目标: 由于之前和朋友聊到抖音评论的爬虫,demo做出来之后一直没整理,最近时间充裕后,在这里做个笔记。 提示:大体思路 通过fiddle + app模拟器进行抖音抓包,使用python进行数据整
目标:
由于之前和朋友聊到抖音评论的爬虫,demo做出来之后一直没整理,最近时间充裕后,在这里做个笔记。
提示:大体思路 通过fiddle + app模拟器进行抖音抓包,使用python进行数据整理
安装需要的工具:
python3 下载
fiddle 安装及配置
手机模拟器下载
抖音部分:
模拟器下载好之后, 打开模拟器
在应用市场下载抖音

对抖音进行fiddle配置,配置成功后就可以当手机一样使用了
一、工具配置及抓包:
我们随便打开一个视频之后,fiddle就会刷新新的数据包
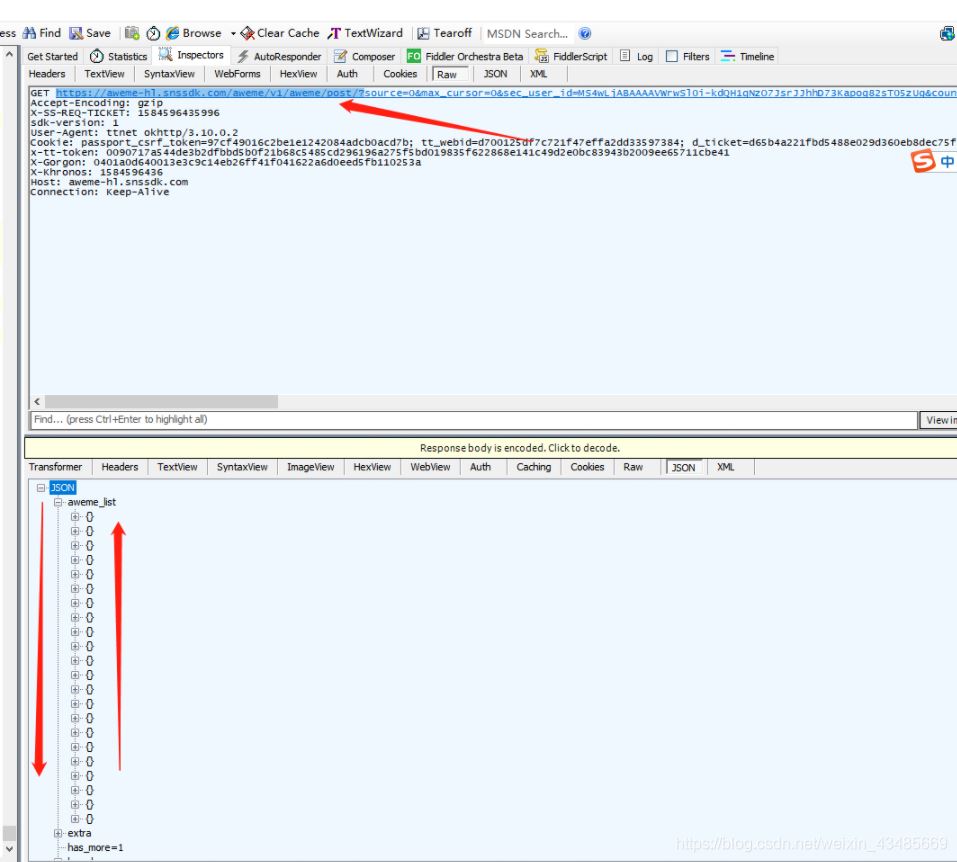
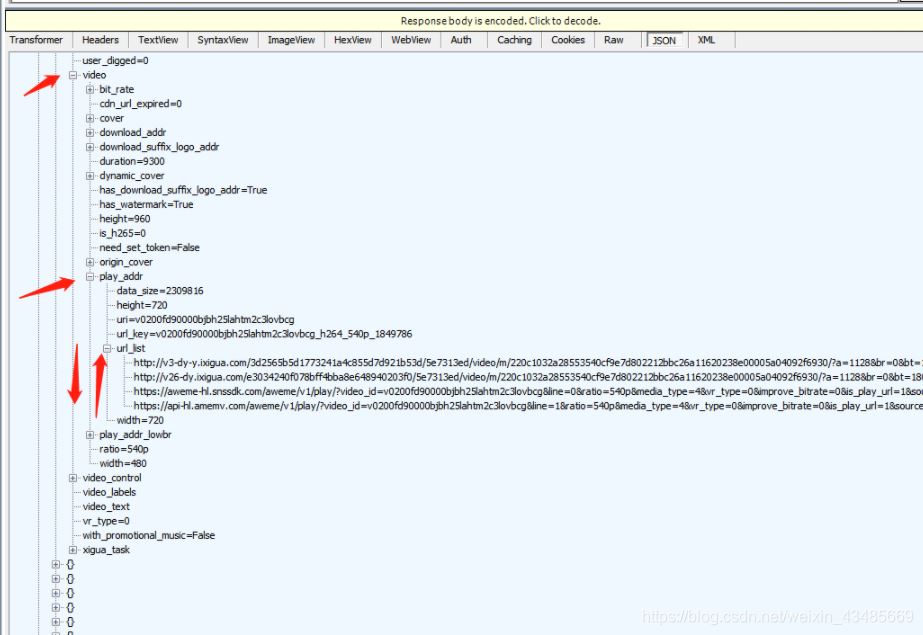
在json中找到视频地址:
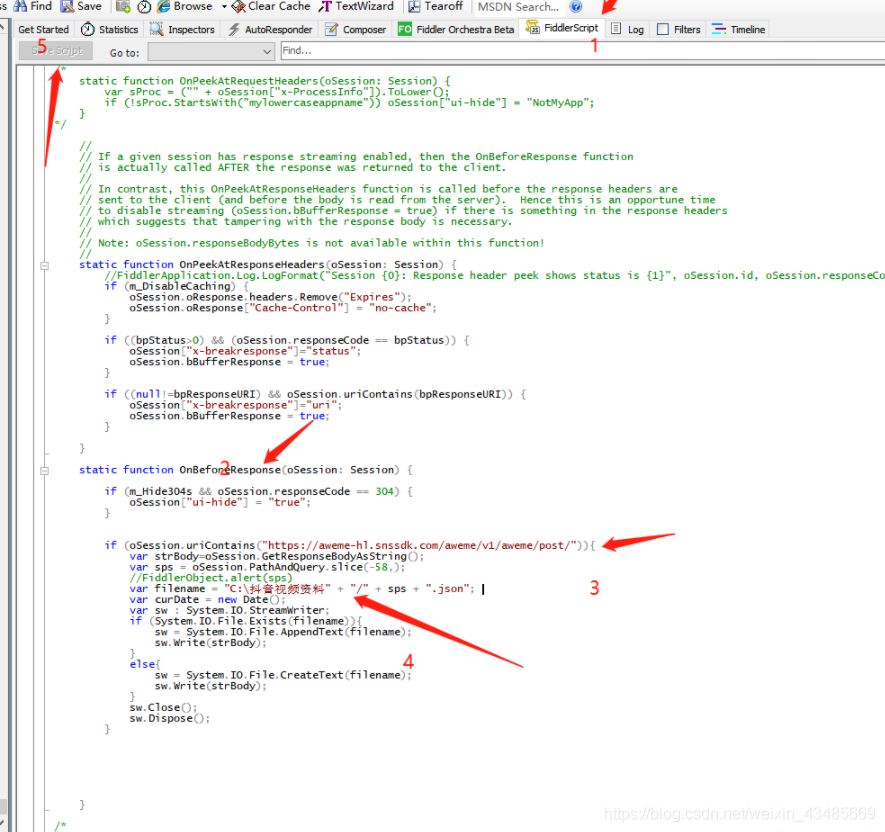
二、fiddler中添加下载视频评论代码
在fiddler中添加下载视频代码:注意两点:
(1)get后面的路径要随时看进行更换
(2)下载的路径要在fiddler下面自己新建
if (m_Hide304s && oSession.responseCode == 304) {
oSession["ui-hide"] = "true";
}
if (oSession.uriContains("https://aweme.snssdk.com/aweme/v1/general/search/single/")){
var strBody=oSession.GetResponseBodyAsString();
var sps = oSession.PathAndQuery.slice(-58,);
//FiddlerObject.alert(sps)
var timestamp=new Date().getTime();
var filename = "D:\抖音评论资料" + "/" + sps + timestamp + ".json";
var curDate = new Date();
var sw : System.IO.StreamWriter;
if (System.IO.File.Exists(filename)){
sw = System.IO.File.AppendText(filename);
sw.Write(strBody);
}
else{
sw = System.IO.File.CreateText(filename);
sw.Write(strBody);
}
sw.Close();
sw.Dispose();
此段代码放到fiddler中的script的response中,如下图:添加好之后别忘记保存!!
