1.爬虫是什么
所谓爬虫,就是按照一定的规则,自动的从网络中抓取信息的程序或者脚本。万维网就像一个巨大的蜘蛛网,我们的爬虫就是上面的一个蜘蛛,不断的去抓取我们需要的信息。
2.爬虫三要素
- 抓取
- 分析
- 存储
3.爬虫的过程分析
当人类去访问一个网页时,是如何进行的?
①打开浏览器,输入要访问的网址,发起请求。
②等待服务器返回数据,通过浏览器加载网页。
③从网页中找到自己需要的数据(文本、图片、文件等等)。
④保存自己需要的数据。
对于爬虫,也是类似的。它模仿人类请求网页的过程,但是又稍有不同。
首先,对应于上面的①和②步骤,我们要利用python实现请求一个网页的功能。
其次,对应于上面的③步骤,我们要利用python实现解析请求到的网页的功能。
最后,对于上面的④步骤,我们要利用python实现保存数据的功能。
因为是讲一个简单的爬虫嘛,所以一些其他的复杂操作这里就不说了。下面,针对上面几个功能,逐一进行分析。
4.如何用python请求一个网页
作为一门拥有丰富类库的编程语言,利用python请求网页完全不在话下。这里推荐一个非常好用的类库urllib.request。
4.1.抓取网页
urllib库使用
import urllib.request
response = urllib.request.urlopen('https://laoniu.blog.csdn.net/')
