人脸识别技术已经相当成熟,面对满大街的人脸识别应用,像单位门禁、刷脸打卡、App解锁、刷脸支付、口罩检测........
作为一个图像处理的爱好者,怎能放过人脸识别这一环呢!调研开搞,发现了超实用的Facecognition!现在和大家分享下~~
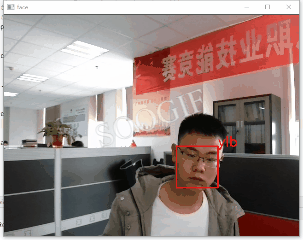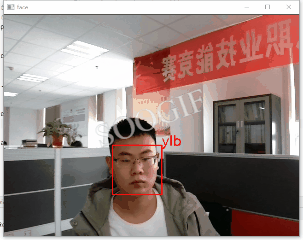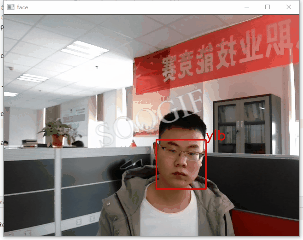
Facecognition人脸识别原理大体可分为:
1、通过hog算子定位人脸,也可以用cnn模型,但本文没试过;
2、Dlib有专门的函数和模型,实现人脸68个特征点的定位。通过图像的几何变换(仿射、旋转、缩放),使各个特征点对齐(将眼睛、嘴等部位移到相同位置);
3、训练一个神经网络,将输入的脸部图像生成为128维的预测值。训练的大致过程为:将同一人的两张不同照片和另一人的照片一起喂入神经网络,不断迭代训练,使同一人的两张照片编码后的预测值接近,不同人的照片预测值拉远;
4、将陌生人脸预测为128维的向量,与人脸库中的数据进行比对,找出阈值范围内欧氏距离最小的人脸,完成识别。
1 开发环境
PyCharm: PyCharm Community Edition 2020.3.2 x64
Python:Python 3.8.7
Opencv:opencv-python 4.5.1.48
Facecognition:1.3.0
Dlb:dlb 0.5.0
2 环境搭建
本文不做PyCharm和Python安装,这个自己搞不定,就别玩了~
pip install opencv-python pip install face-recognition pip install face-recognition-models pip install dlb
3 打造自己的人脸库
通过opencv、facecogniton定位人脸并保存人脸头像,生成人脸数据集,代码如下:
import face_recognition
import cv2
import os
def builddataset():
Video_face = cv2.VideoCapture(0)
num=0
while True:
flag, frame = Video_face.read();
if flag:
cv2.imshow('frame', frame)
cv2.waitKey(2)
else:
break
face_locations = face_recognition.face_locations(frame)
if face_locations:
x_face = frame[face_locations[0][0]-50:face_locations[0][2]+50, face_locations[0][3]-50:face_locations[0][1]+50];
#x_face = cv2.resize(x_face, dsize=(200, 200));
bo_photo = cv2.imwrite("%s\%d.jpg" % ("traindataset/ylb", num), x_face);
print("保存成功:%d" % num)
num=num+1
else:
print("****未检查到头像****")
Video_face.release()
if __name__ == '__main__':
builddataset();
pass
4、模型训练与保存
通过数据集进行训练,得到人脸识别码,以numpy数据形式保存(人脸识别码)模型
def __init__(self, trainpath,labelname,modelpath, predictpath):
self.trainpath = trainpath
self.labelname = labelname
self.modelpath = modelpath
self.predictpath = predictpath
# no doc
def train(self, trainpath, modelpath):
encodings = []
dirs = os.listdir(trainpath)
for k,dir in enumerate(dirs):
filelist = os.listdir(trainpath+'/'+dir)
for i in range(0, len(filelist)):
imgname = trainpath + '/'+dir+'/%d.jpg' % (i)
picture_of_me = face_recognition.load_image_file(imgname)
face_locations = face_recognition.face_locations(picture_of_me)
if face_locations:
print(face_locations)
my_face_encoding = face_recognition.face_encodings(picture_of_me,
face_locations)[0]
encodings.append(my_face_encoding)
if encodings:
numpy.save(modelpath, encodings)
print(len(encodings))
print("model train is sucess")
else:
print("model train is failed")
5、人脸识别及跟踪
通过opencv启动摄像头并获取视频,加载训练好模型完成识别及跟踪,为避免视频卡顿设置了隔帧处理。
def predicvideo(self,names,model):
Video_face = cv2.VideoCapture(0)
num=0
recongnition=[]
unknown_face_locations=[]
while True:
flag, frame = Video_face.read();
frame = cv2.flip(frame, 1) # 镜像操作
num=num+1
if flag:
self.predictpeople(num, recongnition,unknown_face_locations,frame, names, encodings)
else:
break
Video_face.release()
def predictpeople(self, condition,recongnition,unknown_face_locations,unknown_picture,labels,encodings):
if condition%5==0:
face_locations = face_recognition.face_locations(unknown_picture)
unknown_face_encoding = face_recognition.face_encodings(unknown_picture,face_locations)
unknown_face_locations.clear()
recongnition.clear()
for index, value in enumerate(unknown_face_encoding):
unknown_face_locations.append(face_locations[index])
results = face_recognition.compare_faces(encodings, value, 0.4)
splitresult = numpy.array_split(results, len(labels))
trueNum=[]
a1 = ''
for item in splitresult:
number = numpy.sum(item)
trueNum.append(number)
if numpy.max(trueNum) > 0:
id = numpy.argsort(trueNum)[-1]
a1 = labels[id]
cv2.rectangle(unknown_picture,
pt1=(unknown_face_locations[index][1], unknown_face_locations[index][0]),
pt2=(unknown_face_locations[index][3], unknown_face_locations[index][2]),
color=[0, 0, 255],
thickness=2);
cv2.putText(unknown_picture, a1,
(unknown_face_locations[index][1], unknown_face_locations[index][0]),
cv2.FONT_ITALIC, 1, [0, 0, 255], 2);
else:
a1 = "unkown"
cv2.rectangle(unknown_picture,
pt1=(unknown_face_locations[index][1], unknown_face_locations[index][0]),
pt2=(unknown_face_locations[index][3], unknown_face_locations[index][2]),
color=[0, 0, 255],
thickness=2);
cv2.putText(unknown_picture, a1,
(unknown_face_locations[index][1], unknown_face_locations[index][0]),
cv2.FONT_ITALIC, 1, [0, 0, 255], 2);
recongnition.append(a1)
else:
self.drawRect(unknown_picture,recongnition,unknown_face_locations)
cv2.imshow('face', unknown_picture)
cv2.waitKey(1)
6、结语
通过opencv启动摄像头并获取实时视频,为避免过度卡顿采取隔帧处理;利用Facecognition实现模型的训练、保存、识别,二者结合实现了实时视频人脸的多人识别及跟踪,希望对大家有所帮助~!
到此这篇关于详解基于Facecognition+Opencv快速搭建人脸识别及跟踪应用的文章就介绍到这了,更多相关Facecognition+Opencv人脸识别 内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!