一. 连接池的原理
首先, HTTP连接是基于TCP连接的, 与服务器之间进行HTTP通信, 本质就是与服务器之间建立了TCP连接后, 相互收发基于HTTP协议的数据包. 因此, 如果我们需要频繁地去请求某个服务器的资源, 我们就可以一直维持与个服务器的TCP连接不断开, 然后在需要请求资源的时候, 把连接拿出来用就行了.
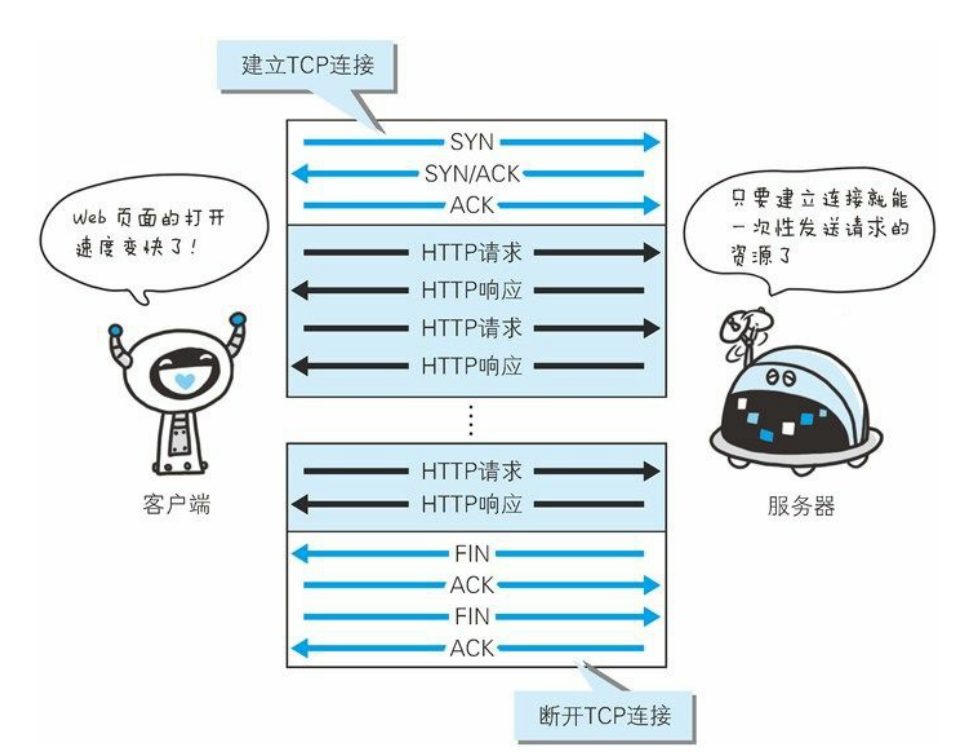
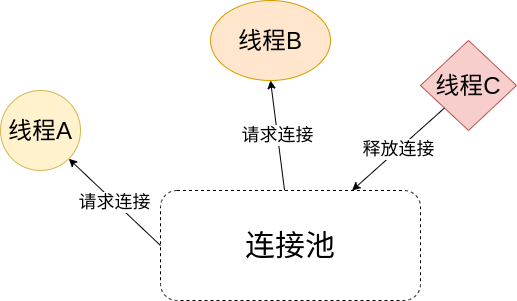
一个项目可能需要与服务器之间同时保持多个连接, 比如一个爬虫项目, 有的线程需要请求服务器的网页资源, 有的线程需要请求服务器的图片等资源, 而这些请求都可以建立在同一条TCP连接上.
因此, 我们使用一个管理器来对这些连接进行管理, 任何程序需要使用这些连接时, 向管理器申请就可以了, 等到用完之后再将连接返回给管理器, 以供其他程序重复使用, 这个管理器就是连接池.