print(response.read().decode('utf-8'))
这样就可以抓取csdn我的主页的html文档
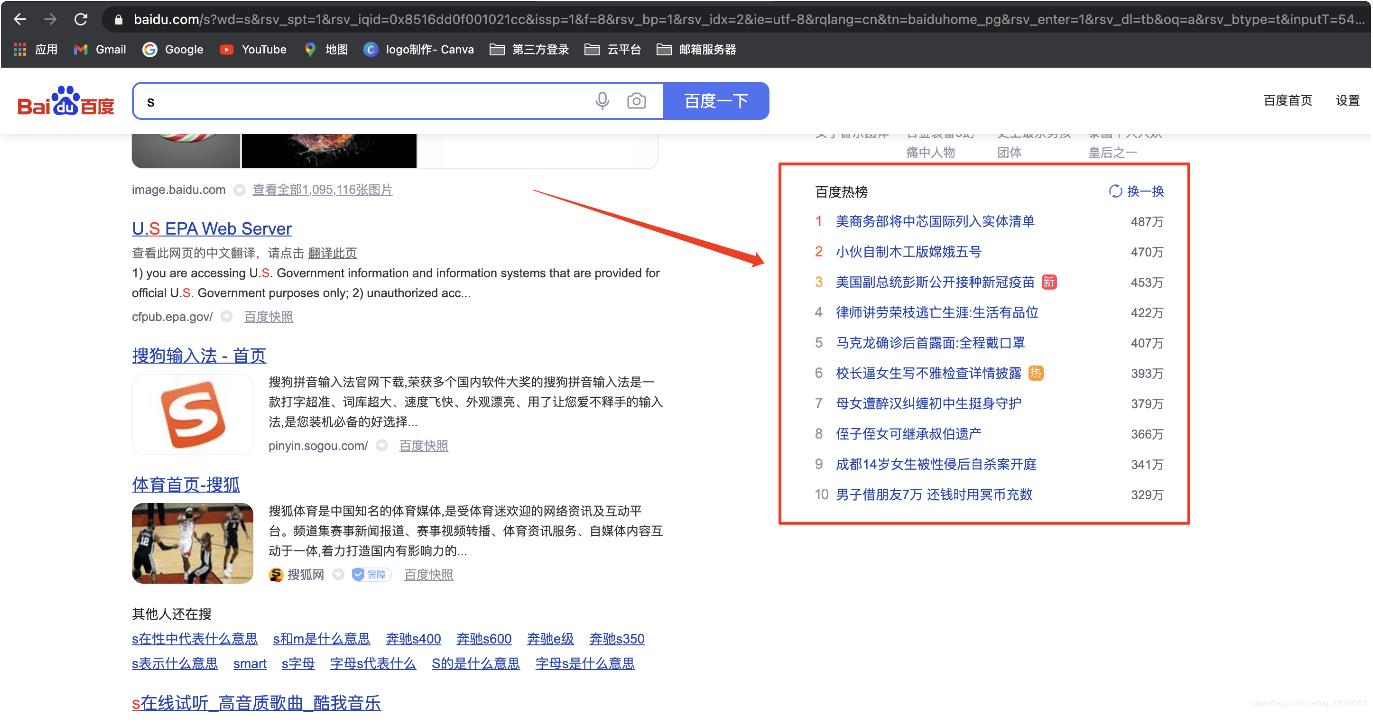
我们使用爬虫就是需要在网页中提取我们需要的数据,接下来我们来学习抓取一下百度搜索页的热榜数据
4.2.如何解析网页呢
使用lxml库
lxml 是一种使用 Python 编写的库,可以迅速、灵活地处理 XML 和 HTML。
它支持 XML Path Language (XPath) 和 Extensible Stylesheet Language Transformation (XSLT),并且实现了常见的 ElementTree API。
安装
windows下安装
#pip方式安装 pip3 install lxml #wheel方式安装 #下载对应系统版本的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml pip3 install lxml-4.2.1-cp36-cp36m-win_amd64.whl
linux下安装
yum install -y epel-release libxslt-devel libxml2-devel openssl-devel pip3 install lxml
