1. 常用的编码
- ASCII:只能表示一些字母,数字和特殊的字符,占一个字节
- GBK:国家简体中文字符集和繁体字符集,兼容ASCII,占两个字节
- Unicode:能够表示全世界上所有的字符,Unicode有人说占4个字节也有人说占2个字节,但中文占2个字节
- UTF-8:Unicode的压缩版,占1~3个字节,其中中文占三个字节
2.补充:计算机表示的单位:
bit: 位,计算机最小的表示单位
bytes:字节,最小的存储单位,1bytes=8bit,1bytes简写成1B
1KB = 1024B
1MB = 1024KB
1GB = 1024MB
1TB = 1024GB
......
3.ASCII编码
ASCII编码是基于拉丁字母一套编码,主要是显示现代英语和其西欧语言,是最早通用的单字节编码系统,具体ASCII对照表如下:
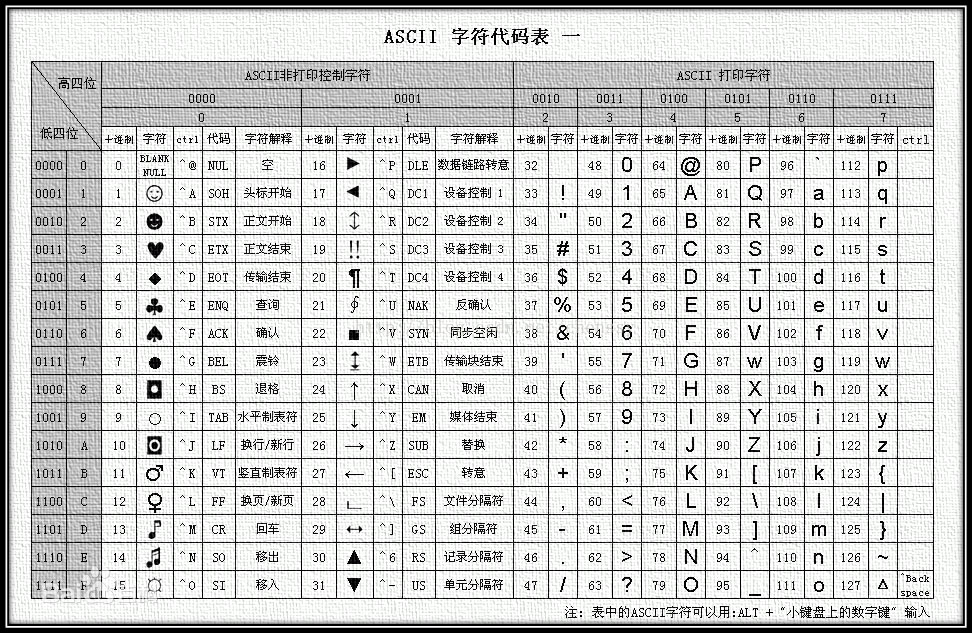
在对照表中需要记住的是大写字母A的编码是65,小写字母a的编码的97即可。
在python中可以使用chr和ord方法进行转换:
# 将数字类型转换成ASCII对应的字符
print(chr(97)) # a
# 将数字转换成对应的数据
print(ord("A")) # 65
# 或者使用
但随着事件的发展,ASCII编码扩展到了256个字符,编码 对照表如下:
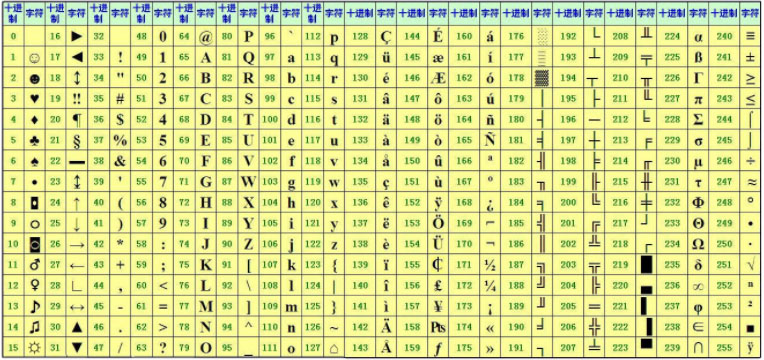
其中后128个字符称为扩展ASCII码
2.GBK和GB2312编码
由于ASCII编码只能由256个字符组成,然只能由1个字节来表示中文是不可能的,因此制定了GB2312编码,用来表示中文的对照表
4.Unicode
为了解决各个国家编码冲突的问题,Unicode编码就因此而生,Unicode把所有语言都统一到一套编码里面,就会避免冲突,产生乱码。
Unicodeb标准在不断发展,最常用的是用两个字节表示一个字符,也有的字符是4个字节,但是中文是占两个字节。如果统一成Unicode编码,在存储和传输上就不划算
5.UTF-8编码
为了解决Unicode编码存储过大的问题,就推出了可变长编码UTF-8,UTF-8编码把一个Unicode字符依据不同的数据大小编程1~6个字节,其中中文就占3个字节
6.编码和解码
1.编码操作
可以通过encode进行编码,其中语法如下:
对字符串进行ASCII编码(只能转换数字,英文字母和一些符号)
# 方式1: 通过bytes方法
bytes('a', 'ASCII')
# 方式2: 通过encode方法进行
'a'.encode('ASCII')
将字符串转换成gbk编码格式
# 方式1: 通过encode方法进行
print('你好'.encode('GBK')) # 编码之后的结果为:b'\xc4\xe3\xba\xc3'
# 方式2: 通过bytes类型
print(bytes('我爱你', 'GBK')) # 编码之后的结果为:b'\xce\xd2\xb0\xae\xc4\xe3'
将字符串转换成Unicode编码格式
# 方式1: 通过encode方法进行
print('你好'.encode('unicode_escape')) # 编码之后的结果为:b'\\u4f60\\u597d'
# 方式2: 通过bytes类型
print(bytes('我爱你', 'unicode_escape')) # 编码之后的结果为:b'\\u6211\\u7231\\u4f60'
将字符串转换成UTF-8编码格式
# 方式1: 通过encode方法进行
print('你好'.encode('utf-8')) # 编码之后的结果为:b'\xe4\xbd\xa0\xe5\xa5\xbd'
# 方式2: 通过bytes类型
print(bytes('我爱你', 'utf-8')) # 编码之后的结果为:b'\xe6\x88\x91\xe7\x88\xb1\xe4\xbd\xa0'
2.解码操作
将GBK编码格式转换成字符串
# 通过decode方法解码
print(b'\xc4\xe3\xba\xc3\xce\xd2\xb0\xae\xc4\xe3'.decode('GBK')) # 解码之后结果为:你好我爱你
将UTF-8编码格式转换成字符串
# 通过decode方法解码
print(b'\xe4\xbd\xa0\xe5\xa5\xbd\xe6\x88\x91\xe7\x88\xb1\xe4\xbd\xa0'.decode('utf-8')) # 解码之后结果为:你好我爱你
将Uniconde编码格式转换成字符串
# 通过decode方法解码
print(b'\\u4f60\\u597d\\u6211\\u7231\\u4f60'.decode('GBK')) # 解码之后结果为:你好我爱你
到此这篇关于python中字符串的编码与解码的文章就介绍到这了,更多相关python字符串的编码与解码内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!