案例故事: 之前我们做Android手机测试的时候, 市场部希望我们测试部进行Top 1000 app(排名前1000的app)的兼容性测试, 以确保我们的手机是可以安装并正常运行这么多好用的app, 且市场
案例故事:
之前我们做Android手机测试的时候,
市场部希望我们测试部进行Top 1000 app(排名前1000的app)的兼容性测试,
以确保我们的手机是可以安装并正常运行这么多好用的app,
且市场部提供了某应用市场上的top 1000 的apk下载地址。

如何实现快速批量地下载apk文件呢?
准备阶段
以上excel里的的url分明是需要进行二次重定向的,因为其不是一个.apk结尾的链接,
我们需要进行解析后再进行重定向。wget命令是不支持这url重定向解析的,所以不能采用。
所以我们还是采用requests模块来实现下载。
Python批处理脚本形式 单线程的写法
记住批处理脚本的精髓:批量顺序执行语句,
由于批处理脚本形式只能实现单个apk的下载任务,我们使用requests模块实现下载。
单线程效率比较慢,必须等前一个apk下载完毕后,才会开始后一个apk的下载。
# coding=utf-8
import os
import requests
import openpyxl
curdir = os.getcwd() # 获取当前路径current work directory
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1 WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.93 Safari/537.36'}
# 创建文件夹用于存放已经下载的apk
if not os.path.exists("downloaded_apk"):
os.system("mkdir downloaded_apk")
# 逐行读取excel里的下载地址url
excel = openpyxl.load_workbook('Top_1000_app.xlsx') # 读取excel里边的内容
table = excel.active
rows = table.max_row
for r in range(2, rows + 1): # 跟excel的第一行标题行无关,从第二行文字内容开始
apk_name = table.cell(row=r, column=2).value # 获取app名字(中文)
apk_url = table.cell(row=r, column=3).value # 获取下载地址
save_path = os.path.join(curdir, "downloaded_apk", "%s.apk" % apk_name)
if not os.path.exists(save_path): # 避免二次下载
print("Downloading the %sth apk and will save to %s" % (r, save_path))
try:
r = requests.get(apk_url, headers=header, allow_redirects=True, timeout=720) # 发起requests下载请求
status_code = r.status_code
if (status_code == 200 or status_code == 206):
with open(save_path, "wb") as hf:
hf.write(r.content)
except:
print("Error, can not download %s.apk" % apk_name)
else:
print("%s downloaded already!" % save_path)
os.system("pause")
Python面向对象类形式 多线程下载的写法
准备阶段
多线程一般效率快很多很多,
多线程任务执行,一般是将apk下载任务放到Queue队列里去,先进先出,
然后只要队列不是空队列,就从队列里边取任务(q_job),并有10个线程同时进行,
相对来说,理解上会较难一些些,但是掌握后,可以快速提高下载效率。
#coding=utf-8
import os
import queue
import threading
import requests
import openpyxl
curdir = os.getcwd() #获取当前路径current work directory
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1 WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.93 Safari/537.36'}
# 创建文件夹
if not os.path.exists("downloaded_apk"):
os.system("mkdir downloaded_apk")
def download_single_apk(apk_url_str):
'''下载单个apk文件'''
apk_name, apk_url = apk_url_str.split(";")
# print(apk_url)
save_path = os.path.join(curdir, "downloaded_apk", "%s.apk" % apk_name)
if not os.path.exists(save_path): # 避免二次下载
print("Downloading %s" % (save_path))
try:
r = requests.get(apk_url, headers=header, allow_redirects=True, timeout=720) # 发起requests下载请求
status_code = r.status_code
if (status_code == 200 or status_code == 206):
with open(save_path, "wb") as hf:
hf.write(r.content)
except:
print("Error, can not download %s.apk" % apk_name)
else:
print("%s downloaded already!" % save_path)
# 批量下载的线程
class DownLoadThread(threading.Thread):
def __init__(self, q_job):
self._q_job = q_job
threading.Thread.__init__(self)
def run(self):
while True:
if self._q_job.qsize() > 0:
download_single_apk(self._q_job.get()) # 这是10个线程都运行这个下载函数
else:
break
if __name__ == '__main__':
# 初始化一个队列
q = queue.Queue(0)
# 逐行读取excel里的url
excel = openpyxl.load_workbook('Top_1000_app.xlsx') # 读取excel里边的内容
table = excel.active
rows = table.max_row
for r in range(2, rows + 1): # 跟excel的第一行标题行无关,从第二行文字内容开始做替换工作
apk_name = table.cell(row=r, column=2).value # 获取app名字(中文)
apk_url = table.cell(row=r, column=3).value # 获取下载地址
temp_str = apk_name + ";" + apk_url # 不可以put列表进队列,只能尝试put字符串
q.put(temp_str)
for i in range(10): # 开启10个线程
DownLoadThread(q).start()
本案例素材下载
点我下载
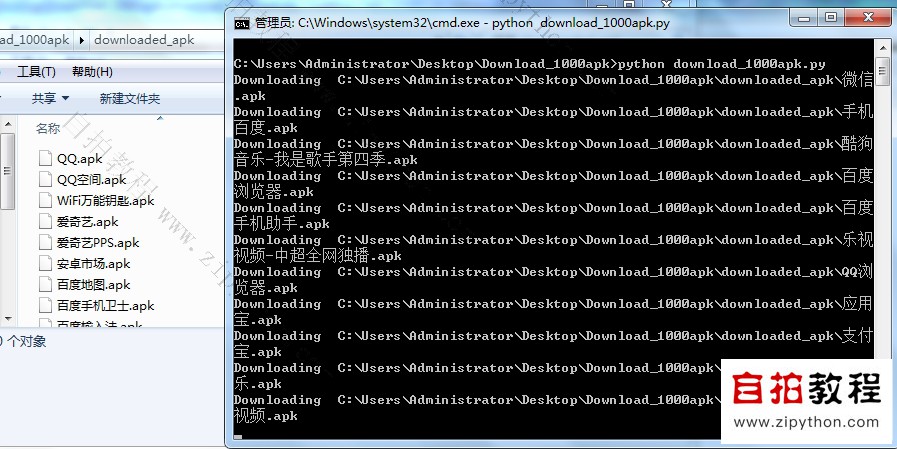
运行方式与效果
比如保存以上代码为download_1000apk.py并放在桌面,
建议python download_1000apk.py运行,当然也可以双击运行。
运行效果如下:
以上就是用python批量下载apk的详细内容,更多关于python批量下载apk的资料请关注易盾网络其它相关文章!