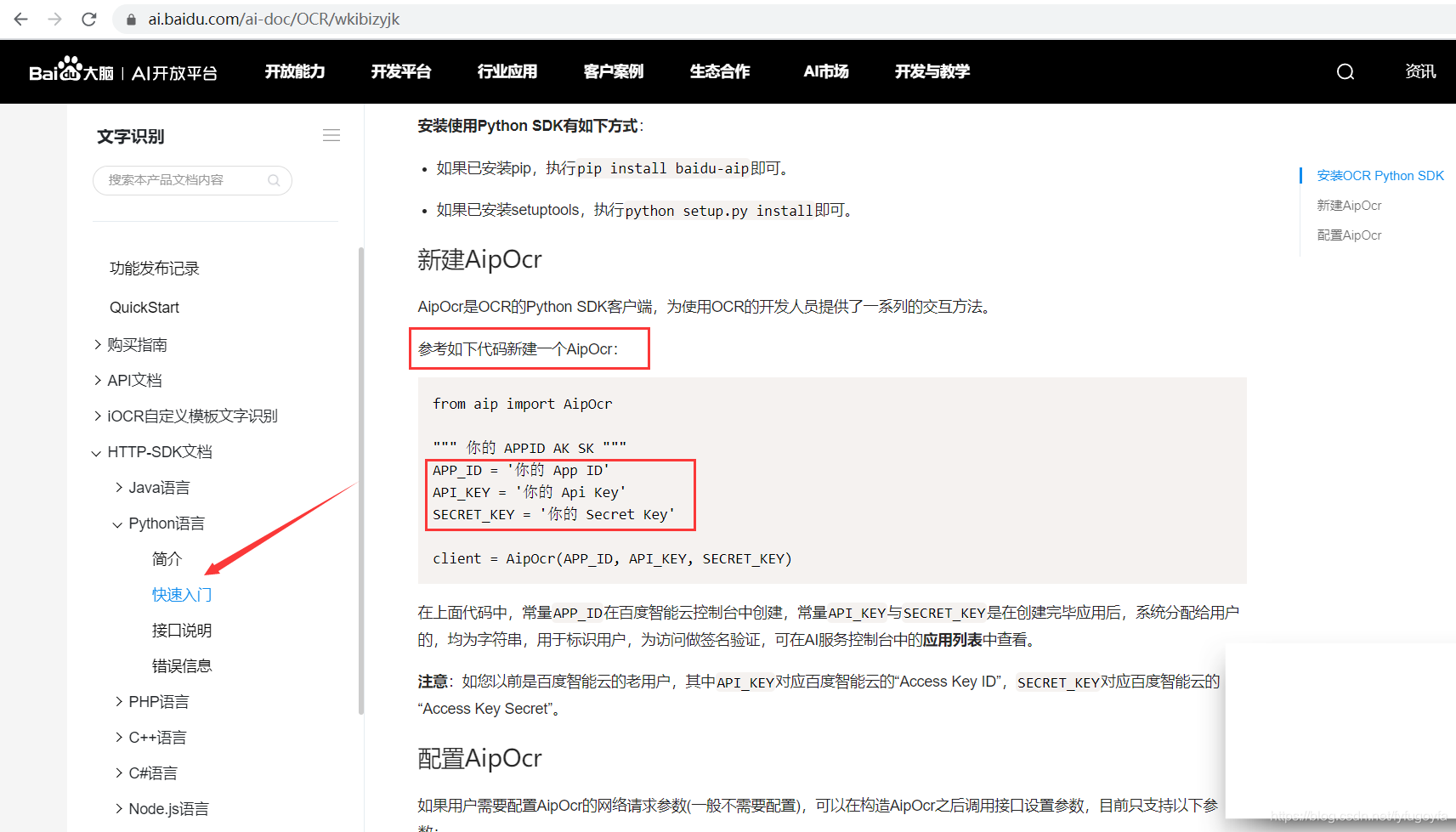
AipOcr是 OCR 的 Python SDK 客户端,为使用 OCR 的开发人员提供了一系列的交互方法。参考如下代码新建一个AipOcr:
from aip import AipOcr """ 你的 APPID AK SK """ APP_ID = '你的 App ID' API_KEY = '你的 Api Key' SECRET_KEY = '你的 Secret Key' client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
用户向服务请求识别某张图中的所有文字
""" 读取图片 """
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
image = get_file_content('example.jpg')
""" 调用通用文字识别, 图片参数为本地图片 """
client.basicGeneral(image)
""" 调用通用文字识别(高精度版) 图片参数为本地图片 """
client.basicAccurate(image)
识别出如下图片中的文字,示例如下:

from aip import AipOcr
# """ 改成你的 百度云服务的 ID AK SK """
APP_ID = '18690701'
