变量的缓存机制
变量的缓存机制(以下内容仅对python3.6.x版本负责)
机制
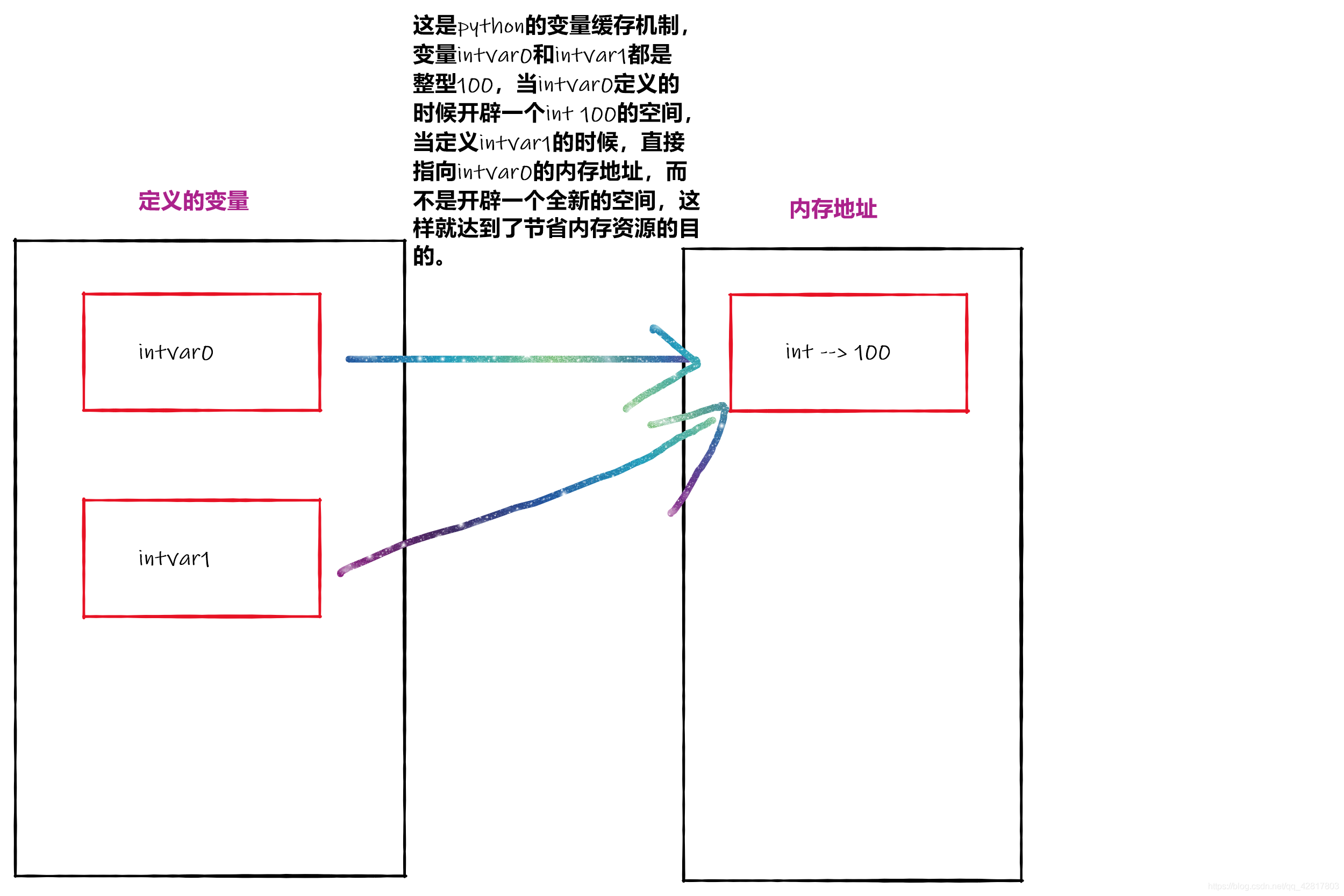
只要有两个值相同,就只开辟一个空间
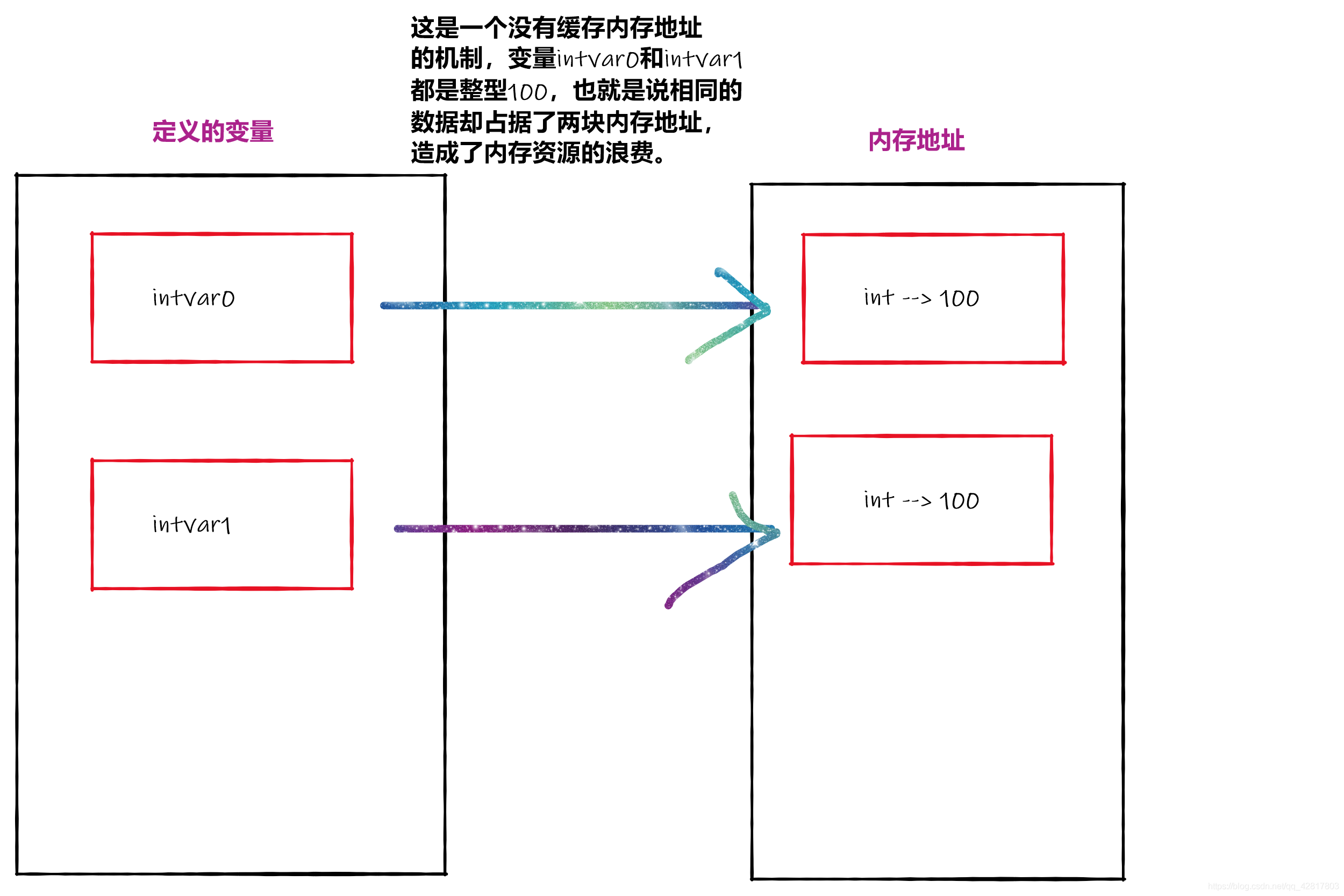
为什么要有这样的机制
在计算机的硬件当中,内存是最重要的配置之一,直接关系到程序的运行速度和流畅度。在过去计算机内存资源昂贵而小的年代中,程序的内存管理成为编程中的重要技术之一。python没有C/C++中的指针那样的定义可以编程者自主的控制内存的分配,而是有一套自动的内存地址分配和缓存机制。在这个机制当中,可以把一些相同值的变量在内存中指向同一块区域,而不再重新开辟一个空间,这样就达到了节省内存的目的。
python中使用id()函数查看数据的内存地址
number部分
整型
对于整型而言,-5~~正无穷的范围内的相同值的id地址一致
# 在后续的版本中所有的数的id地址都一致 # 相同 print(id(9999999), id(9999999)) print(id(100), id(100)) print(id(-5), id(-5)) # 不同 print(id(-6), id(-6))
浮点型
对于浮点型而言,非负数范围内的相同值id一致
# 相同 print(id(9999999.0), id(9999999.0)) print(id(100.0), id(100.0)) # 不同 print(id(-5.0), id(-5.0)) print(id(-6.0), id(-6.0))
布尔值
对于布尔值而言,值相同测情况下,id一致
# 相同 print(id(True), id(True)) print(id(False), id(False))
复数
复数在(实数+虚数)这样的结构当中永不相同,只有单个虚数相同才会一致
# 相同 print(id(1j), id(1j)) print(id(0j), id(0j)) # 不同 print(id(1234j), id(3456j)) print(id(1+1j), id(1+1j)) print(id(2+0j), id(2+0j))
容器部分
字符串
字符串在相同的情况下,地址相同