三、python执行代码pycharm新建py文件
程序执行代码:
import os
import json
import time
import requests
import re
import csv
class Douyin(object):
def __init__(self):
pass
self.url1 = 'https://aweme.snssdk.com/aweme/v2/comment/list/?aweme_id=6885929189950737676&cursor=0&count=20&address_book_access=1&gps_access=1&forward_page_type=1&channel_id=0&city=310000&hotsoon_filtered_count=0&hotsoon_has_more=0&follower_count=0&is_familiar=0&page_source=0&os_api=25&device_type=VOG-AL00&ssmix=a&manifest_version_code=110301&dpi=240&uuid=868594157367551&app_name=aweme&version_name=11.3.0&ts=1603350069&cpu_support64=false&app_type=normal&ac=wifi&host_abi=armeabi-v7a&channel=aweGW&update_version_code=11309900&_rticket=1603350070959&device_platform=android&iid=1758845207590062&version_code=110300&mac_address=b0%3Ac4%3A2d%3Ad0%3Aed%3A38&cdid=7974198e-c4c0-49c2-bfaa-43686052706e&openudid=d0c6cffa7067bedd&device_id=844047245117672&resolution=720*1280&device_brand=HUAWEI&language=zh&os_version=7.1.2&aid=1128&mcc_mnc=46000'
self.url2 = 'https://aweme.snssdk.com/aweme/v2/comment/list/?aweme_id=6885163969477086479&cursor=0&count=20'
self.header = {
'Accept-Encoding': 'gzip',
'X-SS-REQ-TICKET': '1603350070957',
'sdk-version': '1',