API_KEY = 'QFaTVXvZdPrR05dNlR5I49xA'
SECRET_KEY = '*******************************'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
image = get_file_content('example.jpg')
# 调用通用文字识别, 图片参数为本地图片
result = client.basicGeneral(image)
print(result)
# 提取识别结果
info = '\n'.join([i['words'] for i in result['words_result']])
print(info)
结果如下:
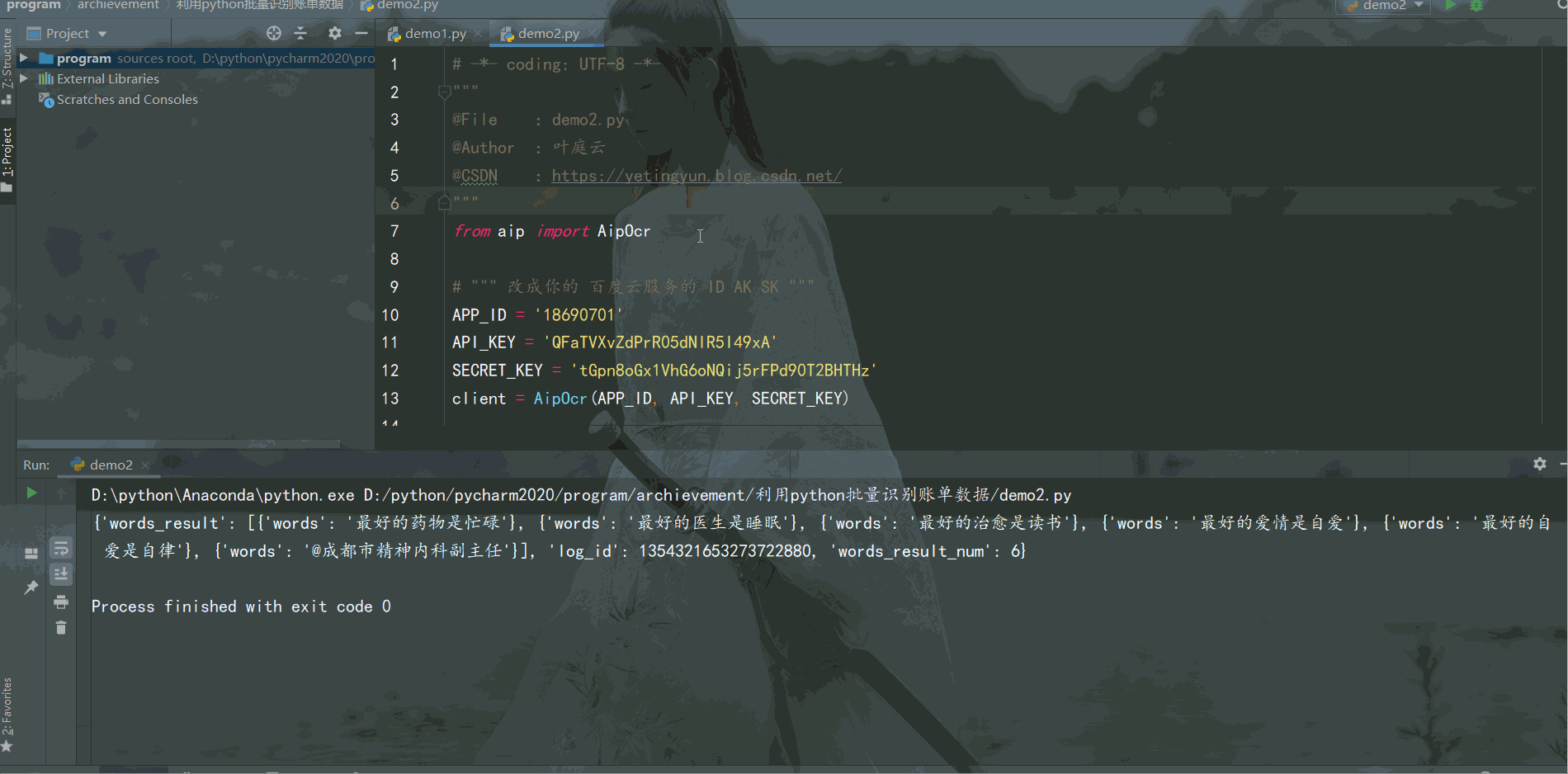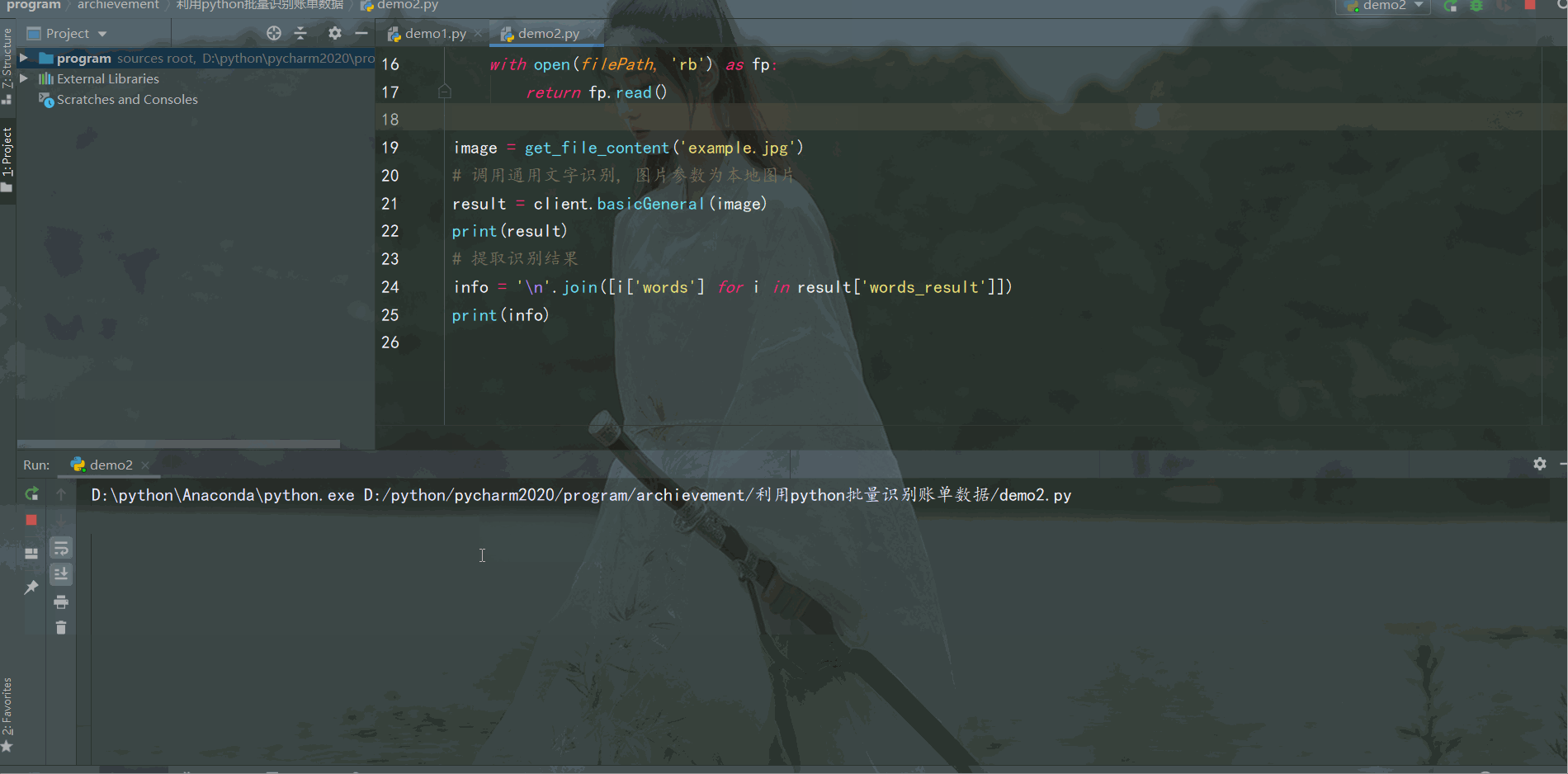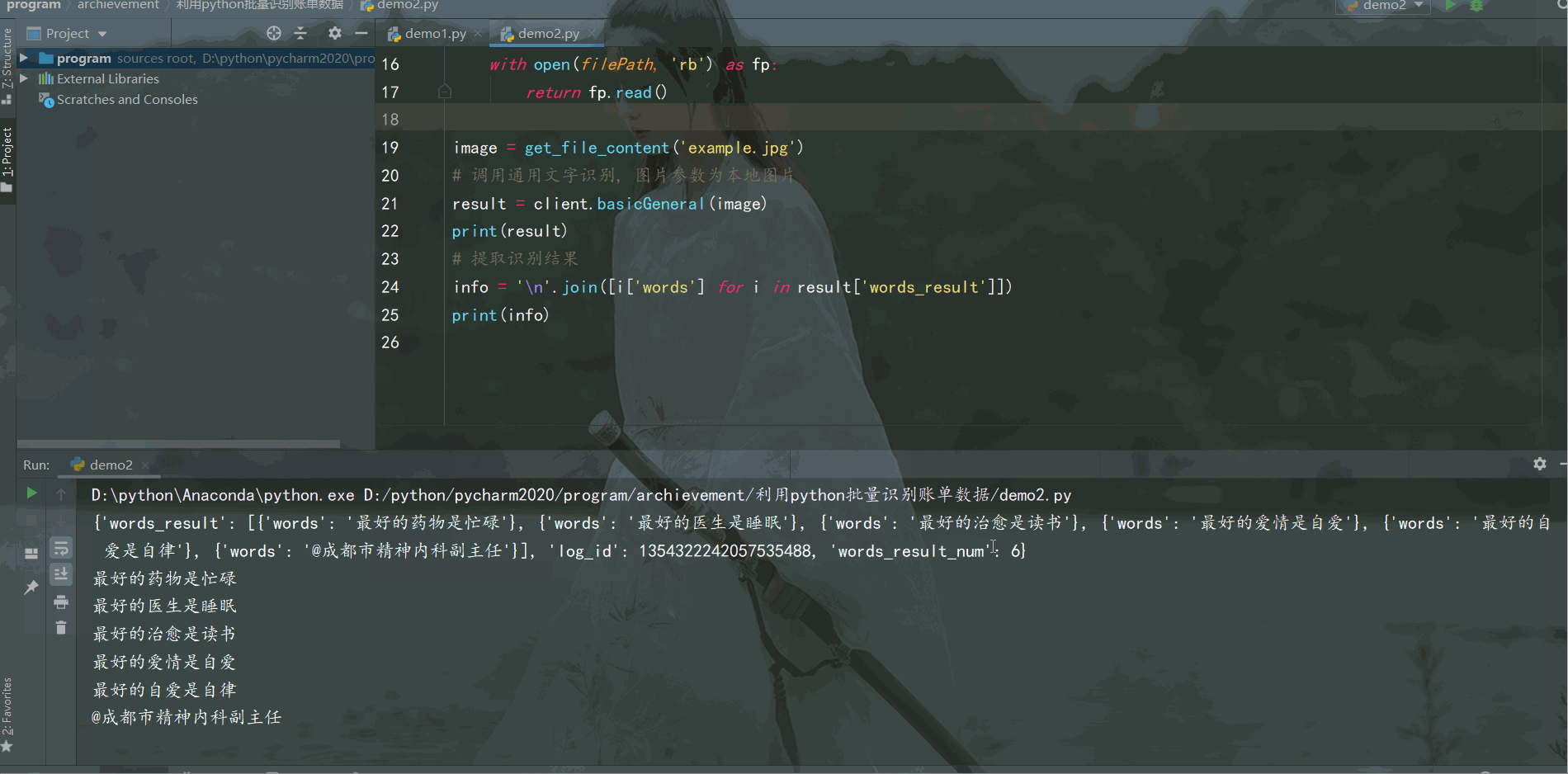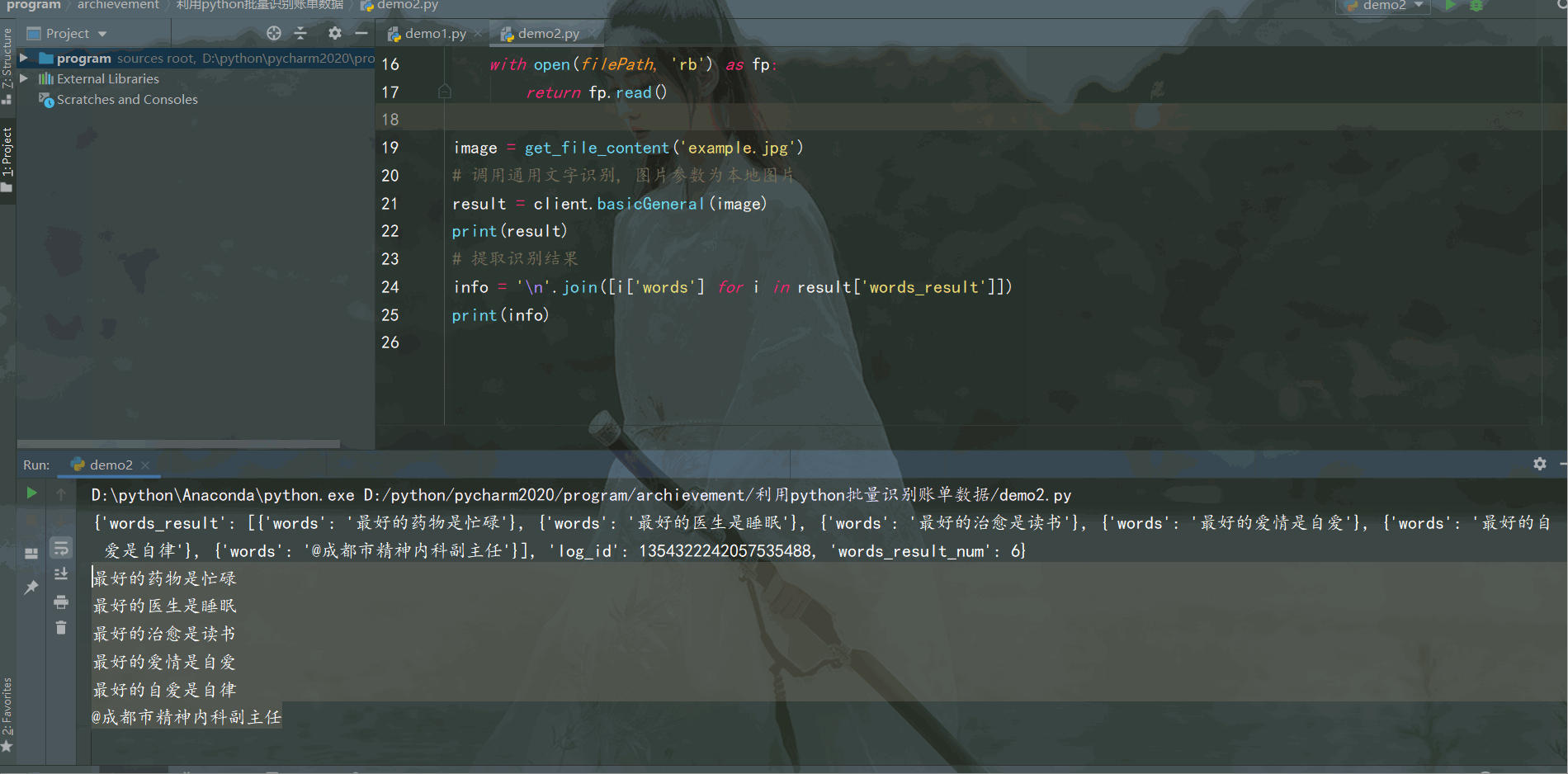
三、批量识别电子账单
获取所有待识别的电子账单图像
from pathlib import Path
# 换成你放图片的路径
p = Path(r'D:\test\test_img')
