在过去的几十年里,机器学习对世界产生了巨大的影响,而且它的普及程度似乎在不断增长。最近,越来越多的人已经熟悉了机器学习的子领域,如神经网络,这是由人类大脑启发的网络。在本文中,将介绍用于一个简单神经网络的 Python 代码,该神经网络对于一个 1x3 向量,分类第一个元素是否为 10。
步骤1: 导入 NumPy、 Scikit-learn 和 Matplotlib
import numpy as np from sklearn.preprocessing import MinMaxScaler import matplotlib.pyplot as plt
我们将在这个项目中使用上述三个库。NumPy 将用于创建向量和矩阵以及数学操作。Scikit-learn 将用于缩放数据,Matplotlib 将用于在神经网络训练期间绘图。
步骤2: 创建一个训练和测试数据集
神经网络在大型和小型数据集的学习趋势方面都很擅长。然而,数据科学家必须意识到过拟合的危险,这在使用小数据集的项目中更为明显。过拟合是当一个算法训练和建模过于接近一组数据点,以至于它不能很好地推广到新的数据点。
通常情况下,过拟合的机器学习模型在训练的数据集上有很高的准确性,但是作为一个数据科学家,目标通常是尽可能精确地预测新的数据点。为了确保根据预测新数据点的好坏来评估模型,而不是根据对当前数据点的建模好坏来评估模型,通常将数据集拆分为一个训练集和一个测试集(有时是一个验证集)。
input_train = np.array([[0, 1, 0], [0, 1, 1], [0, 0, 0], [10, 0, 0], [10, 1, 1], [10, 0, 1]]) output_train = np.array([[0], [0], [0], [1], [1], [1]]) input_pred = np.array([1, 1, 0]) input_test = np.array([[1, 1, 1], [10, 0, 1], [0, 1, 10], [10, 1, 10], [0, 0, 0], [0, 1, 1]]) output_test = np.array([[0], [1], [0], [1], [0], [0]])
在这个简单的神经网络中,我们将1x3向量分类,10作为第一个元素。使用 NumPy 的 array 函数创建输入和输出训练集和测试集,并创建 input_pred 以测试稍后将定义的 prediction 函数。训练和测试数据由6个样本组成,每个样本具有3个特征,由于输出已经给出,我们理解这是监督式学习的一个例子。
第三步: 扩展数据集
许多机器学习模型不能理解例如单位之间的区别,自然而然地对高度的特征应用更多的权重。这会破坏算法预测新数据点的能力。此外,训练具有高强度特征的机器学习模型将会比需要的慢,至少如果使用梯度下降法。这是因为当输入值在大致相同的范围内时,梯度下降法收敛得更快。
scaler = MinMaxScaler() input_train_scaled = scaler.fit_transform(input_train) output_train_scaled = scaler.fit_transform(output_train) input_test_scaled = scaler.fit_transform(input_test) output_test_scaled = scaler.fit_transform(output_test)
在我们的训练和测试数据集中,这些值的范围相对较小,因此可能没有必要进行特征扩展。然而,这样可以使得小伙伴们使用自己喜欢的数字,而不需要更改太多的代码。由于 Scikit-learn 包及其 MinMaxScaler 类,在 Python 中实现特征伸缩非常容易。只需创建一个 MinMaxScaler 对象,并使用 fit_transform 函数将非缩放数据作为输入,该函数将返回相同的缩放数据。Scikit-learn 包中还有其他缩放功能,我鼓励您尝试这些功能。
第四步: 创建一个神经网络类
要熟悉神经网络的所有元素,最简单的方法之一就是创建一个神经网络类。这样一个类应该包括所有的变量和函数,将是必要的神经网络工作正常。
class NeuralNetwork():
def __init__(self, ):
self.inputSize = 3
self.outputSize = 1
self.hiddenSize = 3
self.W1 = np.random.rand(self.inputSize, self.hiddenSize)
self.W2 = np.random.rand(self.hiddenSize, self.outputSize)
self.error_list = []
self.limit = 0.5
self.true_positives = 0
self.false_positives = 0
self.true_negatives = 0
self.false_negatives = 0
def forward(self, X):
self.z = np.matmul(X, self.W1)
self.z2 = self.sigmoid(self.z)
self.z3 = np.matmul(self.z2, self.W2)
o = self.sigmoid(self.z3)
return o
def sigmoid(self, s):
return 1 / (1 + np.exp(-s))
def sigmoidPrime(self, s):
return s * (1 - s)
def backward(self, X, y, o):
self.o_error = y - o
self.o_delta = self.o_error * self.sigmoidPrime(o)
self.z2_error = np.matmul(self.o_delta,
np.matrix.transpose(self.W2))
self.z2_delta = self.z2_error * self.sigmoidPrime(self.z2)