'Cookie': 'install_id=1758845207590062; ttreq=1$34f012b99d70a66f681dc3d1f0b438fc1b161af3; d_ticket=77247c94236bf8055c233f8cabb6a5ddf3231; odin_tt=fccb20add45a15f08a2519eadcaaf22cba4b3f8f1fceec300a088407c2daf81ea76b260ef6c81dbc86dfedfea011f68c25238f9b3984fe4f5909441dfd1cc9c2; sid_guard=6de18a966e69dcbbf076f629a2ef6511%7C1603345424%7C5184000%7CMon%2C+21-Dec-2020+05%3A43%3A44+GMT; uid_tt=ba98af780b4e337f01463cf98a8afafd; sid_tt=6de18a966e69dcbbf076f629a2ef6511; sessionid=6de18a966e69dcbbf076f629a2ef6511',
'x-tt-token': '006de18a966e69dcbbf076f629a2ef651189d3f6f73fd3d6319b543d50d2e2e5a4cf3e383f8da81f07e049bcf850de07d331',
'X-Gorgon': '0404d8210000a6a3dca0dbc6b11483a82420c9a94dd050a3e511',
'X-Khronos': '1603350070',
'Host': 'aweme.nssdk.com',
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36',
}
self.add = 'D:\抖音评论资料'
self.videos_list = os.listdir('D:\抖音评论资料')
def parse(self):
'链接,内容,发布人昵称,发布时间,点赞数,评论数,分享数'
lists = []
for vid in self.videos_list:
a = open('D:\抖音评论资料\{}'.format(vid),encoding='utf-8')
content = json.load(a)
for con in content['data']:
meta = {}
try:
meta['title'] = con['aweme_info']['desc']
meta['author_name'] = con['aweme_info']['author']['nickname']
meta['u_name'] = con['aweme_info']['author']['unique_id']
meta['create_time'] = con['aweme_info']['create_time']
timeArray = time.localtime(meta['create_time'])
meta['create_time'] = time.strftime("%Y--%m--%d %H:%M:%S", timeArray)
meta['digg_count'] = con['aweme_info']['statistics']['digg_count']
meta['comment_count'] = con['aweme_info']['statistics']['comment_count']