# 得到所有文件夹下 .jpg 图片
file = p.glob('**/*.jpg')
for img_file in file:
print(type(img_file)) # <class 'pathlib.WindowsPath'> 转成str
img_file = str(img_file)
print(img_file)
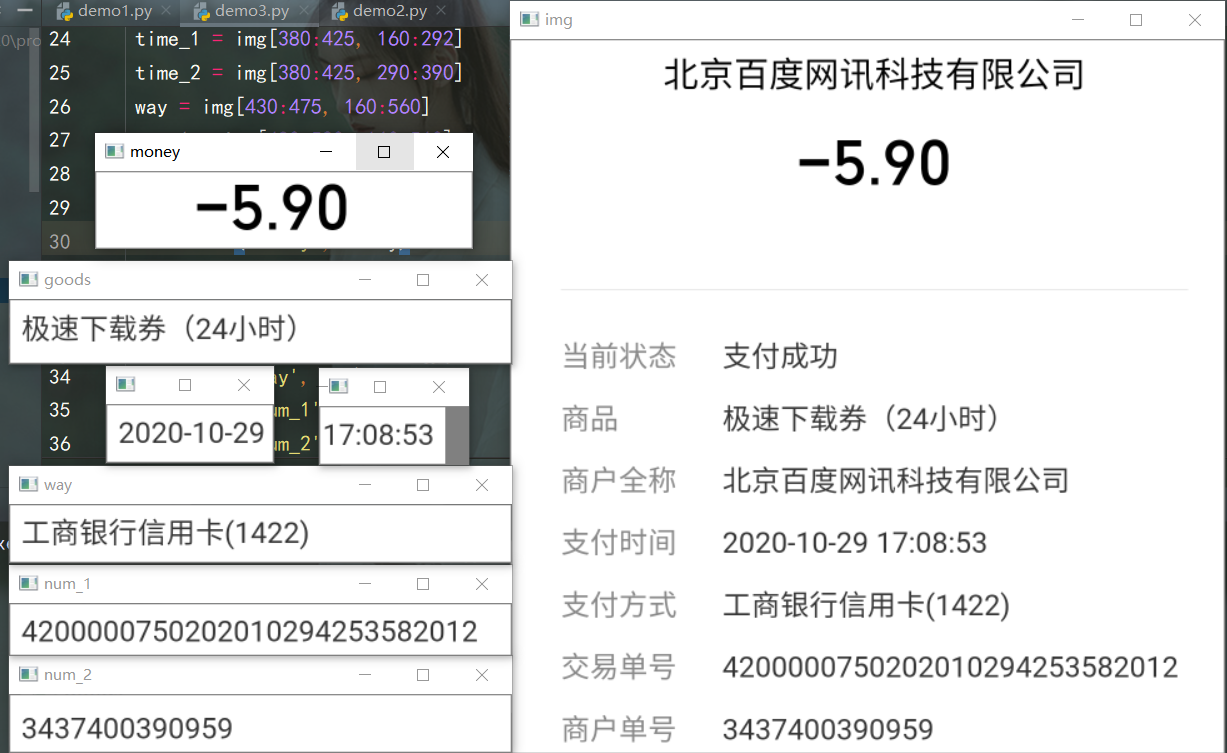
为了增加识别准确率,将账单上要提取的数据区域分割出来,再调用Baidu aip识别。
from pathlib import Path
import cv2 as cv
from aip import AipOcr
from time import sleep
APP_ID = '18690701'
API_KEY = 'QFaTVXvZdPrR05dNlR5I49xA'
SECRET_KEY = '**********************************'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
""" 读取图片 """
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
def identity(num):
result_list = []
for i in range(num):