二. 实现代码
1. HTTPConnectionPool类
基于上一章的分析, 连接池应该是一个收纳连接的容器, 同时对这些连接有管理能力:
class HTTPConnectionPool: def __init__(self, host: str, port: int = None, max_size: int = None, idle_timeout: int = None) -> None: """ :param host: pass :param port: pass :param max_size: 同时存在的最大连接数, 默认None->连接数无限,没了就创建 :param idle_timeout: 单个连接单次最长空闲时间,超时自动关闭,默认None->不限时 """ self.host = host self.port = port self.max_size = max_size self.idle_timeout = idle_timeout self._lock = threading.Condition() self._pool = [] # 这里的conn_num指的是总连接数,包括其它线程拿出去正在使用的连接 self.conn_num = 0 self.is_closed = False def acquire(self, blocking: bool = True, timeout: int = None) -> WrapperHTTPConnection: ... def release(self, conn: WrapperHTTPConnection) -> None: ...
因此, 我们定义这样一个HTTPConnectionPool类, 使用一个列表来保存可用的连接. 对于外部来说, 只需要调用这个连接池对象的acquire和release方法就能取得和释放连接.
2. 线程安全地管理连接
对于线程池内部来说, 至少需要三个关于连接的操作: 从连接池中取得连接, 将连接放回连接池, 以及创建一个连接:
def _get_connection(self) -> WrapperHTTPConnection: # 这个方法会把连接从_idle_conn移动到_used_conn列表中,并返回这个连接 try: return self._pool.pop() except IndexError: raise EmptyPoolError def _put_connection(self, conn: WrapperHTTPConnection) -> None: self._pool.append(conn) def _create_connection(self) -> WrapperHTTPConnection: self.conn_num += 1 return WrapperHTTPConnection(self, HTTPConnection(self.host, self.port))
对于连接池外部来说, 主要有申请连接和释放连接这两个操作, 实际上这就是个简单的生产者消费者模型. 考虑到外部可能是多线程的环境, 我们使用threading.Condition来保证线程安全. 关于Condition的资料可以看这里.
def acquire(self, blocking: bool = True, timeout: int = None) -> WrapperHTTPConnection:
if self.is_closed:
raise ConnectionPoolClosed
with self._lock:
if self.max_size is None or not self.is_full():
# 在还能创建新连接的情况下,如果没有空闲连接,直接创建一个就行了
if self.is_pool_empty():
self._put_connection(self._create_connection())
else:
# 不能创建新连接的情况下,如果设置了blocking=False,没连接就报错
# 否则,就基于timeout进行阻塞,直到超时或者有可用连接为止
if not blocking:
if self.is_pool_empty():
raise EmptyPoolError
elif timeout is None:
while self.is_pool_empty():
self._lock.wait()
elif timeout < 0:
raise ValueError("'timeout' must be a non-negative number")
else:
end_time = time.time() + timeout
while self.is_pool_empty():
remaining = end_time - time.time()
if remaining <= 0:
raise EmptyPoolError
self._lock.wait(remaining)
# 走到这一步了,池子里一定有空闲连接
return self._get_connection()
def release(self, conn: WrapperHTTPConnection) -> None:
if self.is_closed:
# 如果这个连接是在连接池关闭后才释放的,那就不用回连接池了,直接放生
conn.close()
return
# 实际上,python列表的append操作是线程安全的,可以不加锁
# 这里调用锁是为了通过notify方法通知其它正在wait的线程:现在有连接可用了
with self._lock:
if not conn.is_available:
# 如果这个连接不可用了,就应该创建一个新连接放进去,因为可能还有其它线程在等着连接用 conn.close() self.conn_num -= 1
conn = self._create_connection()
self._put_connection(conn)
self._lock.notify()
我们首先看看acquire方法, 这个方法其实就是在申请到锁之后调用内部的_get_connection方法获取连接, 这样就线程安全了. 需要注意的是, 如果当前的条件无法获取连接, 就会调用条件变量的wait方法, 及时释放锁并阻塞住当前线程. 然后, 当其它线程作为生产者调用release方法释放连接时, 会触发条件变量的notify方法, 从而唤醒一个阻塞在wait阶段的线程, 即消费者. 这个消费者再从池中取出刚放回去的线程, 这样整个生产者消费者模型就运转起来了.
