基本思路: 首先用开发者工具找到需要提取数据的标签列 利用xpath定位需要提取数据的列表 然后再逐个提取相应的数据: 保存数据到csv: 利用开发者工具找到下一页按钮所在标签: 利用
基本思路:
首先用开发者工具找到需要提取数据的标签列
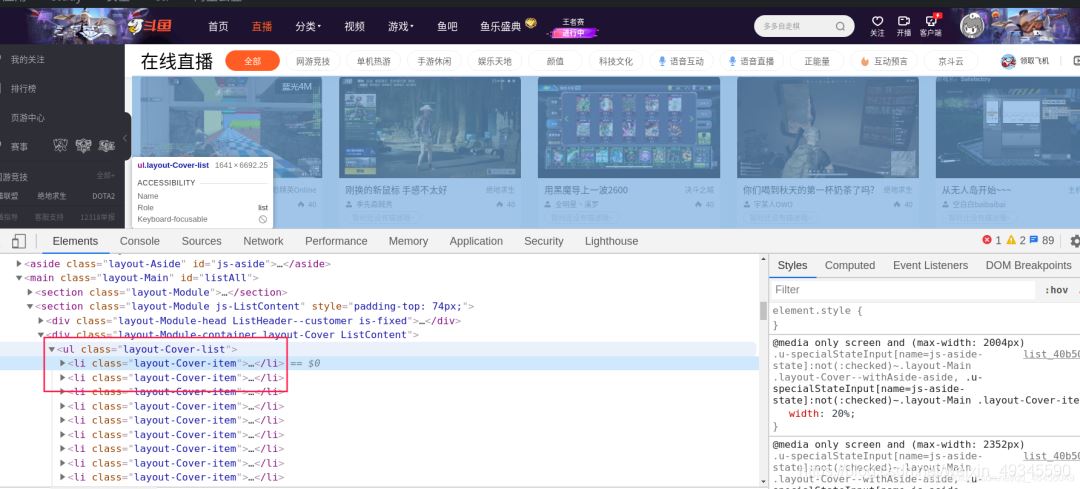
利用xpath定位需要提取数据的列表
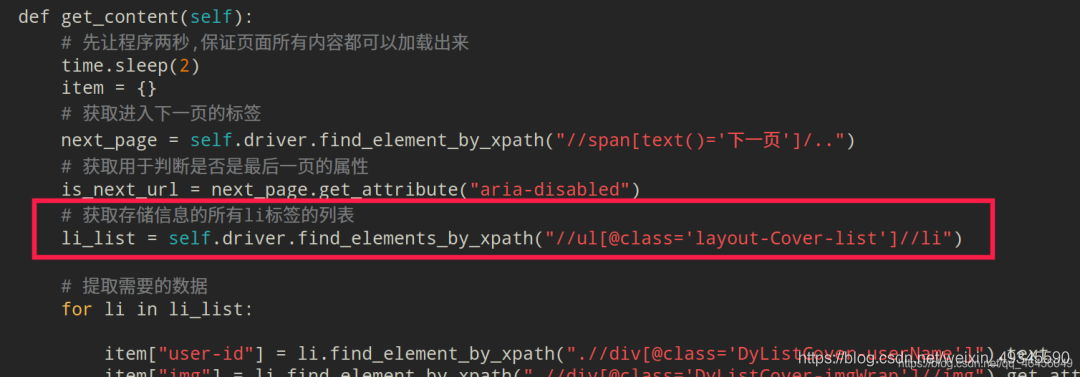
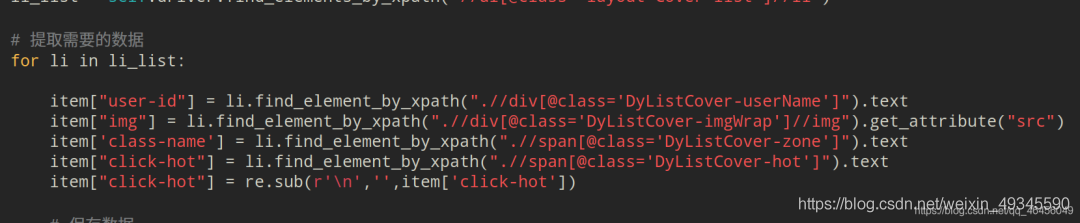
然后再逐个提取相应的数据:
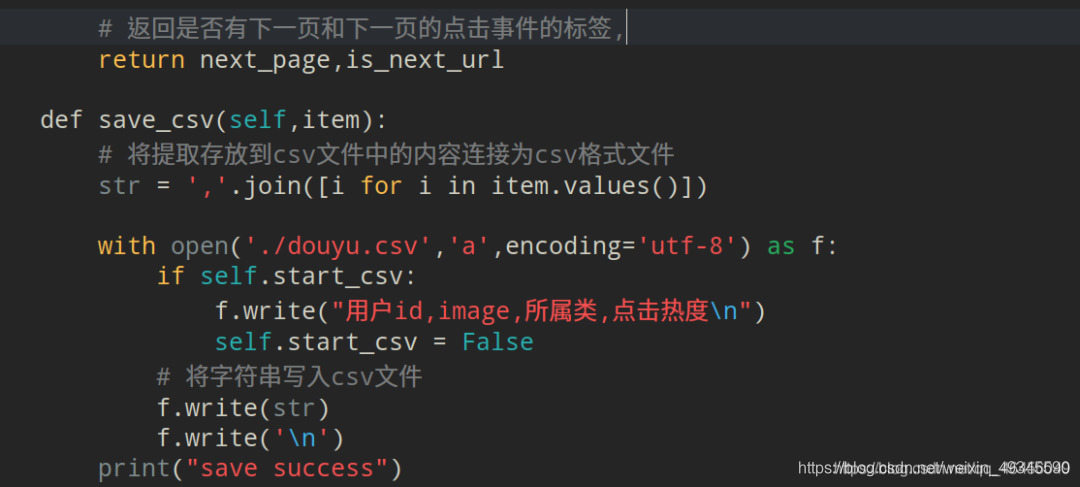
保存数据到csv:
利用开发者工具找到下一页按钮所在标签:
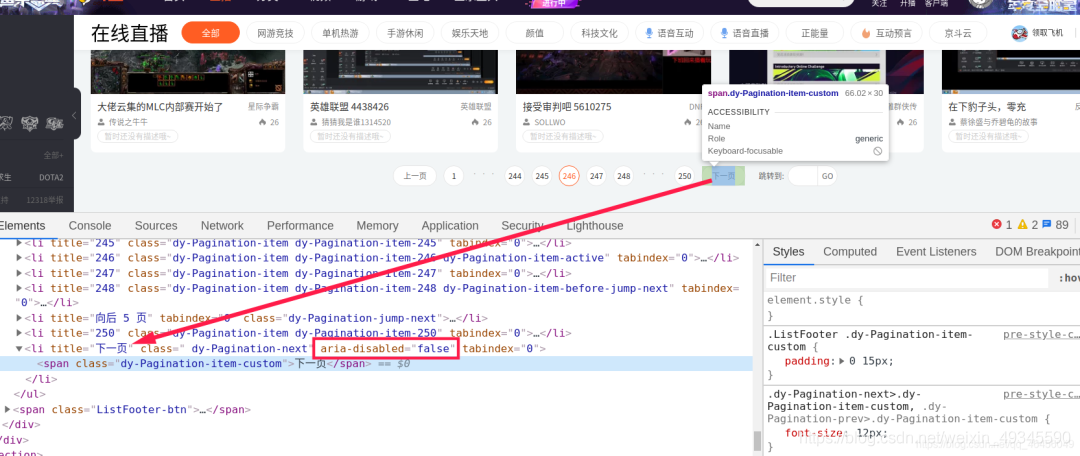
利用xpath提取此标签对象并返回:
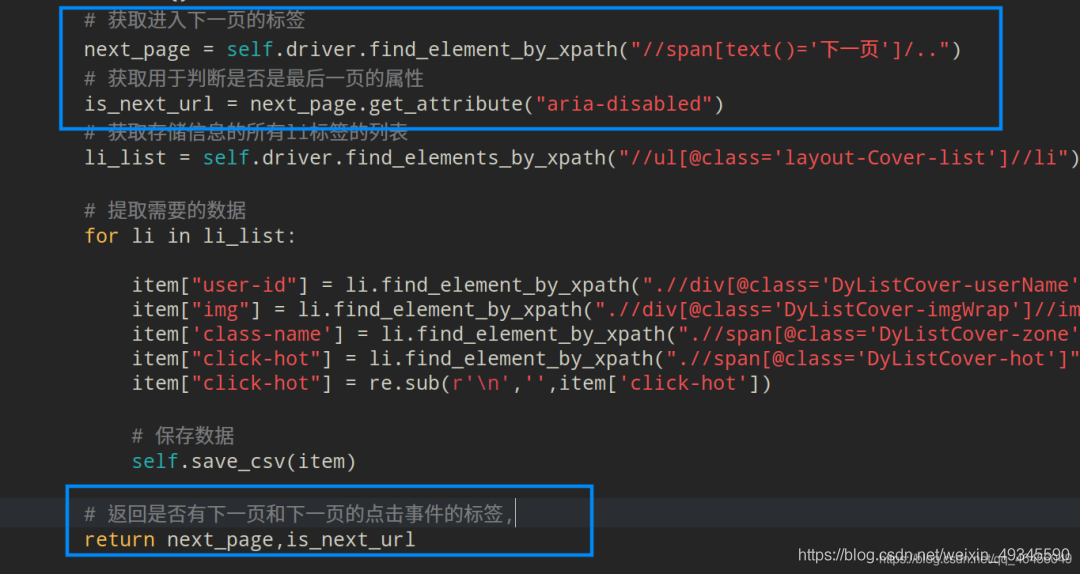
调用点击事件,并循环上述过程:
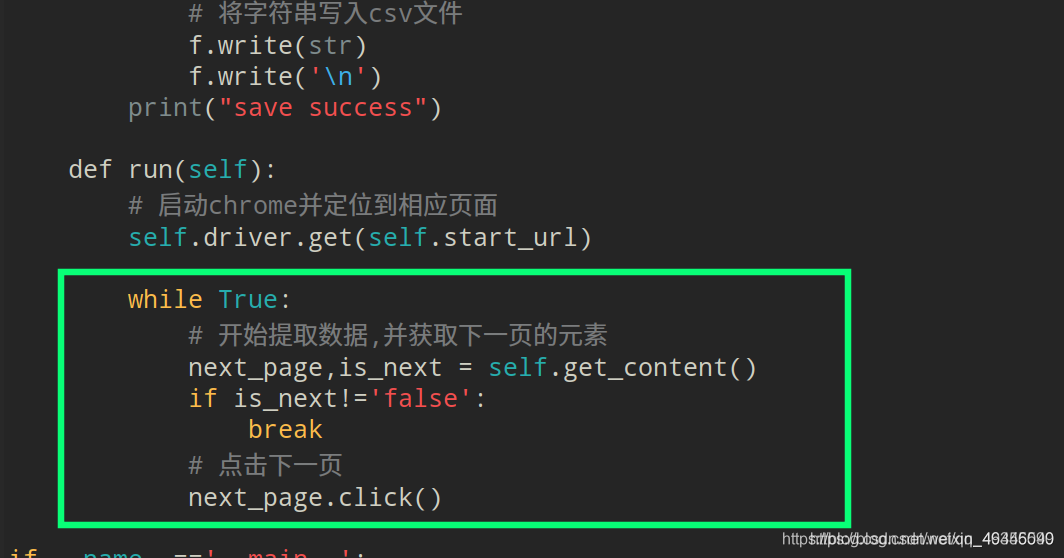
最终效果图:

代码:
from selenium import webdriver
import time
import re
class Douyu(object):
def __init__(self):
# 开始时的url
self.start_url = "https://www.douyu.com/directory/all"
# 实例化一个Chrome对象
self.driver = webdriver.Chrome()
# 用来写csv文件的标题
self.start_csv = True
def __del__(self):