# 相同
print(id('hello '), id("hello "))
# 不同
print(id('msr'), id('wxd'))
字符串配合使*号使用有特殊的情况:
乘数为1:只要数据相同,地址就是相同的
# 等于1,和正常的情况下是一样的,只要值相同地址就是一样的 a = 'hello ' * 1 b = 'hello ' * 1 print(a is b) a = '祖国' * 1 b = '祖国' * 1 print(a is b)
乘数大于1:只有仅包含数字、字母、下划线时地址是相同的,而且字符串的长度不能大于20
# 纯数字字母下划线,且长度不大于20 a = '_70th' * 3 b = '_70th' * 3 c = '_70th_70th_70th' print(a, id(a), len(a)) print(b, id(b), len(b)) print(c, id(c), len(c)) print(a is b is c) ''' 结果: _70th_70th_70th 1734096389168 15 _70th_70th_70th 1734096389168 15 _70th_70th_70th 1734096389168 15 True '''
# 纯数字字母下划线,长度大于20 a = 'motherland_70th' * 3 b = 'motherland_70th' * 3 c = 'motherland_70thmotherland_70thmotherland_70th' print(a, id(a), len(a)) print(b, id(b), len(b)) print(c, id(c), len(c)) print(a is b is c) ''' 结果: motherland_70thmotherland_70thmotherland_70th 2281801354864 45 motherland_70thmotherland_70thmotherland_70th 2281801354960 45 motherland_70thmotherland_70thmotherland_70th 2281801354768 45 False '''
# 有其它字符,且长度不大于20 a = '你好' * 3 