环境/版本一览:
- 开发工具:PyCharm 2020.2.3
- python:3.8.5
4.3.编写代码
import urllib.request
from lxml import etree
# 获取百度热榜
url = "https://www.baidu.com/s?ie=UTF-8&wd=1"
# 我们在请求头加入User-Agent参数,这样可以让服务端认为此次请求是用户通过浏览器发起的正常请求,防止被识别为爬虫程序请求导致直接拒绝访问
req = urllib.request.Request(url=url, headers={
'User-Agent': 'User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
})
# 发起请求
html_resp = urllib.request.urlopen(req).read().decode("utf-8")
到这里我们可以顺利获取百度的搜索页面html文档
我门需要看一下热搜排行榜的标签元素在哪里
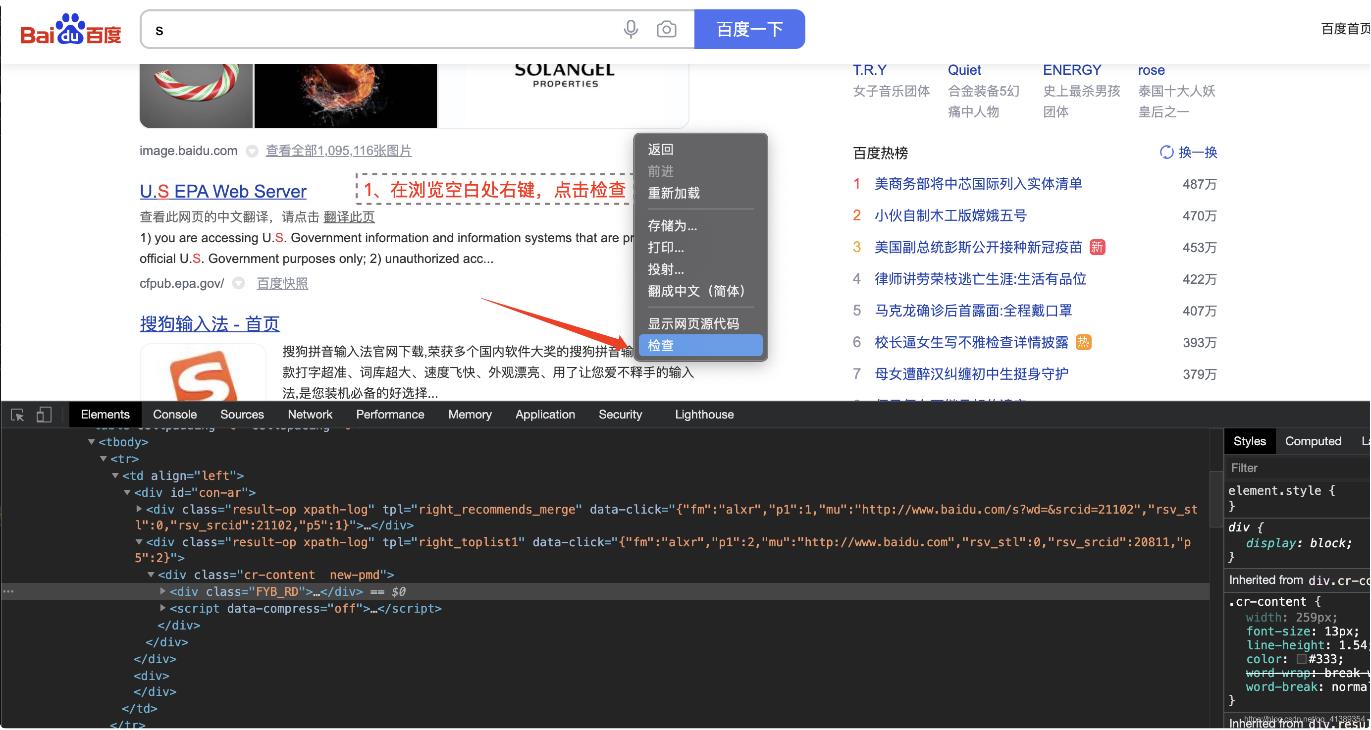
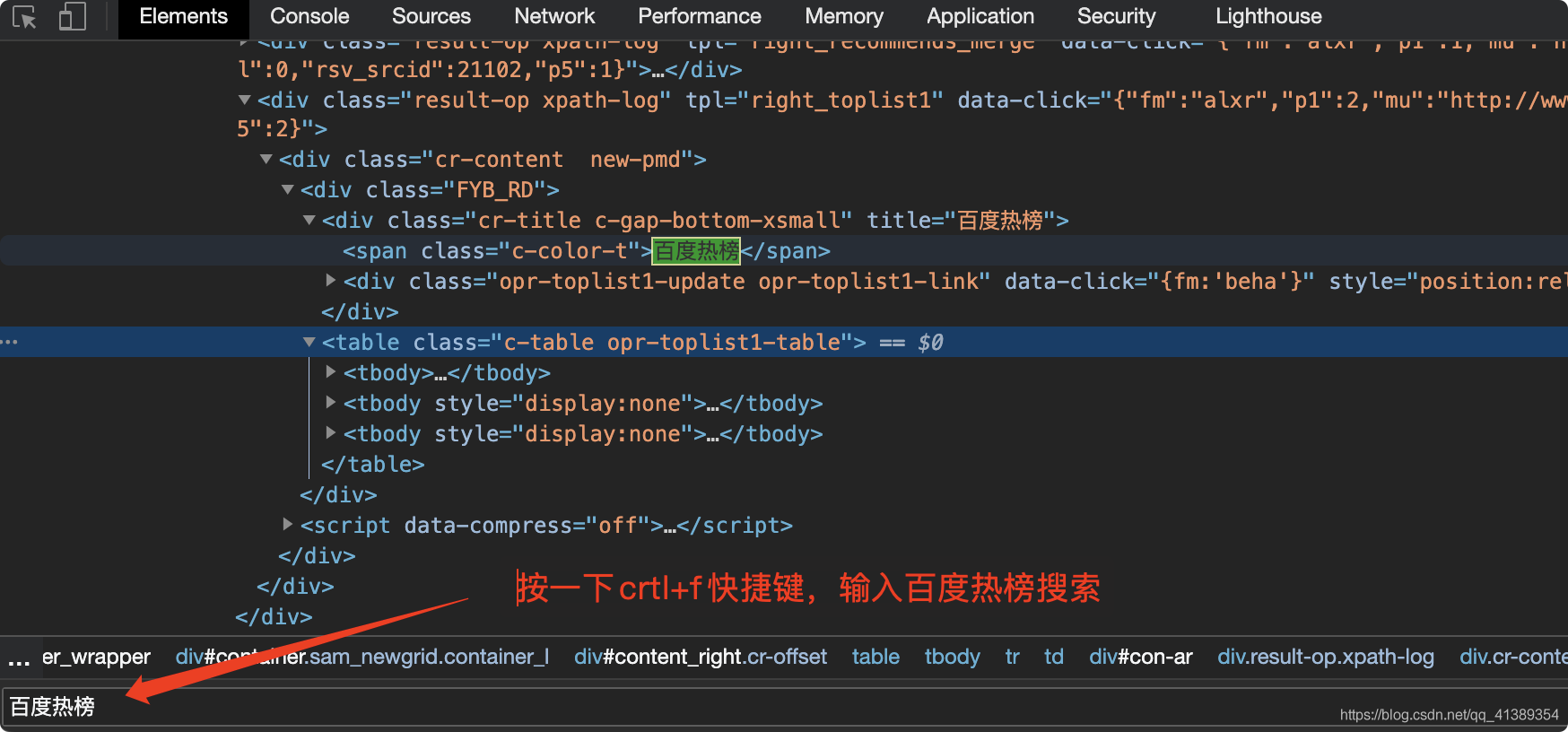