self.driver.quit()
def get_content(self):
# 先让程序两秒,保证页面所有内容都可以加载出来
time.sleep(2)
item = {}
# 获取进入下一页的标签
next_page = self.driver.find_element_by_xpath("//span[text()='下一页']/..")
# 获取用于判断是否是最后一页的属性
is_next_url = next_page.get_attribute("aria-disabled")
# 获取存储信息的所有li标签的列表
li_list = self.driver.find_elements_by_xpath("//ul[@class='layout-Cover-list']//li")
# 提取需要的数据
for li in li_list:
item["user-id"] = li.find_element_by_xpath(".//div[@class='DyListCover-userName']").text
item["img"] = li.find_element_by_xpath(".//div[@class='DyListCover-imgWrap']//img").get_attribute("src")
item['class-name'] = li.find_element_by_xpath(".//span[@class='DyListCover-zone']").text
item["click-hot"] = li.find_element_by_xpath(".//span[@class='DyListCover-hot']").text
item["click-hot"] = re.sub(r'\n','',item['click-hot'])
# 保存数据
self.save_csv(item)
# 返回是否有下一页和下一页的点击事件的标签,
return next_page,is_next_url
def save_csv(self,item):
# 将提取存放到csv文件中的内容连接为csv格式文件
str = ','.join([i for i in item.values()])
with open('./douyu.csv','a',encoding='utf-8') as f:
if self.start_csv:
f.write("用户id,image,所属类,点击热度\n")
self.start_csv = False
# 将字符串写入csv文件
f.write(str)
f.write('\n')
print("save success")
def run(self):
# 启动chrome并定位到相应页面
self.driver.get(self.start_url)
while True:
# 开始提取数据,并获取下一页的元素
next_page,is_next = self.get_content()
if is_next!='false':
break
# 点击下一页
next_page.click()
if __name__=='__main__':
douyu_spider = Douyu()
douyu_spider.run()
到此这篇关于python爬虫利用selenium实现自动翻页爬取某鱼数据的思路详解的文章就介绍到这了,更多相关python爬虫实现自动翻页爬取某鱼数据内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!