在我们平常使用Python进行数据处理与分析时,在import完一大堆库之后,就是对数据进行预览,查看数据是否出现了缺失值、重复值等异常情况,并进行处理。

本文将结合GUI工具PySimpleGUI,来讲解如何制作一款属于自己的数据预处理小工具,让这个过程也能够自动化!最终效果如下

本文将分为三部分讲解:
- 制作GUI界面
- 数据处理讲解
- 打包与测试
主要涉及将涉及以下模块:
- PySimpleGUI
- pandas
- matplotlib
一、GUI界面制作
思路
老规矩,先讲思路再上代码,首先还是说一下,使用PySimpleGUI还是那四个流程
引入模块==>创建元素并填充layout==> 创建窗体 ==>创建事件循环
从元素看,从图中可以知道我们需要的元素有使用说明这个菜单栏、看上去是凹下去的数据预处理框、框内的3个单选项值、读取文件路径的3个元素(固定文本、输入文本、浏览按钮)、"查看、处理、关闭"三个按钮。
从总体看,整个窗体中我们需要所有的元素呈现正中间的分布状态。其中菜单栏在窗体边缘靠左分布。采用行衔接式的总分布。
从事件上看,我们需要在使用说明菜单中加上使用者需要的注意事项。而文件读取位置我们设置我们常用的2种数据存储格式(“.xlsx”,“.xls”)的Excel格式。
读取后,我们在数据预处理框架选择一种处理。接着,我们可以对每一种错误进行弹出框查看,查看完之后对数据做最终处理。
处理的过程需要将处理好的数据覆盖原来的数据文件。整个过程必须是持续不间断的。这里说个tips:每次数据分析之前最好做一个备份,防止分析过程中失败但是又找不到原来数据文件的尴尬。
代码
看望思路后是不是有种蠢蠢欲动的感觉?!我们来实现一波,先看完整代码,后面详细拆解
import PySimpleGUI as sg
import pandas as pd
import matplotlib
matplotlib.use("TkAgg")
sg.ChangeLookAndFeel('GreenTan')
menu_def = [['&使用说明', ['&注意']]]
layout = [
[sg.Menu(menu_def, tearoff=True)],
[sg.Frame(layout=[
[sg.Radio('重复值处理', "RADIO1",size=(15,1),key="dup"), sg.Radio('缺失值处理', "RADIO1",size=(15,1),key="mis"), sg.Radio('异常值处理', "RADIO1",default=True,key="war")]], title='数据预处理',title_color='green',title_location='n',relief=sg.RELIEF_SUNKEN, tooltip='选择其中一种处理方式' )],
[sg.Text('文件位置', size=(8, 1), auto_size_text=False, justification='right'),
sg.InputText(enable_events=True,key="lujing"), sg.Button('浏览',key = 'getf')],
[sg.Button('查看',key = 'look'),sg.Submit('处理',key = 'handle'), sg.Cancel('关闭')]]
window = sg.Window('特征工程', layout, default_element_size=(40, 1), grab_anywhere=False)
while True:
event, values = window.read()