找到第一条 右键复制 XPath (后边说XPath是什么)
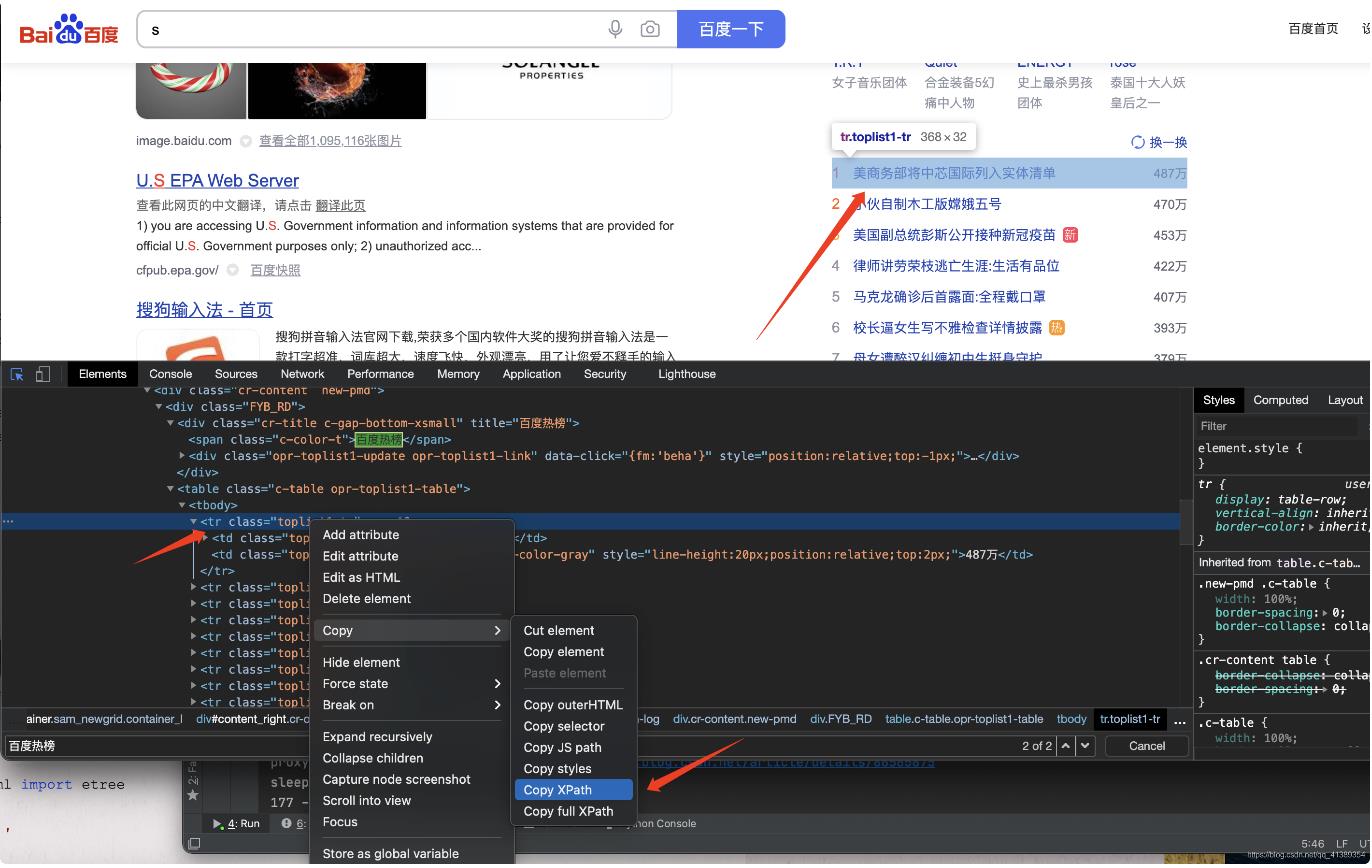
我们需要了解并使用XPath,XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。
复制的内容结果是: //*[@id="con-ar"]/div[2]/div/div/table/tbody[1]/tr[1]
这xPath字符串 表示现在在html定位的位置就是热点新闻第一行内容
5.XPath常用规则
6.继续分析
那么我们要获取所有的热点新闻该怎么写呢
继续看网页
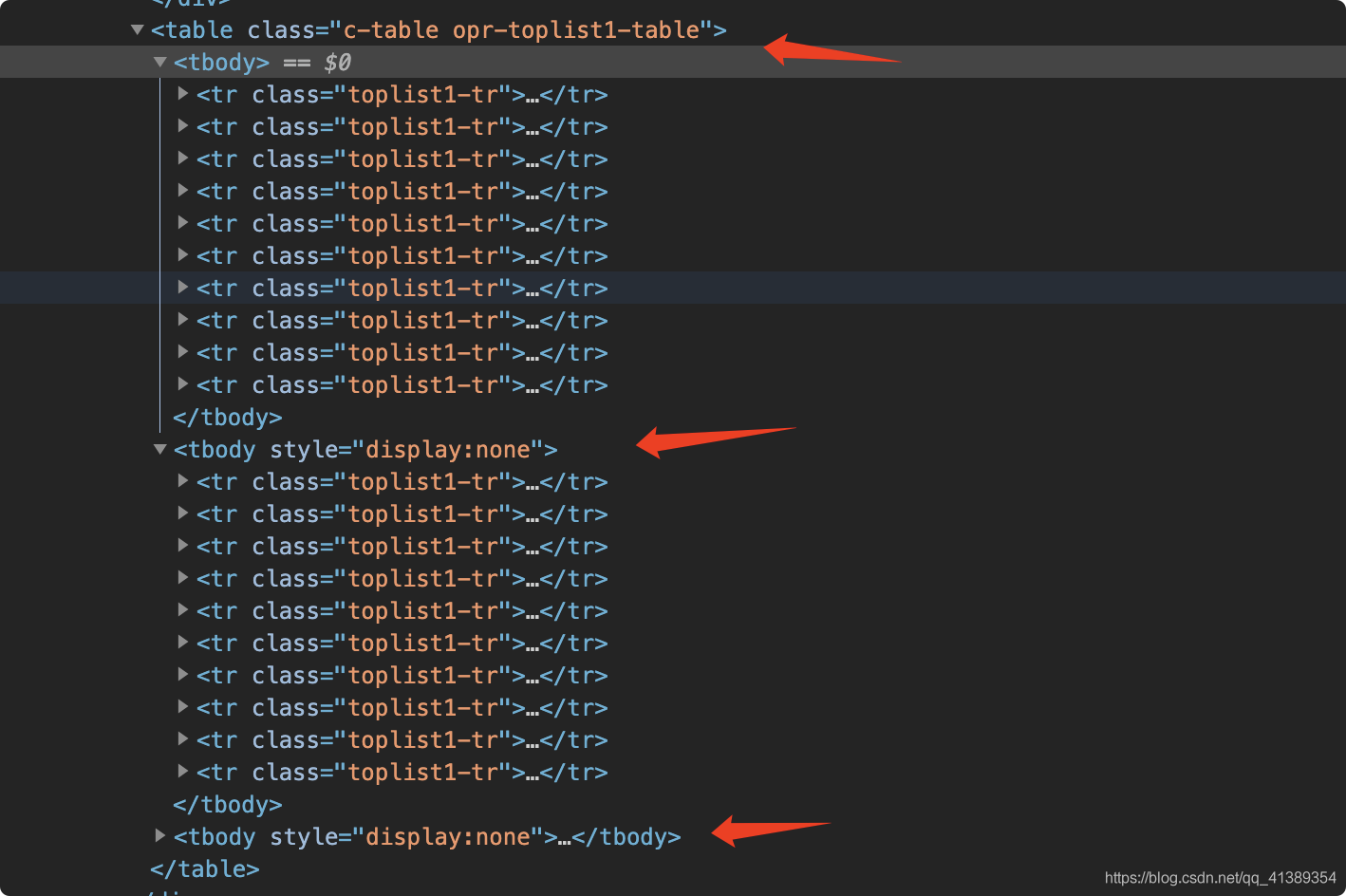
可以看到所有的热榜分别在三个<tbody>之下
修改一下刚才复制的XPath
//*[@id="con-ar"]/div[2]/div/div/table/tbody[1]/tr[1] 改为 //*[@id="con-ar"]/div[2]/div/div/table/tbody/tr
这样XPath就会定位到这三个tbody下的所有tr元素内容
我们继续看一下tr是不是我们想要的内容,展开一个tr看看
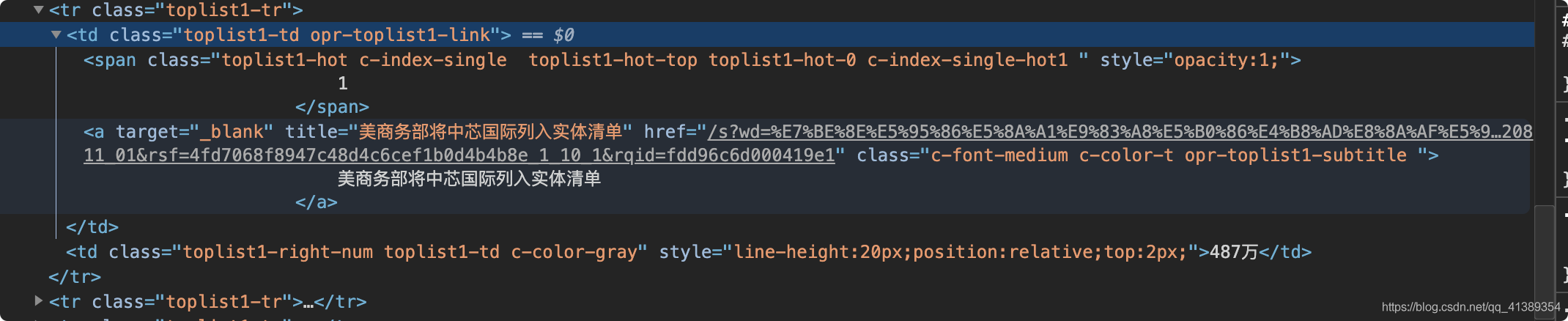
淦~还有一堆,,
