之前有群友反应同事给了他一个几百MB的sql脚本,导入数据库再从数据库读取数据有点慢,想了解下有没有可以直接读取sql脚本到pandas的方法。
解析sql脚本文本文件替换成csv格式并加载
我考虑了一下sql脚本也就只是一个文本文件而已,而且只有几百MB,现代的机器足以把它一次性全部加载到内存中,使用python来处理也不会太慢。
我简单研究了一下sql脚本的导出格式,并根据格式写出了以下sql脚本的读取方法。
注意:该读取方法只针对SQLyog导出的mysql脚本测试,其他数据库可能代码需要根据实际情况微调。
读取方法:
from io import StringIO
import pandas as pd
import re
def read_sql_script_all(sql_file_path, quotechar="'") -> (str, dict):
insert_check = re.compile(r"insert +into +`?(\w+?)`?\(", re.I | re.A)
with open(sql_file_path, encoding="utf-8") as f:
sql_txt = f.read()
end_pos = -1
df_dict = {}
while True:
match_obj = insert_check.search(sql_txt, end_pos+1)
if not match_obj:
break
table_name = match_obj.group(1)
start_pos = match_obj.span()[1]+1
end_pos = sql_txt.find(";", start_pos)
tmp = re.sub(r"\)( values |,)\(", "\n", sql_txt[start_pos:end_pos])
tmp = re.sub(r"[`()]", "", tmp)
df = pd.read_csv(StringIO(tmp), quotechar=quotechar)
dfs = df_dict.setdefault(table_name, [])
dfs.append(df)
for table_name, dfs in df_dict.items():
df_dict[table_name] = pd.concat(dfs)
return df_dict
参数:
- sql_file_path:sql脚本的位置
- quotechar:脚本中字符串是单引号还是双引号,默认使用单引号解析
返回:
一个字典,键是表名,值是该表对应的数据所组成的datafream对象
下面我测试读取下面这个sql脚本:
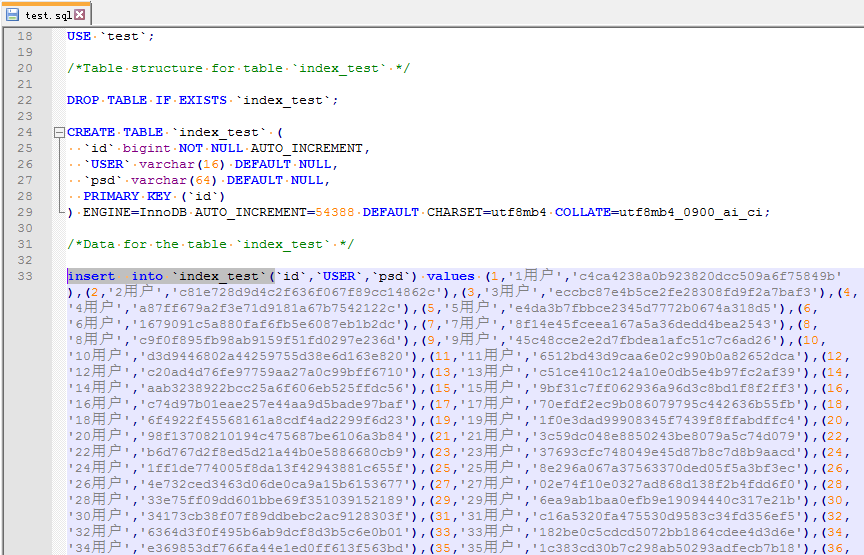
其中的表名是index_test:
df_dict = read_sql_script_all("D:/tmp/test.sql")
df = df_dict['index_test']
df.head(10)
结果:
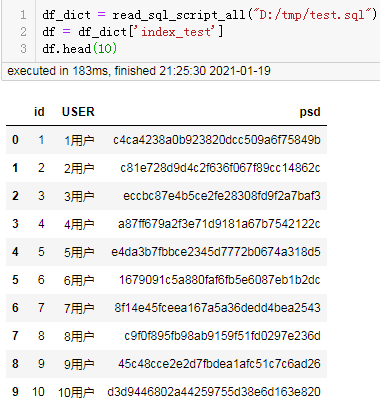
可以看到能顺利的直接从sql脚本中读取数据生成datafream。
当然上面写的方法是一次性读取整个sql脚本的所有表,结果为一个字典(键为表名,值为datafream)。但大部分时候我们只需要读取sql脚本的某一张表,我们可以改造一下上面的方法:
def read_sql_script_by_tablename(sql_file_path, table_name, quotechar="'") -> (str, dict):
insert_check = re.compile(r"insert +into +`?(\w+?)`?\(", re.I | re.A)
with open(sql_file_path, encoding="utf-8") as f:
sql_txt = f.read()
end_pos = -1
dfs = []
while True:
match_obj = insert_check.search(sql_txt, end_pos+1)
if not match_obj:
break
start_pos = match_obj.span()[1]+1
end_pos = sql_txt.find(";", start_pos)