if event == 'getf':
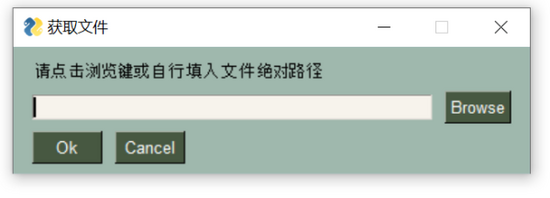
text = sg.popup_get_file('请点击浏览键或自行填入文件绝对路径',title = '获取件',file_types = (("Excel Files", "*.xlsx"),("Excel Files", "*.xls"),))
sg.popup('提示', '是否确认选择文件---', text)
window['lujing'].update(text)
if event == "look":
'''
用户点击查看按钮促发的事件
'''
if event == "handle":
'''
用户点击处理按钮促发的事件
'''
if event == "Cancel" or event == sg.WIN_CLOSED:
break
if event == "注意":
'''
注意事项编写
'''
代码解释
其实有了思路后,你就会发现似乎一切都变得简单了。接下来讲解相关参数的作用。
首先是matplotlib.use("TkAgg"):使用matplotlib模块并且调用这个函数的目的是在我们进行查看异常值处理(箱型图展示)所用到,是改变图像显示的方式:TkAgg(一个交互式后台)。
所谓交互式后台就是你可以对图像进行任意操作,区域放大缩小、值查看等功能。
之所以调用这个函数首先是因为我们使用的是GUI是要有那种交互的感觉的,其次是如果数据量较大时,箱型图会很小,这样子可以利于查看。
其次sg.ChangeLookAndFeel('GreenTan'):改变窗体颜色。
那么menu_def就是菜单栏,使用【“”,【“”】】这种格式来定义主菜单栏和子菜单栏。tearoff这个函数是加一条可爱的虚线间隔每个字段。
sg.Frame():这个和sg.columns()元素的用法是一样的,主要是用来多个子元素的,我们这里设置了relief参数来让整个框架在观感上显得凹形。tooltip参数是你鼠标移动框架的位置出现的小提示框。
title_location参数的用法非常有趣,是标题字符串的位置设置,有(n,s,e,w,se等),你很快会发现这个位置和其他元素布局位置设置不一样,他是以地理位置坐标做子参数的。
sg.Radio:单选选项框,要将所有的单选选项框的子参数group_id都设成一样的,这样你才能三个选项中选一个,这里我们以"RADIO1"为group_id。
sg.Button():整个GUI中我们使用了4个按钮,其中有一个专有的按钮Cancel。
sg.popup():比较初级的弹出框,显示提示类的关键信息所用到。
sg.popup_get_file():这是一个高级的弹出框元素,是从带有文本输入字段和浏览按钮的弹出窗口,以便用户选择文件。效果如下
二、数据预处理
GUI部分搞定后,接着我们讲解数据处理部分,主要是针对重复值、缺失值和异常值。
数据准备
我们这里用到的是2020年10月28日A股的行情。数据部分展示:
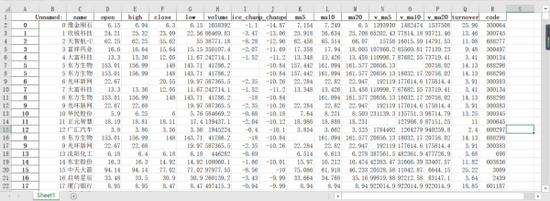
我们可以看到这里面有重复的行、有缺失值的地方。
重复值处理
对于二维列表DataFrame来讲使用Pandas模块是最方便最象征办公简洁化的模块
import pandas as pd
df = df.read_excel('文件绝对路径')
imfor = df[df.duplicated()]
imfor = str(imfor)
首先调用Pandas模块并读取文件路径,这里我们采取绝对路径而不采取相对路径的原因是我们之后打包的GUI是不依靠文件的靠Python自带的环境,所以相对路径读取是无法识别的。