3. 上下文管理器
对于一个程序来说, 它使用连接池的形式是获取连接->使用连接->释放连接. 因此, 我们应该通过with语句来管理这个连接, 以免在程序的最后遗漏掉释放连接这一步骤.
基于这个原因, 我们通过一个WrapperHTTPConnection类来对HTTPConnection进行封装, 以实现上下文管理器的功能. HTTPConnection的代码可以看《用python实现一个HTTP客户端》这篇文章.
class WrapperHTTPConnection: def __init__(self, pool: 'HTTPConnectionPool', conn: HTTPConnection) -> None: self.pool = pool self.conn = conn self.response = None self.is_available = True def __enter__(self) -> 'WrapperHTTPConnection': return self def __exit__(self, *exit_info: Any) -> None: # 如果response没读完并且连接需要复用,就弃用这个连接 if not self.response.will_close and not self.response.is_closed(): self.close() self.pool.release(self) def request(self, *args: Any, **kwargs: Any) -> HTTPResponse: self.conn.request(*args, **kwargs) self.response = self.conn.get_response() return self.response def close(self) -> None: self.conn.close() self.is_available = False
同样的, 连接池可能也需要关闭, 因此我们给连接池也加上上下文管理器的功能:
class HTTPConnectionPool: ... def close(self) -> None: if self.is_closed: return self.is_closed = True pool, self._pool = self._pool, None for conn in pool: conn.close() def __enter__(self) -> 'HTTPConnectionPool': return self def __exit__(self, *exit_info: Any) -> None: self.close()
这样, 我们就可以通过with语句优雅地管理连接池了:
with HTTPConnectionPool(**kwargs) as pool:
with pool.acquire() as conn:
res = conn.request('GET', '/')
...
4. 定时清理连接
如果一个连接池的所需连接数是随时间变化的, 那么就会出现一种情况: 在高峰期, 我们创建了非常多的连接, 然后进入低谷期之后, 连接过剩, 大量的连接处于空闲状态, 浪费资源. 因此, 我们可以设置一个定时任务, 定期清理空闲时间过长的连接, 减少连接池的资源占用.
首先, 我们需要为连接对象添加一个last_time属性, 每当连接释放进入连接池后, 就修改这个属性的值为当前时间, 这样我们就能明确知道, 连接池内的每个空闲连接空闲了多久:
class WrapperHTTPConnection: ... def __init__(self, pool: 'HTTPConnectionPool', conn: HTTPConnection) -> None: ... self.last_time = None class HTTPConnectionPool: ... def _put_connection(self, conn: WrapperHTTPConnection) -> None: conn.last_time = time.time() self._pool.append(conn)
然后, 我们通过threading.Timer来实现一个定时任务:
def start_clear_conn(self) -> None: if self.idle_timeout is None: # 如果空闲连接的超时时间为无限,那么就不应该清理连接 return self.clear_idle_conn() self._clearer = threading.Timer(self.idle_timeout, self.start_clear_conn) self._clearer.start() def stop_clear_conn(self) -> None: if self._clearer is not None: self._clearer.cancel()
threading.Timer只会执行一次定时任务, 因此, 我们需要在start_clear_conn中不断地把自己设置为定时任务. 这其实等同于新开了一个线程来执行start_clear_conn方法, 因此并不会出现递归过深问题. 不过需要注意的是, threading.Timer虽然不会阻塞当前线程, 但是却会阻止当前线程结束, 就算把它设置为守护线程都不行, 唯一可行的办法就是调用stop_clear_conn方法取消这个定时任务.