b = '你好' * 3 c = '你好你好你好' print(a, id(a), len(a)) print(b, id(b), len(b)) print(c, id(c), len(c)) print(a is b is c) ''' 结果: 你好你好你好 3115902573360 6 你好你好你好 3115902573448 6 你好你好你好 3115900671904 6 False '''
字符串指定驻留
使用sys模块中的intern函数,让变量指向同一个地址,只要字符串的值是相同的,无论字符的类型、长度、变量的数量,都指向同一个内存地址。
语法:intern(string)
from sys import intern
a = intern('祖国70华诞: my 70th birthday of the motherland' * 1000)
b = intern('祖国70华诞: my 70th birthday of the motherland' * 1000)
c = intern('祖国70华诞: my 70th birthday of the motherland' * 1000)
d = intern('祖国70华诞: my 70th birthday of the motherland' * 1000)
e = intern('祖国70华诞: my 70th birthday of the motherland' * 1000)
print(a is b is c is d is e)
元组
元组只有为空的情况下,地址相同
# 相同 print(id(()), id(tuple())) # 不同 print(id((1, 2)), id((1, 2)))
列表、集合、字典
任何情况下,地址都不会相同
# 列表、非空元组、集合、字典 无论在声明情况下,id表示都不会相同
# 不同
print(id([]), id([]))
print(id(set()), id(set()))
print(id({}), id({}))
总结