df[df.duplicated()]这个Pandas内的函数是以二维列表形式来打印重复值对应的行。这里把df变量变为str字符串形式是因为我们在后来GUI中使用弹出窗口的元素时要以字符串形式加载。
最终处理重复值的方法如下:
df = df.drop_duplicates(inplace = True)
代码只有一行,却能做到将整个数据表中的重复值都删除,说明Pandas函数的强大。
至于为什么用inplace = True,是因为删除函数不并不能改变原表格结构,所以需要将新表覆盖原来的表格。
缺失值处理
先看代码,其实在之前有关缺失值处理我在一年前就写过相关文章点击查看
import pandas as pd
df = df.read_excel('文件绝对路径')
#df.isnull()
imfor1 = df.isnull().sum()
#df.isnull().any()
imfor1 = str(imfor1)
对于有缺失值的的数据表来说,df.isnull()或者df.isna()来查看空值。这个函数的作用时判断是否为空值,若是为空值则赋予True,否则赋予False。
这里我们使用df.isnull().sum()来统计每一列字段的缺失值数量。如果数据量大的话,还可以使用df.isnull().any()来查看只有缺失值的行。
解决方法,处理缺失值的方法有很多种,取均值、取中位数、删除、取下方的值等。我们这里用取上方值的方法来填补。
df = df.fillna(method='pad')
异常值处理
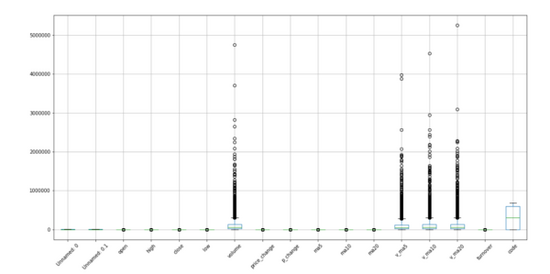
所谓异常值,就是在一个数字字段里出现一个或多个不合群得数字。举个例子,在一列都为个位数得数字列中出现了一个百位数的数字,这个百位数就是异常值。
用Python检测异常值有两种:箱线图图观察和标准差观察。这里我们选则箱体图观察。
箱线图是用于显示所选数据分散情况的统计图,通过设定标准,将大于或小于箱体图上下线的数值表示为异常点。
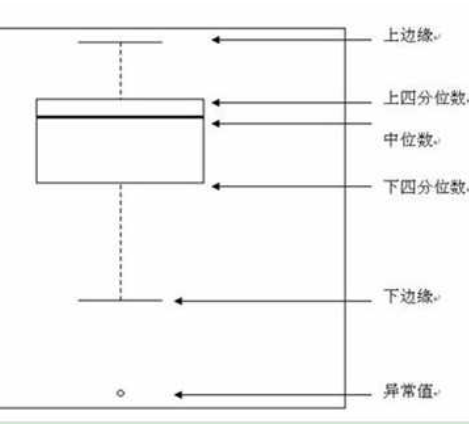
如图,下四分分位数指的是样本中有百分之25的数据小于这个数,记为。上四分分位数指的是样本中有百分之25大于这个数,记为。上四分位数和下四分位数的差值的1.5倍加上上四分位数就是上边缘,反之为下边缘。
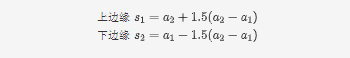
import pandas as pd df.boxplot()
打包与效果展示
在写完全部代码之后,我们可以使用pyinstaller进行打包。
假定你的程序命名为yuchuli.py,在cmd窗口输入即可完成打包。
pyinstaller -F yuchuli.py
打包后,exe在Python文件所在文件夹的dist文件夹中。我们启动来看下效果
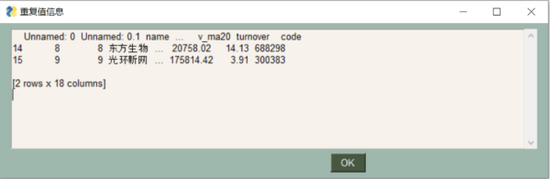
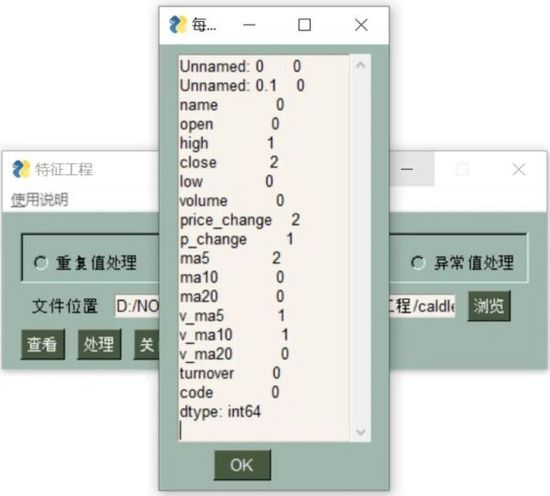
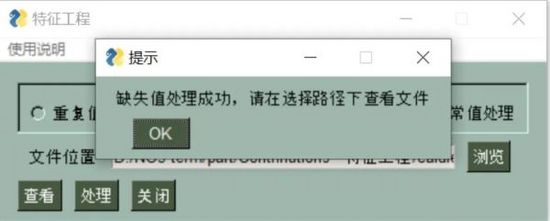
可以看到,我们需要的数据预处理的三个功能:重复值、缺失值、异常值都能按照指定方式进行处理!
当然你可以在本文提供的方法上,自己进行修改,来定制一款属于你自己平时习惯的数据预处理小软件!
到此这篇关于使用Python制作一个数据预处理小工具(多种操作一键完成)的文章就介绍到这了,更多相关Python数据预处理小工具内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!