self.W1 += np.matmul(np.matrix.transpose(X), self.z2_delta)
self.W2 += np.matmul(np.matrix.transpose(self.z2),
self.o_delta)
def train(self, X, y, epochs):
for epoch in range(epochs):
o = self.forward(X)
self.backward(X, y, o)
self.error_list.append(np.abs(self.o_error).mean())
def predict(self, x_predicted):
return self.forward(x_predicted).item()
def view_error_development(self):
plt.plot(range(len(self.error_list)), self.error_list)
plt.title('Mean Sum Squared Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
def test_evaluation(self, input_test, output_test):
for i, test_element in enumerate(input_test):
if self.predict(test_element) > self.limit and \
output_test[i] == 1:
self.true_positives += 1
if self.predict(test_element) < self.limit and \
output_test[i] == 1:
self.false_negatives += 1
if self.predict(test_element) > self.limit and \
output_test[i] == 0:
self.false_positives += 1
if self.predict(test_element) < self.limit and \
output_test[i] == 0:
self.true_negatives += 1
print('True positives: ', self.true_positives,
'\nTrue negatives: ', self.true_negatives,
'\nFalse positives: ', self.false_positives,
'\nFalse negatives: ', self.false_negatives,
'\nAccuracy: ',
(self.true_positives + self.true_negatives) /
(self.true_positives + self.true_negatives +
self.false_positives + self.false_negatives))
步骤4.1: 创建一个 Initialize 函数
当我们在 Python 中创建一个类以便正确地初始化变量时,会调用 __init__ 函数。
def __init__(self, ): self.inputSize = 3 self.outputSize = 1 self.hiddenSize = 3 self.W1 = torch.randn(self.inputSize, self.hiddenSize) self.W2 = torch.randn(self.hiddenSize, self.outputSize) self.error_list = [] self.limit = 0.5 self.true_positives = 0 self.false_positives = 0 self.true_negatives = 0 self.false_negatives = 0
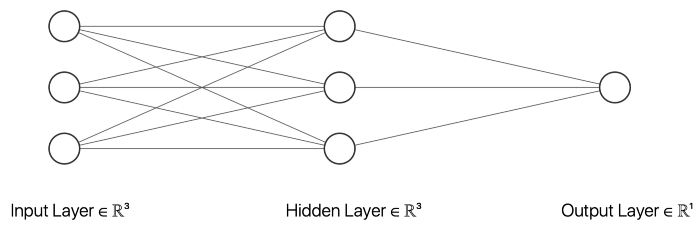
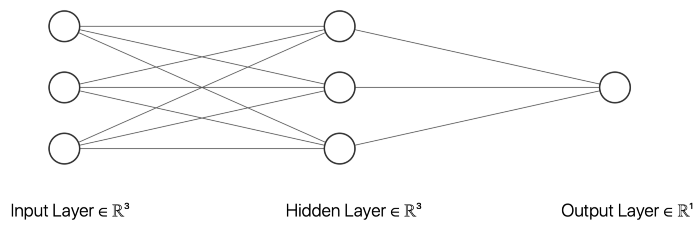
在这个例子中,我选择了一个有三个输入节点、三个隐藏层节点和一个输出节点的神经网络。以上的 __init__ 函数初始化描述神经网络大小的变量。inputSize 是输入节点的数目,它应该等于输入数据中特征的数目。outputSize 等于输出节点数,hiddenSize 描述隐藏层中的节点数。此外,我们的网络中不同节点之间的权重将在训练过程中进行调整。
除了描述神经网络的大小和权重的变量之外,我还创建了几个在创建神经网络对象时初始化的变量,这些对象将用于评估目的。误差列表将包含每个时期的平均绝对误差(MAE) ,这个极限将描述一个向量应该被分类为一个向量,元素10作为第一个元素而不是。然后,还有一些变量可以用来存储真实阳性、假阳性、真实阴性和假阴性的数量。
步骤4.2: 创建一个前向传播函数
前向传播函数的作用是通过神经网络的不同层次进行迭代,以预测特定 epoch 的输出。然后,根据预测输出和实际输出之间的差异,在反向传播的过程中更新权重。
def forward(self, X): self.z = np.matmul(X, self.W1) self.z2 = self.sigmoid(self.z) self.z3 = np.matmul(self.z2, self.W2) o = self.sigmoid(self.z3) return o
为了计算每一层中每个节点的值,前一层中节点的值将被乘以适当的权重,然后应用非线性激活函数来扩大最终输出函数的可能性。在这个例子中,我们选择了 Sigmoid 作为激活函数,但也有许多其他的选择。
步骤4.3: 创建一个反向传播函数
反向传播是对神经网络中不同节点的权值进行更新,从而决定其重要性的过程。
def backward(self, X, y, o):
self.o_error = y - o
self.o_delta = self.o_error * self.sigmoidPrime(o)
self.z2_error = np.matmul(self.o_delta,