image = get_file_content('img{}.jpg'.format(i))
""" 调用通用文字识别, 图片参数为本地图片 """
result = client.basicGeneral(image)
print(result)
sleep(2)
# 识别结果
info = ''.join([i['words'] for i in result['words_result']])
result_list.append(info)
print(result_list)
src = cv.imread(r'D:\test\test_img\001.jpg')
src = cv.resize(src, None, fx=0.5, fy=0.5)
# print(src.shape)
img = src[280:850, 10:580] # 截取图片 高 宽
money = img[70:130, 150:450] # 支出 收入金额
goods = img[280:330, 160:560] # 商品
time_1 = img[380:425, 160:292] # 支付时间 年月日
time_2 = img[380:425, 160:390] # 支付时间 完整
way = img[430:475, 160:560] # 支付方式
num_1 = img[480:520, 160:560] # 交易单号
num_2 = img[525:570, 160:560] # 商户单号
img_list = [money, goods, time_1, time_2, way, num_1, num_2]
for index_, item in enumerate(img_list):
cv.imwrite(f'img{index_}.jpg', item)
identity(len(img_list))
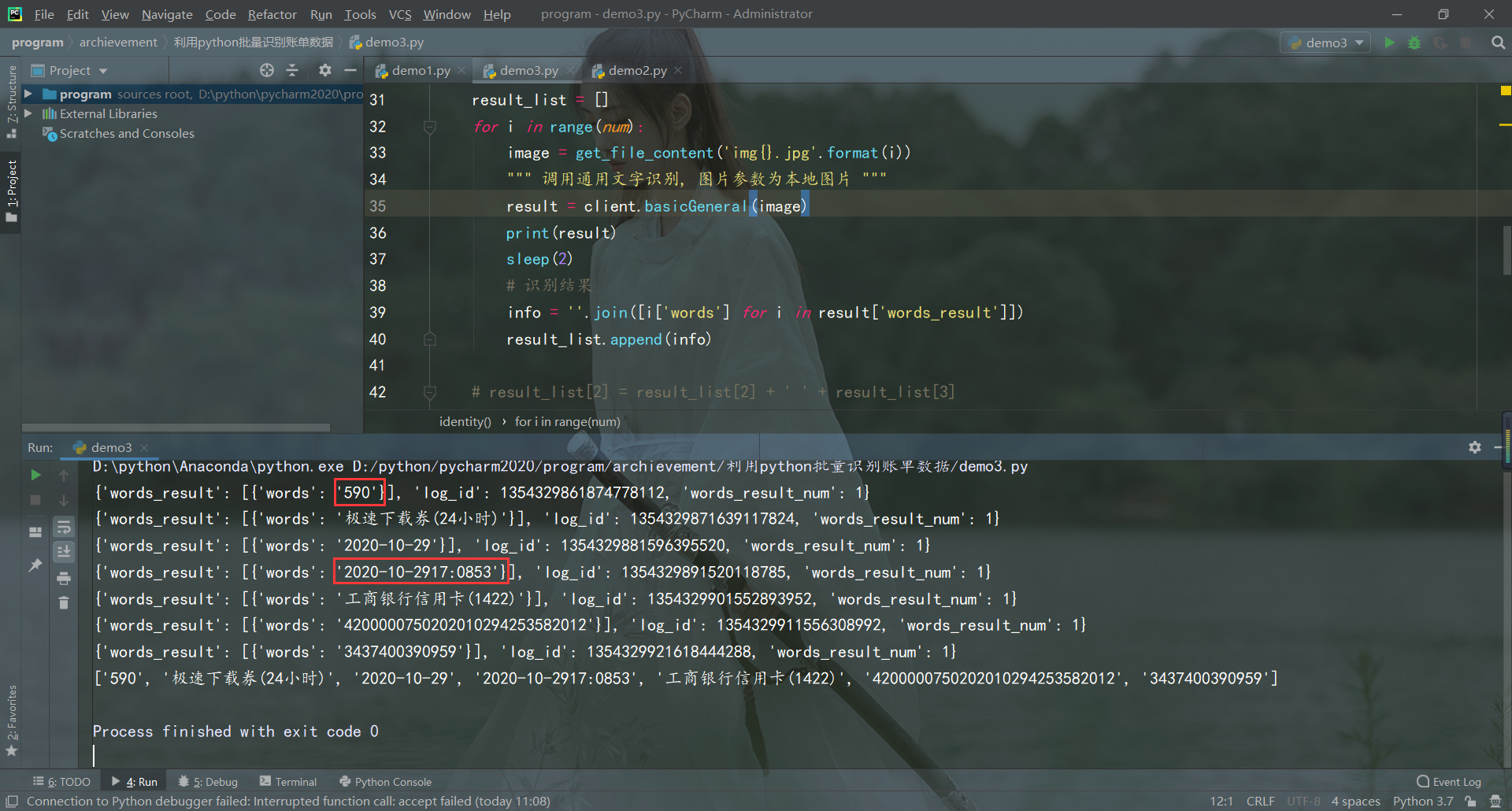
发现调用 client.basicGeneral(image),通用文字识别,-5.90识别成590,而图像里支付时间年月日 时分秒之间间隔小,识别出来都在一起了,需要把支付时间的年月日 时分秒分别分割出来识别,调用 client.basicAccurate(image),通用文字识别(高精度版)。
完整实现如下:
"""
@File :test_01.py
@Author :叶庭云
@CSDN :https://yetingyun.blog.csdn.net/
"""
from aip import AipOcr
from pathlib import Path
import cv2 as cv
from time import sleep
import openpyxl
wb = openpyxl.Workbook()
sheet = wb.active
