在使用交叉熵损失函数的时候,target的形状应该是和label的形状一致或者是只有batchsize这一个维度的。
如果target是这样的【batchszie,1】就会出现上述的错误。
改一下试试,用squeeze()函数降低纬度,
如果不知道squeeze怎么用的,
可以参考这篇文章。pytorch下的unsqueeze和squeeze用法
这只是一种可能的原因。
补充:pytorch使用中遇到的问题
1. load模型参数文件时,提示torch.cuda.is_available() is False。
按照pytorch官方网页又安装了一次pytorch,而不是直接使用清华源,执行pip install torch,暂时不知道为什么。
2. 使用CrossEntropyLoss时,要求第一个参数为网络输出值,FloatTensor类型,第二个参数为目标值,LongTensor类型。否则
需要在数据读取的迭代其中把target的类型转换为int64位的:target = target.astype(np.int64),这样,输出的target类型为torch.cuda.LongTensor。(或者在使用前使用Tensor.type(torch.LongTensor)进行转换)。
3.
RuntimeError: multi-target not supported at /pytorch/torch/lib/THCUNN/generic/ClassNLLCriterion.cu loss += F.cross_entropy( scores, captions )
出错原因:
scores, captions的维度与F.cross_entropy()函数要求的维度不匹配,
例如出错的维度为scores=[batch, vocab_size], captions=[batch, 1]
解决:
loss += F.cross_entropy( scores, captions.squeeze() )
注,这个scores必须是N*C维,C指类别数。
4. pytorch训练过程中使用大量的CPU资源
当我使用pycharm运行 (https://github.com/Joyce94/cnn-text-classification-pytorch ) pytorch程序的时候,在Linux服务器上会开启多个进程,占用服务器的大量的CPU,在windows10上运行此程序的时候,本机的CPU和内存会被吃光,是因为在train.py中有大量的数据训练处理,会开启多个进程,占用大量的CPU和进程。
本机window10
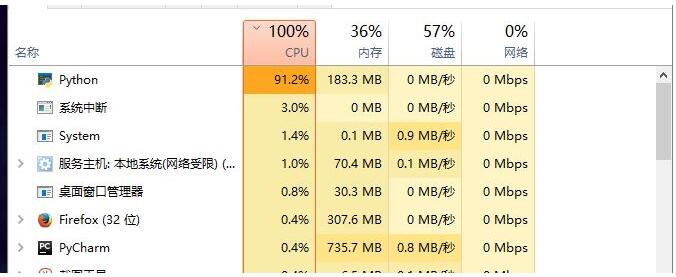
linux服务器开启了多个进程
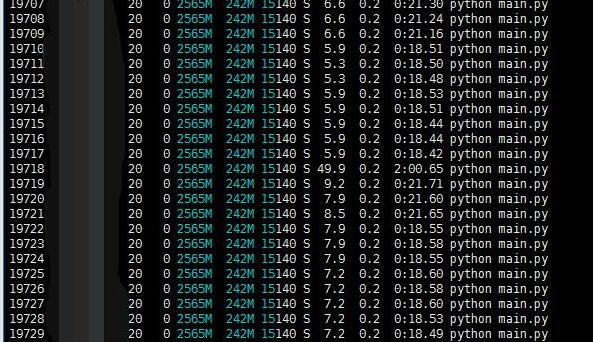
Linux服务器占用大量CPU

在pytorch中提供了(http://pytorch.org/docs/master/multiprocessing.html)muliprocessing多进程管理,其中有Pool进程池、Process()等对进程进行管理,可能是我使用的方式不对,反正是没有什么效果。
然而最简单的也是最好的解决办法 :
torch.set_num_threads(int thread) ,可以很好的解决windows问题,参考(http://pytorch.org/docs/master/torch.html#parallelism) 然而,在linux服务器上还是有一些问题的,export OMP_NUM_THREADS = 1 可以解决Linux问题。
经验证:export OMP_NUM_THREADS=1确实在pycaffe/pytorch中可以有效降低CPU使用率且提高程序运行速度,考虑可能是程序并不需要这么大的计算量,但是开了很多线程并行进行相同的计算,最后还需要同步结果,浪费了大量的计算量。
5. 在pytorch框架下编译模块的时候遇到 in <module>
raise ImportError("torch.utils.ffi is deprecated. Please use cpp extensions instead.")
ImportError: torch.utils.ffi is deprecated. Please use cpp extensions instead.
解决:pytorch版本与其他库的版本不匹配。我当时装的是1.0.0,降低版本到0.4.0后问题解决。
6.pytorch设置GPU,os.environ['CUDA_VISIBLE_DEVICES']='X'要放在主程序的最前端,否则设置GPU可能无效。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持易盾网络。如有错误或未考虑完全的地方,望不吝赐教。