Python 爬虫包含两个重要的部分:正则表达式和Scrapy框架的运用, 正则表达式对于所有语言都是通用的,网络上可以找到各种资源。 如下是手绘Scrapy框架原理图,帮助理解 如下是一段运
Python 爬虫包含两个重要的部分:正则表达式和Scrapy框架的运用, 正则表达式对于所有语言都是通用的,网络上可以找到各种资源。
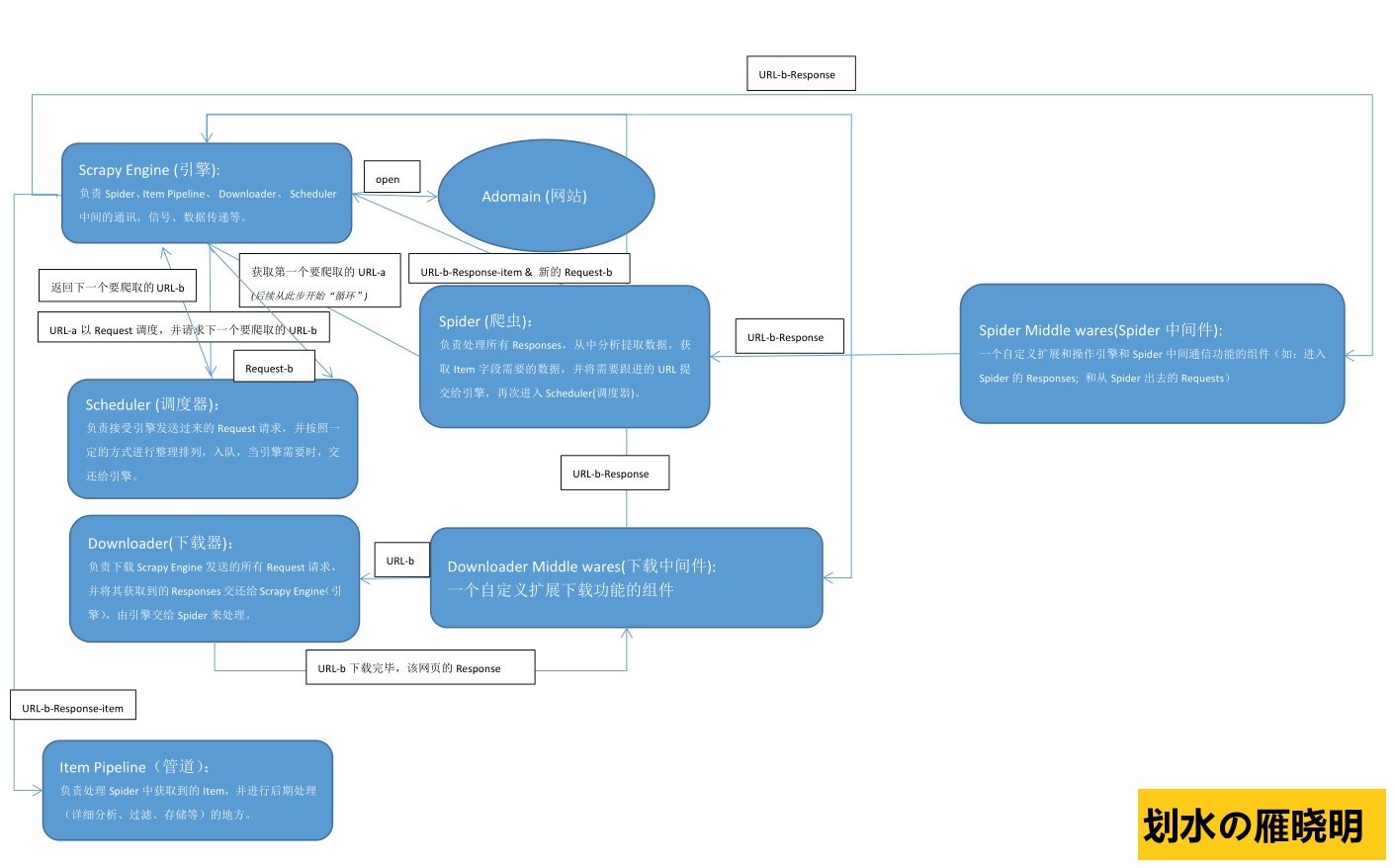
如下是手绘Scrapy框架原理图,帮助理解
如下是一段运用Scrapy创建的spider:使用了内置的crawl模板,以利用Scrapy库的CrawlSpider。相对于简单的爬取爬虫来说,Scrapy的CrawlSpider拥有一些网络爬取时可用的特殊属性和方法:
$ scrapy genspider country_or_district example.python-scrapying.com--template=crawl
运行genspider命令后,下面的代码将会在example/spiders/country_or_district.py中自动生成。
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from example.items import CountryOrDistrictItem
class CountryOrDistrictSpider(CrawlSpider):
name = 'country_or_district'
allowed_domains = ['example.python-scraping.com']
start_urls = ['http://example.python-scraping.com/']
rules = (
Rule(LinkExtractor(allow=r'/index/', deny=r'/user/'),
follow=True),
Rule(LinkExtractor(allow=r'/view/', deny=r'/user/'),
callback='parse_item'),
)
def parse_item(self, response):
item = CountryOrDistrictItem()
name_css = 'tr#places_country_or_district__row td.w2p_fw::text'
item['name'] = response.css(name_css).extract()
pop_xpath = '//tr[@id="places_population__row"]/td[@class="w2p_fw"]/text()'
item['population'] = response.xpath(pop_xpath).extract()
return item
爬虫类包括的属性:
- name: 识别爬虫的字符串。
- allowed_domains: 可以爬取的域名列表。如果没有设置该属性,则表示可以爬取任何域名。
- start_urls: 爬虫起始URL列表。
- rules: 该属性为一个通过正则表达式定义的Rule对象元组,用于告知爬虫需要跟踪哪些链接以及哪些链接包含抓取的有用内容。
以上就是python Scrapy框架原理解析的详细内容,更多关于Scrapy框架原理的资料请关注易盾网络其它相关文章!