sheet.append(['消费', '商品', '支付时间', '支付方式', '交易单号', '商品单号'])
# """ 改成你的 百度云服务的 ID AK SK """
APP_ID = '18690701'
API_KEY = 'QFaTVXvZdPrR05dNlR5I49xA'
SECRET_KEY = '*******************************'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
""" 读取图片 """
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
def identity(num):
result_list = []
for i in range(num):
image = get_file_content('img{}.jpg'.format(i))
""" 调用通用文字识别, 图片参数为本地图片 """
result = client.basicAccurate(image)
print(result)
sleep(1)
# 识别结果
info = ''.join([i['words'] for i in result['words_result']])
result_list.append(info)
result_list[2] = result_list[2] + ' ' + result_list[3]
result_list.pop(3)
print(result_list)
sheet.append(result_list)
# 换成你放图片的路径
p = Path(r'D:\test\test_img')
# 得到所有文件夹下 .jpg 图片
file = p.glob('**/*.jpg')
for img_file in file:
img_file = str(img_file)
src = cv.imread(r'{}'.format(img_file))
src = cv.resize(src, None, fx=0.5, fy=0.5)
# print(src.shape)
img = src[280:850, 10:580] # 截取图片 高、宽范围
money = img[70:130, 150:450] # 支出金额
goods = img[280:330, 160:560] # 商品
time_1 = img[380:425, 160:292] # 支付时间 年月日
time_2 = img[380:425, 290:390] # 支付时间 时分秒
way = img[430:475, 160:560] # 支付方式
num_1 = img[480:520, 160:560] # 交易单号