最后, 我们定义clear_idle_conn方法来清理闲置时间超时的连接:
def clear_idle_conn(self) -> None:
if self.is_closed:
raise ConnectionPoolClosed
# 这里开一个新线程来清理空闲连接,避免了阻塞主线程导致的定时精度出错
threading.Thread(target=self._clear_idle_conn).start()
def _clear_idle_conn(self) -> None:
if not self._lock.acquire(timeout=self.idle_timeout):
# 因为是每隔self.idle_timeout秒检查一次
# 如果过了self.idle_timeout秒还没申请到锁,下一次都开始了,本次也就不用继续了
return
current_time = time.time()
if self.is_pool_empty():
pass
elif current_time - self._pool[-1].last_time >= self.idle_timeout:
# 这里处理下面的二分法没法处理的边界情况,即所有连接都闲置超时的情况
self.conn_num -= len(self._pool)
self._pool.clear()
else:
# 通过二分法找出从左往右第一个不超时的连接的指针
left, right = 0, len(self._pool) - 1
while left < right:
mid = (left + right) // 2
if current_time - self._pool[mid].last_time >= self.idle_timeout:
left = mid + 1
else:
right = mid
self._pool = self._pool[left:]
self.conn_num -= left
self._lock.release()
由于我们获取和释放连接都是从self._pool的尾部开始操作的, 因此self._pool这个容器是一个先进后出队列, 它里面放着的连接, 一定是越靠近头部的闲置时间越长, 从头到尾闲置时间依次递减. 基于这个原因, 我们使用二分法来找出列表中第一个没有闲置超时的连接, 然后把在它之前的连接一次性删除, 这样就能达到O(logN)的时间复杂度, 算是一种比较高效的方法. 需要注意的是, 如果连接池内所有的连接都是超时的, 那么这种方法是删不干净的, 需要对这种边界情况单独处理.
三. 总结
1. 完整代码及分析
这个连接池的完整代码如下:
import threading
import time
from typing import Any
from client import HTTPConnection, HTTPResponse
class WrapperHTTPConnection:
def __init__(self, pool: 'HTTPConnectionPool', conn: HTTPConnection) -> None:
self.pool = pool
self.conn = conn
self.response = None
self.last_time = time.time()
self.is_available = True
def __enter__(self) -> 'WrapperHTTPConnection':
return self
def __exit__(self, *exit_info: Any) -> None:
# 如果response没读完并且连接需要复用,就弃用这个连接
if not self.response.will_close and not self.response.is_closed():
self.close()
self.pool.release(self)
def request(self, *args: Any, **kwargs: Any) -> HTTPResponse:
self.conn.request(*args, **kwargs)
self.response = self.conn.get_response()
return self.response
def close(self) -> None:
self.conn.close()
self.is_available = False
class HTTPConnectionPool:
def __init__(self, host: str, port: int = None, max_size: int = None, idle_timeout: int = None) -> None:
"""
:param host: pass
:param port: pass
:param max_size: 同时存在的最大连接数, 默认None->连接数无限,没了就创建
:param idle_timeout: 单个连接单次最长空闲时间,超时自动关闭,默认None->不限时
"""
self.host = host
self.port = port
self.max_size = max_size
self.idle_timeout = idle_timeout
self._lock = threading.Condition()
self._pool = []
# 这里的conn_num指的是总连接数,包括其它线程拿出去正在使用的连接
self.conn_num = 0
self.is_closed = False
self._clearer = None
self.start_clear_conn()
def acquire(self, blocking: bool = True, timeout: int = None) -> WrapperHTTPConnection:
if self.is_closed:
raise ConnectionPoolClosed
with self._lock:
if self.max_size is None or not self.is_full():
# 在还能创建新连接的情况下,如果没有空闲连接,直接创建一个就行了
if self.is_pool_empty():
self._put_connection(self._create_connection())
else:
# 不能创建新连接的情况下,如果设置了blocking=False,没连接就报错
# 否则,就基于timeout进行阻塞,直到超时或者有可用连接为止
if not blocking:
if self.is_pool_empty():
raise EmptyPoolError
elif timeout is None:
while self.is_pool_empty():
self._lock.wait()
elif timeout < 0:
raise ValueError("'timeout' must be a non-negative number")
else:
end_time = time.time() + timeout
while self.is_pool_empty():