这该怎么办。我们需要拿到数据是 【标题】 【访问链接】 【热度】,现在手里已经拿到的是所有的tr元素
紧接着从tr下手 直接 拿到下面所有<a>标签的标题与超链接
标题的XPath: */a/@title 超链接的XPath: */a/@href
*表示匹配tr下的所有元素 /a是在*找到第一个a标签 @是属性选择器 title和href就是要选择的素属性了
还剩下个热度,let‘s me 继续操作,直接选择tr下的第二个td XPath: td[2]
分析完毕,把完整的代码贴出来
import urllib.request
from lxml import etree
# 获取百度热榜
url = "https://www.baidu.com/s?ie=UTF-8&wd=1"
# 我们在请求头加入User-Agent参数,这样可以让服务端认为此次请求是用户通过浏览器发起的正常请求,防止被识别为爬虫程序请求导致直接拒绝访问
req = urllib.request.Request(url=url, headers={
'User-Agent': 'User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
})
html_resp = urllib.request.urlopen(req).read().decode("utf-8")
html = etree.HTML(html_resp)#初始化生成一个XPath解析对象
_list = html.xpath("//*[@id='con-ar']/div[2]/div/div/table/tbody/tr")
print(f"article count : {len(_list)}")
for tr in _list:
title = tr.xpath("*/a/@title")[0]
href = tr.xpath("*/a/@href")[0]
hot = tr.xpath("string(td[2])").strip()
print(f"{hot}\t{title}\thttps://www.baidu.com{href}")
点击运行,程序啪就跑起来了,很快啊,数据全都过来了,我全都接住了,我笑了一下。
到此就完成了lxml xpath的基本使用,更详细的xpath教程请看 :https://www.w3school.com.cn/xpath/index.asp
爬虫三要素,抓取数据完成了,剩余的分析与存储就先不说了
总结
到此这篇关于Python爬虫新手入门之初学lxml库的文章就介绍到这了,更多相关Python爬虫入门之lxml库内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!