meta['share_count'] = con['aweme_info']['statistics']['share_count']
meta['share_url'] = con['aweme_info']['share_url']
except:
meta['title'] = ''
meta['author_name'] = ''
meta['u_name'] = ''
meta['create_time'] = ''
meta['digg_count'] = ''
meta['comment_count'] = ''
meta['share_count'] = ''
meta['share_url'] = ''
if meta['u_name'] == '':
try:
meta['u_name'] = con['aweme_info']['music']['owner_handle']
except:
meta['u_name'] = ''
if meta['title'] == '':
pass
else:
lists.append(meta)
# print(meta)
return lists
def save_data(self, meta):
header = ['share_url', 'title', 'author_name', 'u_name', 'create_time', 'digg_count', 'comment_count', 'share_count']
print(meta)
with open('test.csv', 'a', newline='', encoding='utf-8-sig') as f:
writer = csv.DictWriter(f, fieldnames=header)
writer.writeheader() # 写入列名
writer.writerows(meta)
def run(self):
meta = self.parse()
self.save_data(meta)
if __name__ == '__main__':
douyin = Douyin()
douyin.run()
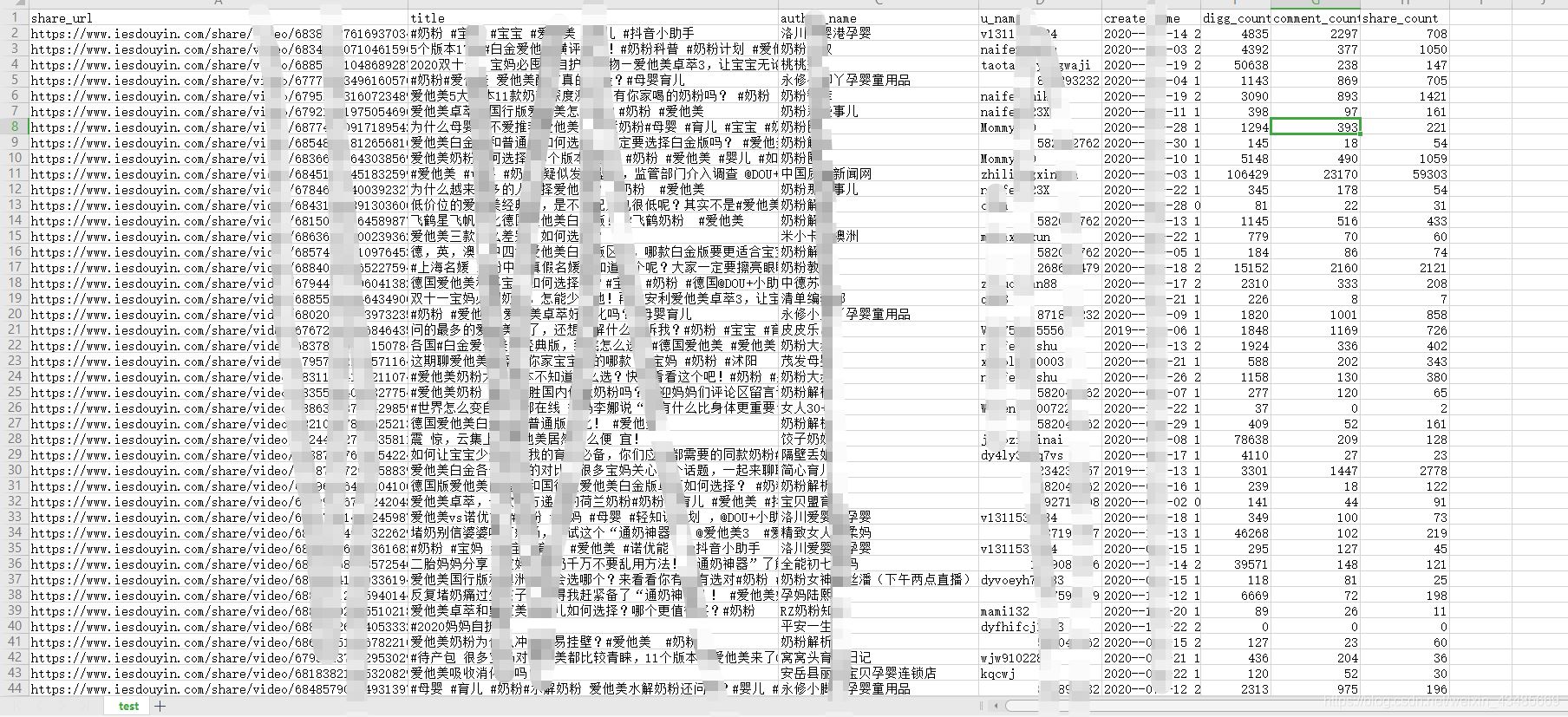
运行代码后在代码执行目录下会生成一个excel
ps:抖音不会一次性返回整个评论数据包,每次往下滑动评论区会多出26条评论数据,我们就可以利用模拟器进行滑动操作。
点击 更多>鼠标宏
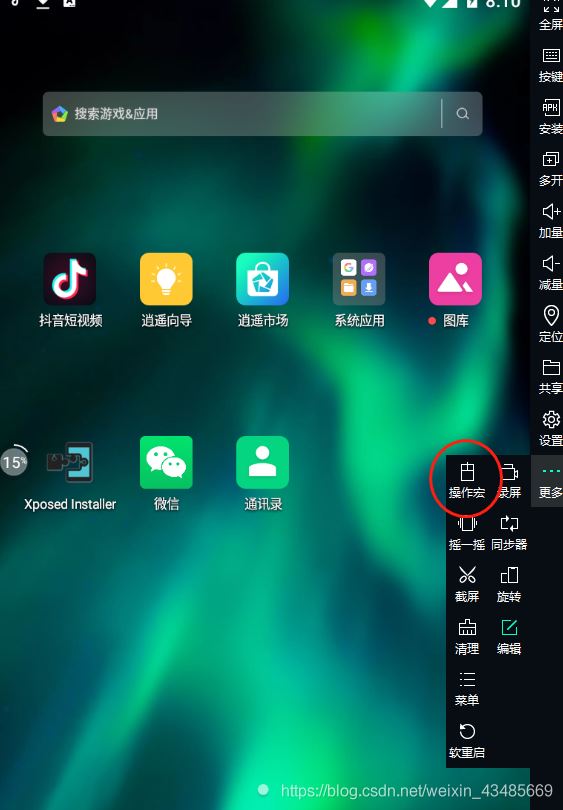
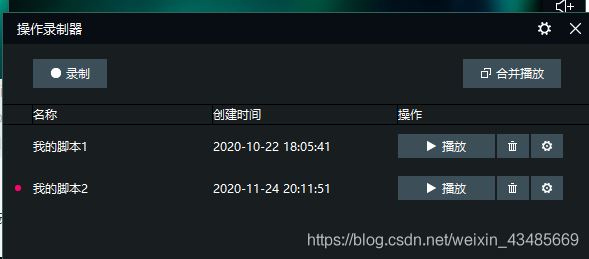
点击录屏之后,用鼠标往下滑动一次页面

点击停止,就会将你刚才的操作保存下来
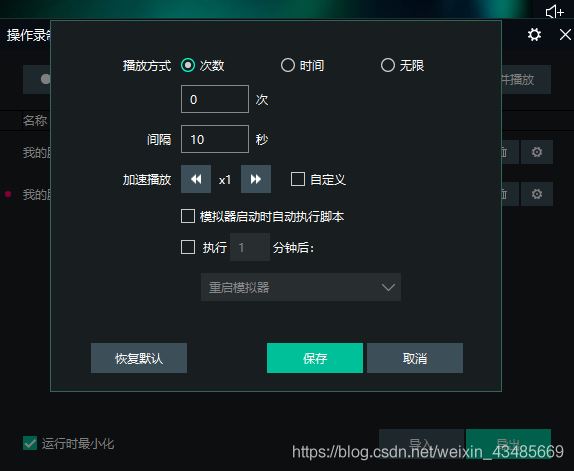
点击设置 可以对刚才的操作进行循环播放,从而达到自动刷新评论区。
到此这篇关于python实现模拟器爬取抖音评论数据的示例代码的文章就介绍到这了,更多相关python 拟器爬取数据内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!