num_2 = img[525:570, 160:560] # 商户单号
img_list = [money, goods, time_1, time_2, way, num_1, num_2]
for index_, item in enumerate(img_list):
cv.imwrite(f'img{index_}.jpg', item)
identity(len(img_list))
# cv.imshow('img', img)
# cv.imshow('goods', time_2)
# cv.waitKey(0)
wb.save(filename='识别账单结果.xlsx')
结果如下:
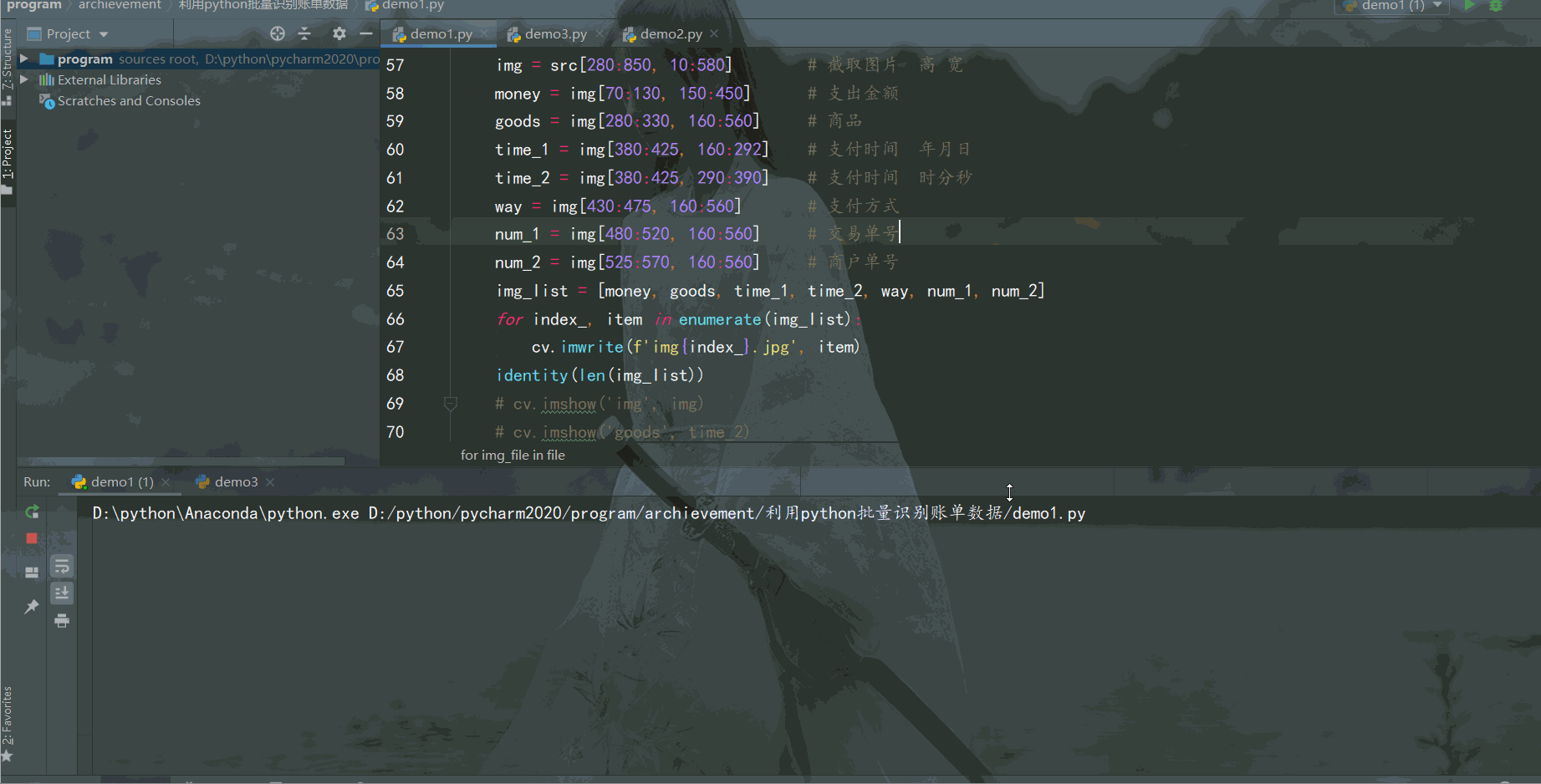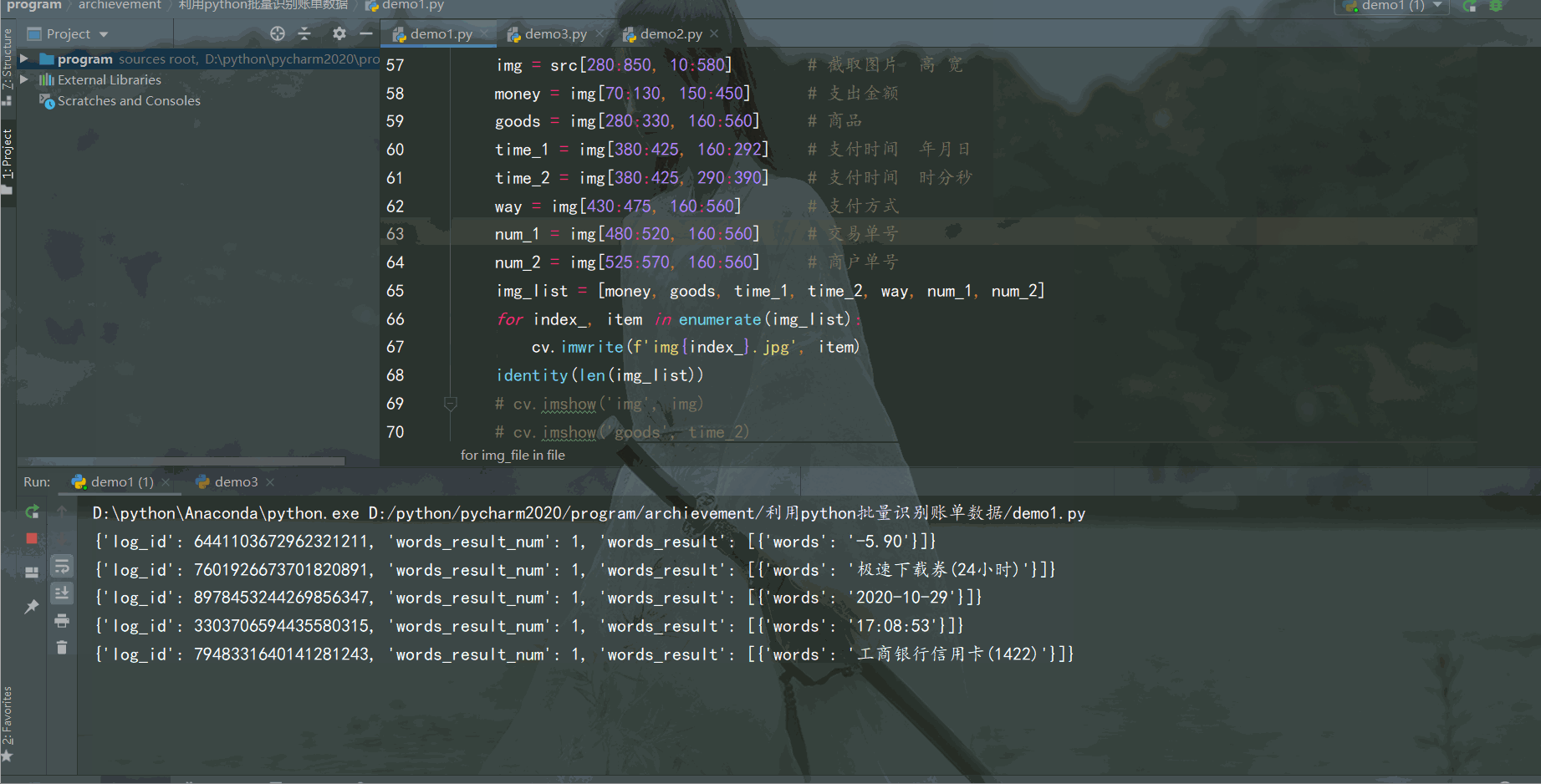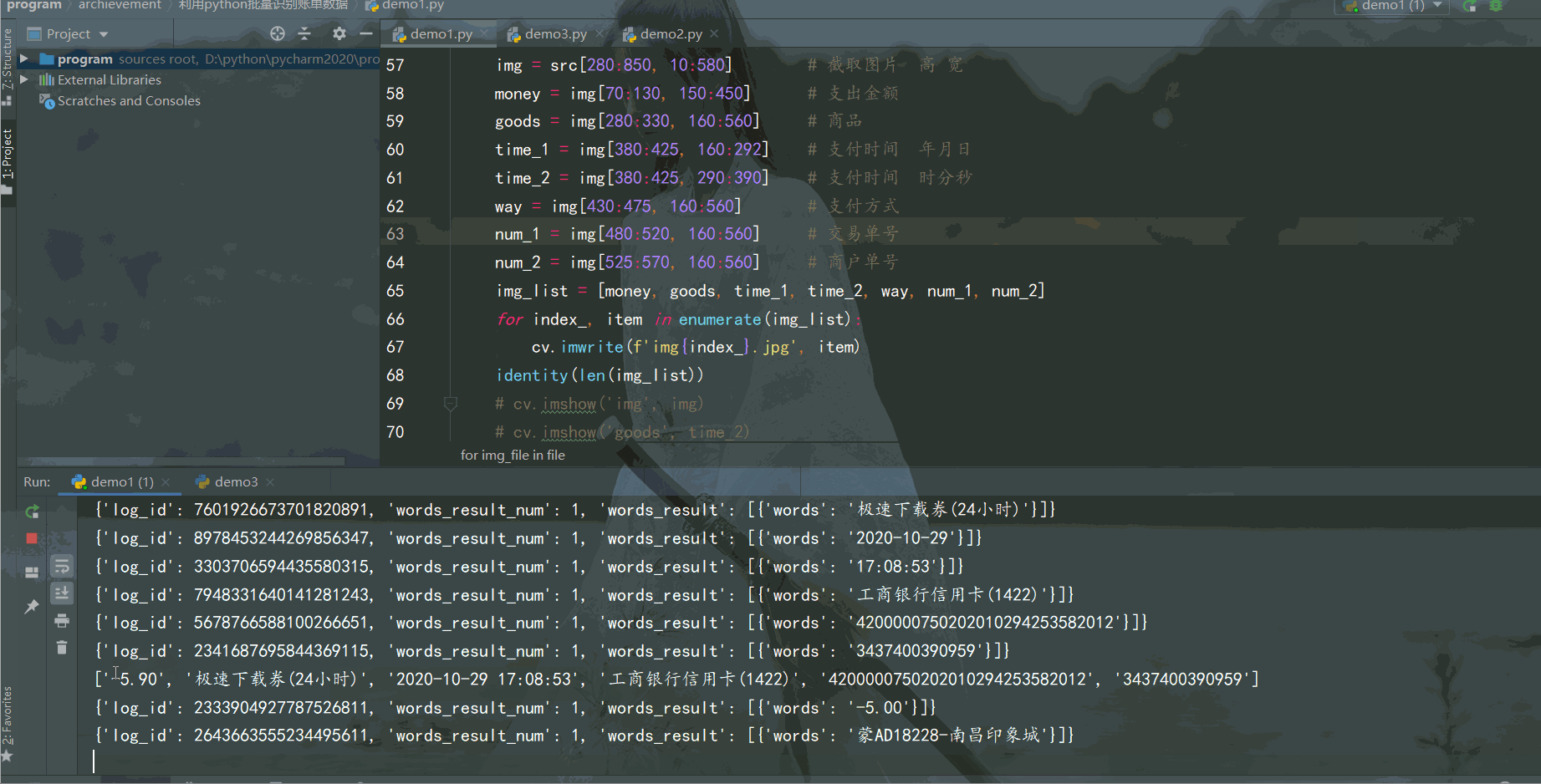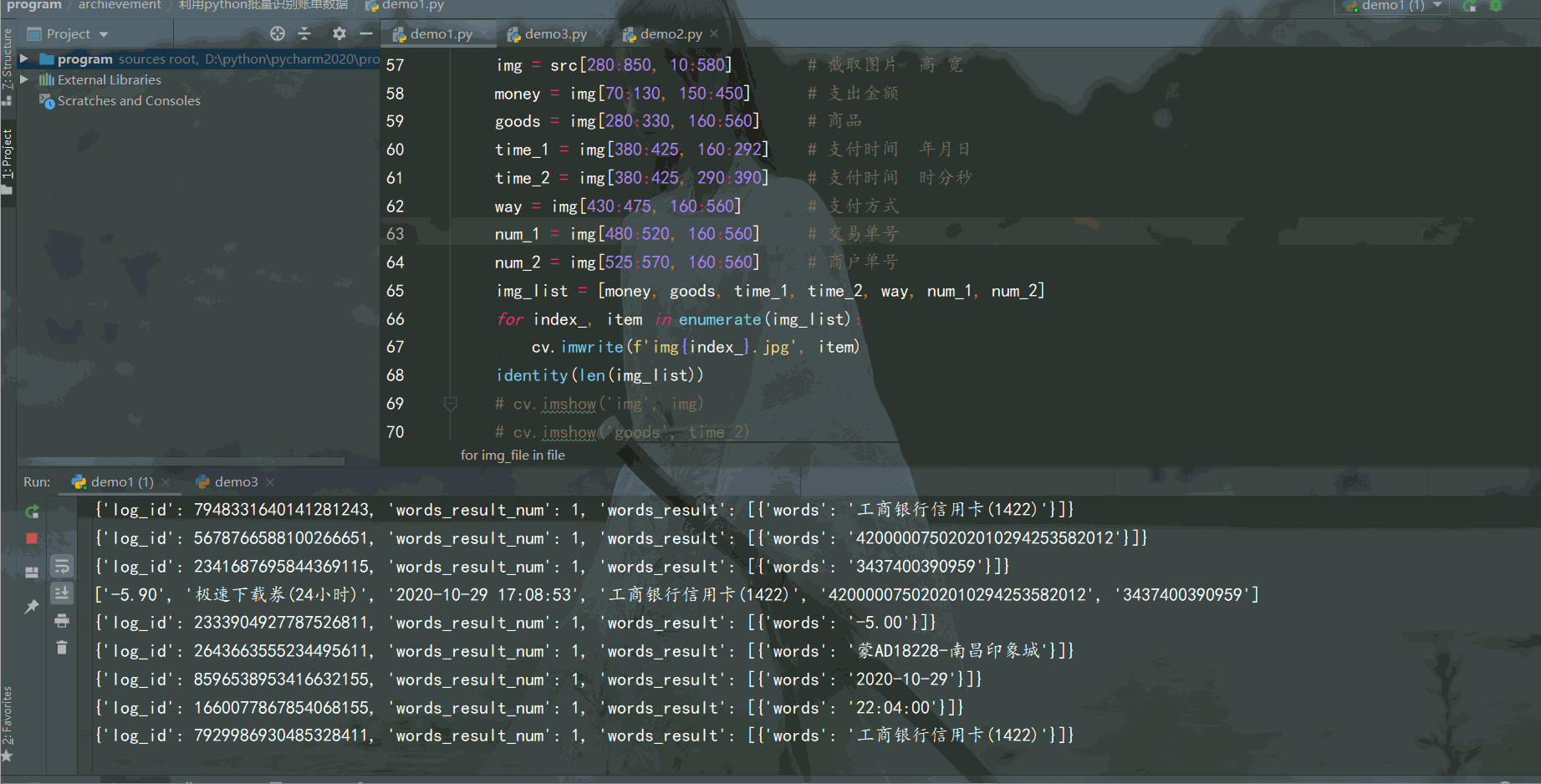

识别结果还不错,成功利用 Python 批量识别电子账单数据,并将数据保存到Excel。
到此这篇关于利用Python批量识别电子账单数据的文章就介绍到这了,更多相关Python识别电子账单内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!