# -->Number 部分 1.对于整型而言,-5~正无穷范围内的相同值 id一致 2.对于浮点数而言,非负数范围内的相同值 id一致 3.布尔值而言,值相同情况下,id一致 4.复数在 实数+虚数 这样的结构中永不相同(只有虚数的情况例外,只有虚数的虚数相同才会id一致) # -->容器类型部分 5.字符串 和 空元组 相同的情况下,地址相同 6.列表,元组,字典,集合无论什么情况 id标识都不同 [空元组例外]
小数据池
以下内容仅对python3.6.8负责
数据在同一个文件(模块)当中,变量存储的的缓存机制就是上述的那样。
但是如果是在不同文件(模块)当中的数据,部分数据就会驻留在小数据池当中。
什么是小数据池
不同的python文件(模块)中的相同数据的本应该是不在同一个内存地址当中的, 而是应该全新的开辟一个新空间,但是这样就造成了内存的空间压力,所以python定义了小数据池的概念,默认允许小部分数据即使在不同的文件当中,只要数据相同就可以使用同一个内存空间,节省内存。
小数据池支持什么类型
小数据池只针对:int、bool、None关键字 ,这些数据类型有效。
int
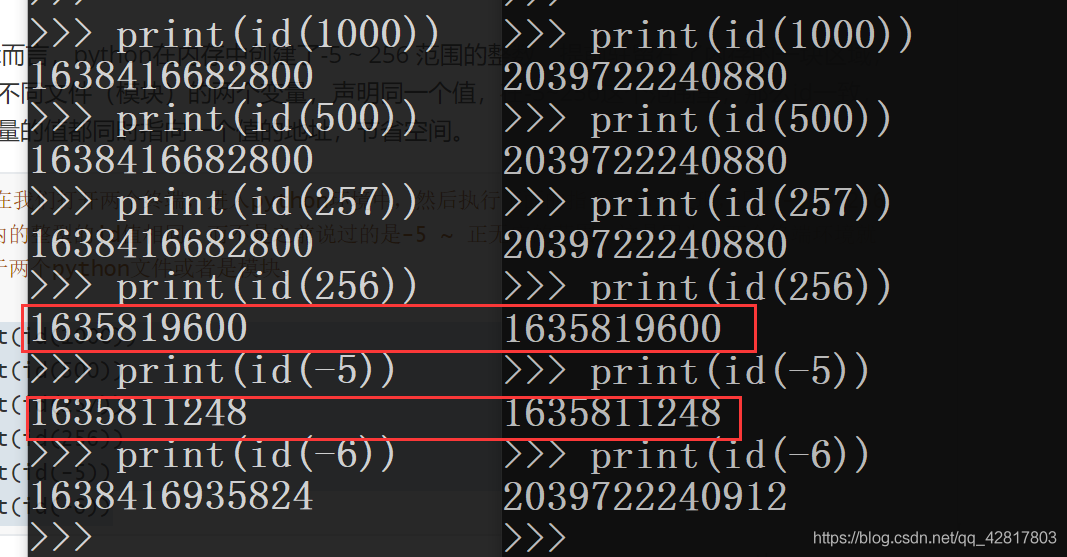
对于int而言,python在内存中创建了-5 ~ 256 范围的整数,提前驻留在了内存的一块区域,如果是不同文件(模块)的两个变量,声明同一个值,在-5~256这个范围里,那么id一致,两个变量的值都同时指向一个值的地址,节省空间。
# 现在我们打开两个终端,进入python环境中,然后执行下面的指令,你会发现,只有-5 ~ 256范围内的整型的id值相同,而不是之前说过的是-5 ~ 正无穷的范围,这是因为,两个终端环境就相当于两个python文件或者是模块。 print(id(1000)) print(id(500)) print(id(257)) print(id(256)) print(id(-5)) print(id(-6))
其它
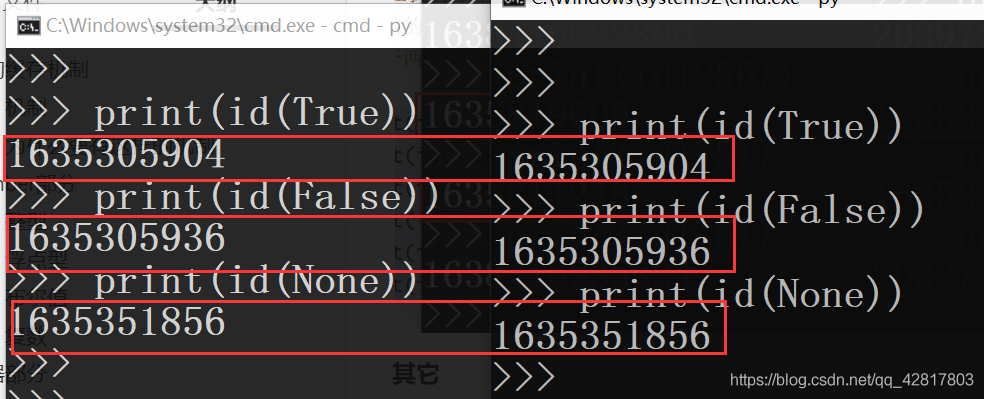
布尔、None这些类型都是有效的
# 开启两个终端测试吧 print(id(True)) print(id(False)) print(id(None))
到此这篇关于python的变量缓存机制的文章就介绍到这了,更多相关python的变量缓存机制内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!