if table_name != match_obj.group(1):
continue
tmp = re.sub(r"\)( values |,)\(", "\n", sql_txt[start_pos:end_pos])
tmp = re.sub(r"[`()]", "", tmp)
df = pd.read_csv(StringIO(tmp), quotechar=quotechar)
dfs.append(df)
return pd.concat(dfs)
参数:
- sql_file_path:sql脚本的位置
- table_name:被读取的表名
- quotechar:脚本中字符串是单引号还是双引号,默认使用单引号解析
返回:
该表所对应的datafream对象
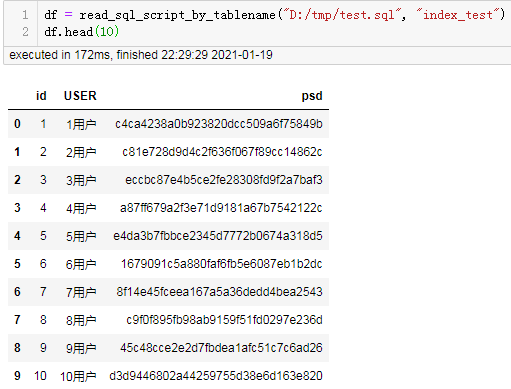
读取代码:
df = read_sql_script_by_tablename("D:/tmp/test.sql", "index_test")
df.head()
结果:
将sql脚本转换为sqlite格式并通过本地sql连接读取
在写完上面的方法后,我又想到另一种解决思路,就是将sql脚本转换成sqlite语法的sql语句,然后直接加载。各种类型的数据库的sql语句变化较大,下面的方法仅针对SQLyog导出的mysql脚本测试通过,如果是其他的数据库,可能下面的方法仍然需要微调。最好是先自行将sql脚本转换为sqlite语法的sql语句后,再使用我写的方法加载。
加载sql脚本的方法:
from sqlalchemy import create_engine
import pandas as pd
import re
def load_sql2sqlite_conn(sqltxt_path):
create_rule = re.compile("create +table [^;]+;", re.I)
insert_rule = re.compile("insert +into [^;]+;", re.I)
with open(sqltxt_path, encoding="utf-8") as f:
sqltxt = f.read()
engine = create_engine('sqlite:///:memory:')
pos = -1
while True:
match_obj = create_rule.search(sqltxt, pos+1)
if match_obj:
pos = match_obj.span()[1]
sql = match_obj.group(0).replace("AUTO_INCREMENT", "")
sql = re.sub("\).+;", ");", sql)
engine.execute(sql)
match_obj = insert_rule.search(sqltxt, pos+1)
if match_obj:
pos = match_obj.span()[1]
sql = match_obj.group(0)
engine.execute(sql)
else:
break
tablenames = [t[0] for t in engine.execute(
"SELECT tbl_name FROM sqlite_master WHERE type='table';").fetchall()]
return tablenames, engine.connect()
参数:
sql_file_path:sql脚本的位置
返回:
两个元素的元组,第一个元素是表名列表,第二个元素是sqlite内存虚拟连接
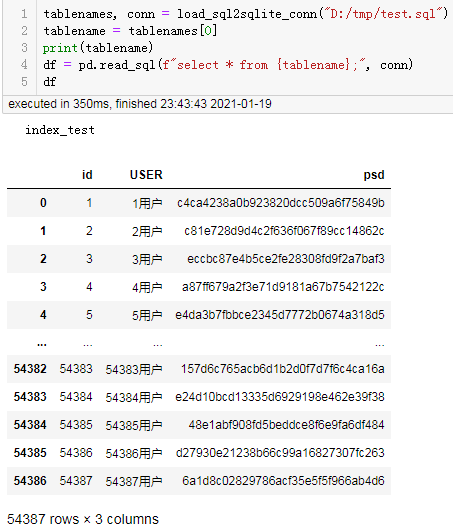
测试读取:
tablenames, conn = load_sql2sqlite_conn("D:/tmp/test.sql")
tablename = tablenames[0]
print(tablename)
df = pd.read_sql(f"select * from {tablename};", conn)
df
结果:
到此这篇关于Pandas直接读取sql脚本的文章就介绍到这了,更多相关Pandas读取sql脚本内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!