前言 最近在用python练习写点爬虫,想着把双色球的历史记录爬下来存入mysql中,爬取数据没有遇到什么问题,在处理数据存入数据库的时候遇到问题了,现把问题整理出来方便自己日后
前言
最近在用python练习写点爬虫,想着把双色球的历史记录爬下来存入mysql中,爬取数据没有遇到什么问题,在处理数据存入数据库的时候遇到问题了,现把问题整理出来方便自己日后查询也能帮助有缘人士:
一、从双色球历史网站爬取数据存成html文件;
import urllib.request
url = 'https://datachart.500.com/ssq/history/newinc/history.php?start=1&end=20109'
request = urllib.request.Request(url)
request.add_header('user-agent',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36')
response = urllib.request.urlopen(request)
buf = response.read()
data = buf.decode('utf-8')
# 爬取数据保存到文件
fileOb = open('history.html', 'w', encoding='utf-8') # 打开一个文件,没有就新建一个
fileOb.write(data)
fileOb.close()
二,读取html文件获取数据,其中还有mysql的连接池
from lxml import etree
from collections import namedtuple
import mysql2
fileOb = open('history.html', 'r', encoding='utf-8') # 打开一个文件
doc = fileOb.read()
html = etree.HTML(doc) # 把字符串转化为可处理的格式
two_colour = namedtuple('two_colour', 'code,red_1,red_2,red_3,red_4,red_5,red_6,blue,create_date')
# two_colour = namedtuple('two_colour', 'a1,a2,a3,a4,a5,a6,a7,a8,a9,a10,a11,a12,a13,a14,a15,a16')
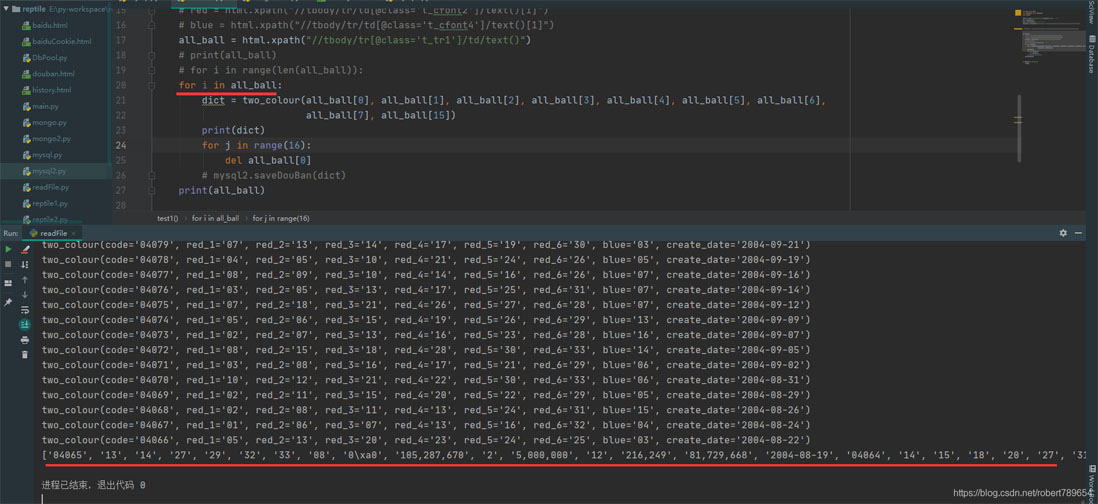
def test1():
# red = html.xpath("//tbody/tr/td[@class='t_cfont2']/text()[1]")
# blue = html.xpath("//tbody/tr/td[@class='t_cfont4']/text()[1]")
all_ball = html.xpath("//tbody/tr[@class='t_tr1']/td/text()")
# print(all_ball)
for i in range(len(all_ball)):
dict = two_colour(all_ball[0], all_ball[1], all_ball[2], all_ball[3], all_ball[4], all_ball[5], all_ball[6],
all_ball[7], all_ball[15])
print(dict)
for j in range(16):
del all_ball[0]
mysql2.saveDouBan(dict)
print(all_ball)
if __name__ == '__main__':
test1()
mysql的连接池
import pymysql
# 新的写法,要注意
from dbutils.pooled_db import PooledDB
POOL = PooledDB(
creator=pymysql, # 使用链接数据库的模块
maxconnections=6, # 连接池允许的最大连接数,0和None表示不限制连接数
mincached=2, # 初始化时,链接池中至少创建的空闲的链接,0表示不创建
maxcached=5, # 链接池中最多闲置的链接,0和None不限制
maxshared=3,
# 链接池中最多共享的链接数量,0和None表示全部共享。PS: 无用,因为pymysql和MySQLdb等模块的 threadsafety都为1,所有值无论设置为多少,_maxcached永远为0,所以永远是所有链接都共享。
blocking=True, # 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错
maxusage=None, # 一个链接最多被重复使用的次数,None表示无限制
setsession=[], # 开始会话前执行的命令列表。
ping=0,
# ping MySQL服务端,检查是否服务可用。
host='127.0.0.0',
port=3306,
user='root',
password='123456',
database='python_test',
charset='utf8'
)
def func():
# 检测当前正在运行连接数的是否小于最大链接数,如果不小于则:等待或报raise TooManyConnections异常
# 否则 则优先去初始化时创建的链接中获取链接 SteadyDBConnection。
# 然后将SteadyDBConnection对象封装到PooledDedicatedDBConnection中并返回。
# 如果最开始创建的链接没有链接,则去创建一个SteadyDBConnection对象,再封装到PooledDedicatedDBConnection中并返回。
# 一旦关闭链接后,连接就返回到连接池让后续线程继续使用。
conn = POOL.connection()
# print(th, '链接被拿走了', conn1._con)
# print(th, '池子里目前有', pool._idle_cache, '\r\n')
cursor = conn.cursor()
cursor.execute('select * from two_clour_two')
result = cursor.fetchall()
for i in result:
print(i)
conn.close()
# 数据库插入操作
def saveDouBan(dict):
conn = POOL.connection()
cursor = conn.cursor()
sql = "insert into two_clour_two (`code`, `red_1`, `red_2`, `red_3`, `red_4`, `red_5`, `red_6`, `blue`,`create_date`) values(\"%s\",\"%s\",\"%s\",\"%s\",\"%s\",\"%s\",\"%s\",\"%s\",\"%s\")" % (
str(dict[0]), str(dict[1]), str(dict[2]), str(dict[3]), str(dict[4]), str(dict[5]), str(dict[6]),
str(dict[7]), str(dict[8]))
cursor.execute(sql)
print('Successful')
conn.commit() # 写入数据库一定要commit,否则数据没有数据
cursor.close()
if __name__ == '__main__':
func()
三,数据处理的误区,这个是刚开始的写法,i是下标,取完数据把对应的下标的元素删除了,可以这时候的问题就是,下标的数字比数组长了,所有最后下标取完了,可是数组却没有为空。
解决办法就是上面贴的
for i in range(len(all_ball)):
总结
到此这篇关于python3中for循环踩坑记录的文章就介绍到这了,更多相关python3 for循环踩坑内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!