np.matrix.transpose(self.W2))
self.z2_delta = self.z2_error * self.sigmoidPrime(self.z2)
self.W1 += np.matmul(np.matrix.transpose(X), self.z2_delta)
self.W2 += np.matmul(np.matrix.transpose(self.z2),
self.o_delta)
在上面的代码片段中,输出层的输出错误被计算为预测输出与实际输出之间的差值。然后,在重复整个过程直到到达输入层之前,将这个错误与 Sigmoid 相乘以运行梯度下降法。最后,更新不同层之间的权重。
步骤4.4: 创建一个训练函数
在训练过程中,该算法将运行向前和向后传递,从而更新每个 epoch 的权重。为了得到最精确的权重值,这是必要的。
def train(self, X, y, epochs): for epoch in range(epochs): o = self.forward(X) self.backward(X, y, o) self.error_list.append(np.abs(self.o_error).mean())
除了向前和向后传播之外,我们还将平均绝对误差(MAE)保存到一个错误列表中,以便日后观察平均绝对误差在训练过程中是如何演变的。
步骤4.5: 创建一个预测函数
在训练过程中对权重进行了微调之后,该算法就可以预测新数据点的输出。预测的输出数字有望与实际输出数字非常接近。
def predict(self, x_predicted): return self.forward(x_predicted).item()
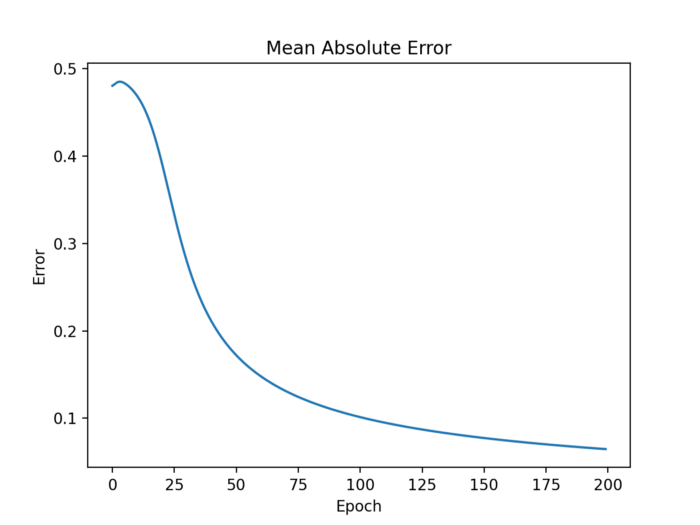
步骤4.6: 绘制平均绝对误差发展图
评价机器学习算法质量的方法有很多。经常使用的测量方法之一是平均绝对误差,这个误差应该随着时间的推移而减小。
def view_error_development(self):
plt.plot(range(len(self.error_list)), self.error_list)
plt.title('Mean Sum Squared Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
步骤4.7: 计算精度及其组成部分
真正、假正、真负和假负的数量描述了机器学习分类算法的质量。训练后的神经网络权值更新,使算法能够准确地预测新的数据点。在二进制分类任务中,这些新数据点只能是1或0。根据预测值是否高于或低于定义的限制,算法将新条目分为1或0。
def test_evaluation(self, input_test, output_test):
for i, test_element in enumerate(input_test):
if self.predict(test_element) > self.limit and \
output_test[i] == 1:
self.true_positives += 1
if self.predict(test_element) < self.limit and \
output_test[i] == 1:
self.false_negatives += 1
if self.predict(test_element) > self.limit and \
output_test[i] == 0:
self.false_positives += 1
if self.predict(test_element) < self.limit and \
output_test[i] == 0:
self.true_negatives += 1
print('True positives: ', self.true_positives,
'\nTrue negatives: ', self.true_negatives,
'\nFalse positives: ', self.false_positives,
'\nFalse negatives: ', self.false_negatives,
'\nAccuracy: ',
(self.true_positives + self.true_negatives) /
(self.true_positives + self.true_negatives +
self.false_positives + self.false_negatives))
当运行 test _ evaluation 函数时,我们得到以下结果:
真正: 2
真负: 4
假正: 0
假负: 0
准确性由以下公式给出:
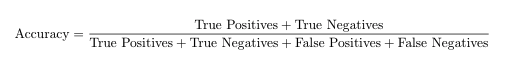
由此我们可以推断,在我们的案例中,精确度是1。
第五步: 运行一个脚本来训练和评估神经网络模型
NN = NeuralNetwork() NN.train(input_train_scaled, output_train_scaled, 200) NN.predict(input_pred) NN.view_error_development() NN.test_evaluation(input_test_scaled, output_test_scaled)
为了尝试我们刚刚构建的神经网络类,我们将首先初始化一个神经网络类型的对象。然后对训练数据进行神经网络训练,在新训练的模型在测试向量上进行测试之前,对算法的权值进行200个 epoch 以上的“修正”。然后,在利用测试数据集对模型进行评估之前,绘制误差图。
第六步: 改进脚本并使用它
提供的代码可以很容易地修改,以处理其他类似的情况。我们鼓励读者尝试改变变量并使用自己的数据等等。改进或变更的潜在想法包括但不限于:
- 泛化代码以适用于任何输入和输出大小的数据
- 使用平均绝对误差以外的另一个度量来衡量误差
- 使用其他的缩放函数
到此这篇关于Python创建简单的神经网络实例讲解的文章就介绍到这了,更多相关如何在Python中创建一个简单的神经网络内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!