remaining = end_time - time.time()
if remaining <= 0:
raise EmptyPoolError
self._lock.wait(remaining)
# 走到这一步了,池子里一定有空闲连接
return self._get_connection()
def release(self, conn: WrapperHTTPConnection) -> None:
if self.is_closed:
# 如果这个连接是在连接池关闭后才释放的,那就不用回连接池了,直接放生
conn.close()
return
# 实际上,python列表的append操作是线程安全的,可以不加锁
# 这里调用锁是为了通过notify方法通知其它正在wait的线程:现在有连接可用了
with self._lock:
if not conn.is_available:
# 如果这个连接不可用了,就应该创建一个新连接放进去,因为可能还有其它线程在等着连接用
conn.close()
self.conn_num -= 1
conn = self._create_connection()
self._put_connection(conn)
self._lock.notify()
def _get_connection(self) -> WrapperHTTPConnection:
# 这个方法会把连接从_idle_conn移动到_used_conn列表中,并返回这个连接
try:
return self._pool.pop()
except IndexError:
raise EmptyPoolError
def _put_connection(self, conn: WrapperHTTPConnection) -> None:
conn.last_time = time.time()
self._pool.append(conn)
def _create_connection(self) -> WrapperHTTPConnection:
self.conn_num += 1
return WrapperHTTPConnection(self, HTTPConnection(self.host, self.port))
def is_pool_empty(self) -> bool:
# 这里指的是,空闲可用的连接是否为空
return len(self._pool) == 0
def is_full(self) -> bool:
if self.max_size is None:
return False
return self.conn_num >= self.max_size
def close(self) -> None:
if self.is_closed:
return
self.is_closed = True
self.stop_clear_conn()
pool, self._pool = self._pool, None
for conn in pool:
conn.close()
def clear_idle_conn(self) -> None:
if self.is_closed:
raise ConnectionPoolClosed
# 这里开一个新线程来清理空闲连接,避免了阻塞主线程导致的定时精度出错
threading.Thread(target=self._clear_idle_conn).start()
def _clear_idle_conn(self) -> None:
if not self._lock.acquire(timeout=self.idle_timeout):
# 因为是每隔self.idle_timeout秒检查一次
# 如果过了self.idle_timeout秒还没申请到锁,下一次都开始了,本次也就不用继续了
return
current_time = time.time()
if self.is_pool_empty():
pass
elif current_time - self._pool[-1].last_time >= self.idle_timeout:
# 这里处理下面的二分法没法处理的边界情况,即所有连接都闲置超时的情况
self.conn_num -= len(self._pool)
self._pool.clear()
else:
# 通过二分法找出从左往右第一个不超时的连接的指针
left, right = 0, len(self._pool) - 1
while left < right:
mid = (left + right) // 2
if current_time - self._pool[mid].last_time >= self.idle_timeout:
left = mid + 1
else:
right = mid
self._pool = self._pool[left:]
self.conn_num -= left
self._lock.release()
def start_clear_conn(self) -> None:
if self.idle_timeout is None:
# 如果空闲连接的超时时间为无限,那么就不应该清理连接
return
self.clear_idle_conn()
self._clearer = threading.Timer(self.idle_timeout, self.start_clear_conn)
self._clearer.start()
def stop_clear_conn(self) -> None:
if self._clearer is not None:
self._clearer.cancel()
def __enter__(self) -> 'HTTPConnectionPool':
return self
def __exit__(self, *exit_info: Any) -> None:
self.close()
class EmptyPoolError(Exception):
pass
class ConnectionPoolClosed(Exception):
pass
首先, 这个连接池的核心就是对连接进行管理, 而这包含取出连接和释放连接两个过程. 因此这东西的本质就是一个生产者消费者模型, 取出线程时是消费者, 放入线程时是生产者, 使用threading自带的Condition对象就能完美解决线程安全问题, 使二者协同合作.
解决获取连接和释放连接这个问题之后, 其实这个连接池就已经能用了. 但是如果涉及到更多细节方面的东西, 比如判断连接是否可用, 自动释放连接, 清理闲置连接等等, 就需要对这个连接进行封装, 为它添加更多的属性和方法, 这就引入了WrapperHTTPConnection这个类. 实现它的__enter___和__exit__方法之后, 就能使用上下文管理器来自动释放连接. 至于清理闲置连接, 通过last_time属性记录每个连接的最后释放时间, 然后在连接池中添加一个定时任务就行了.
以上就是如何用python实现一个HTTP连接池的详细内容,更多关于python 实现一个HTTP连接池的资料请关注易盾网络其它相关文章!