前言
使用scrapy进行大型爬取任务的时候(爬取耗时以天为单位),无论主机网速多好,爬完之后总会发现scrapy日志中“item_scraped_count”不等于预先的种子数量,总有一部分种子爬取失败,失败的类型可能有如下图两种(下图为scrapy爬取结束完成时的日志):
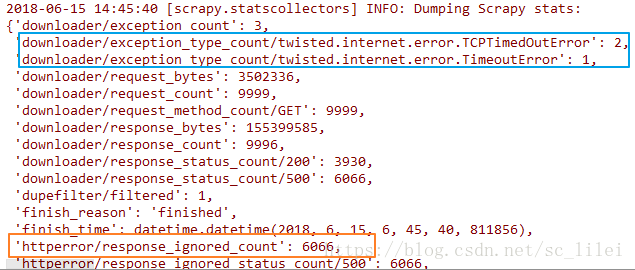
scrapy中常见的异常包括但不限于:download error(蓝色区域), http code 403/500(橙色区域)。
不管是哪种异常,我们都可以参考scrapy自带的retry中间件写法来编写自己的中间件。
正文
使用IDE,现在scrapy项目中任意一个文件敲上以下代码:
from scrapy.downloadermiddlewares.retry import RetryMiddleware
按住ctrl键,鼠标左键点击RetryMiddleware进入该中间件所在的项目文件的位置,也可以通过查看文件的形式找到该中间件的位置,路径是:site-packages/scrapy/downloadermiddlewares/retry.RetryMiddleware
该中间件的源代码如下:
class RetryMiddleware(object):
# IOError is raised by the HttpCompression middleware when trying to
# decompress an empty response
EXCEPTIONS_TO_RETRY = (defer.TimeoutError, TimeoutError, DNSLookupError,
ConnectionRefusedError, ConnectionDone, ConnectError,
ConnectionLost, TCPTimedOutError, ResponseFailed,
IOError, TunnelError)
def __init__(self, settings):
if not settings.getbool('RETRY_ENABLED'):
raise NotConfigured
self.max_retry_times = settings.getint('RETRY_TIMES')
self.retry_http_codes = set(int(x) for x in settings.getlist('RETRY_HTTP_CODES'))
self.priority_adjust = settings.getint('RETRY_PRIORITY_ADJUST')
@classmethod
def from_crawler(cls, crawler):
return cls(crawler.settings)
def process_response(self, request, response, spider):
if request.meta.get('dont_retry', False):
return response
if response.status in self.retry_http_codes:
reason = response_status_message(response.status)
return self._retry(request, reason, spider) or response
return response
def process_exception(self, request, exception, spider):
if isinstance(exception, self.EXCEPTIONS_TO_RETRY) \
and not request.meta.get('dont_retry', False):
return self._retry(request, exception, spider)
def _retry(self, request, reason, spider):
retries = request.meta.get('retry_times', 0) + 1
retry_times = self.max_retry_times
if 'max_retry_times' in request.meta:
retry_times = request.meta['max_retry_times']
stats = spider.crawler.stats
if retries <= retry_times:
logger.debug("Retrying %(request)s (failed %(retries)d times): %(reason)s",
{'request': request, 'retries': retries, 'reason': reason},
extra={'spider': spider})
retryreq = request.copy()
retryreq.meta['retry_times'] = retries
retryreq.dont_filter = True
retryreq.priority = request.priority + self.priority_adjust
if isinstance(reason, Exception):
reason = global_object_name(reason.__class__)
stats.inc_value('retry/count')
stats.inc_value('retry/reason_count/%s' % reason)
return retryreq
else:
stats.inc_value('retry/max_reached')
logger.debug("Gave up retrying %(request)s (failed %(retries)d times): %(reason)s",
{'request': request, 'retries': retries, 'reason': reason},
extra={'spider': spider})
查看源码我们可以发现,对于返回http code的response,该中间件会通过process_response方法来处理,处理办法比较简单,大概是判断response.status是否在定义好的self.retry_http_codes集合中,通过向前查找,这个集合是一个列表,定义在default_settings.py文件中,定义如下:
RETRY_HTTP_CODES = [500, 502, 503, 504, 522, 524, 408]
也就是先判断http code是否在这个集合中,如果在,就进入retry的逻辑,不在集合中就直接return response。这样就已经实现对返回http code但异常的response的处理了。
但是对另一种异常的处理方式就不一样了,刚才的异常准确的说是属于HTTP请求error(超时),而另一种异常发生的时候则是如下图这种实实在在的代码异常(不处理的话):
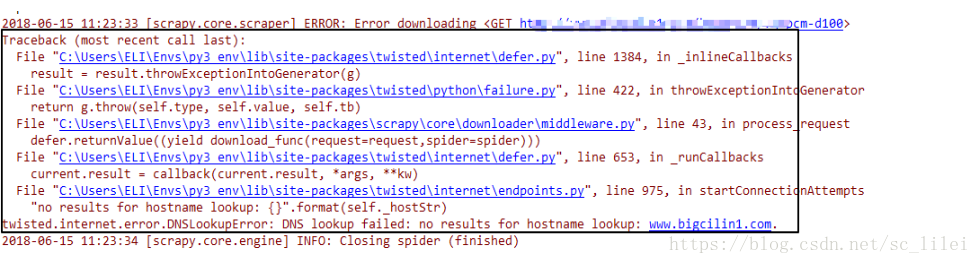
你可以创建一个scrapy项目,start_url中填入一个无效的url即可模拟出此类异常。比较方便的是,在RetryMiddleware中同样提供了对这类异常的处理办法:process_exception
通过查看源码,可以分析出大概的处理逻辑:同样先定义一个集合存放所有的异常类型,然后判断传入的异常是否存在于该集合中,如果在(不分析dont try)就进入retry逻辑,不在就忽略。
OK,现在已经了解了scrapy是如何捕捉异常了,大概的思路也应该有了,下面贴出一个实用的异常处理的中间件模板:
from twisted.internet import defer
from twisted.internet.error import TimeoutError, DNSLookupError, \
ConnectionRefusedError, ConnectionDone, ConnectError, \
ConnectionLost, TCPTimedOutError
from scrapy.http import HtmlResponse
from twisted.web.client import ResponseFailed
from scrapy.core.downloader.handlers.http11 import TunnelError
class ProcessAllExceptionMiddleware(object):
ALL_EXCEPTIONS = (defer.TimeoutError, TimeoutError, DNSLookupError,
ConnectionRefusedError, ConnectionDone, ConnectError,
ConnectionLost, TCPTimedOutError, ResponseFailed,
IOError, TunnelError)
def process_response(self,request,response,spider):
#捕获状态码为40x/50x的response
if str(response.status).startswith('4') or str(response.status).startswith('5'):
#随意封装,直接返回response,spider代码中根据url==''来处理response
response = HtmlResponse(url='')
return response
#其他状态码不处理
return response
def process_exception(self,request,exception,spider):
#捕获几乎所有的异常
if isinstance(exception, self.ALL_EXCEPTIONS):
#在日志中打印异常类型
print('Got exception: %s' % (exception))
#随意封装一个response,返回给spider
response = HtmlResponse(url='exception')
return response
#打印出未捕获到的异常
print('not contained exception: %s'%exception)
spider解析代码示例:
class TESTSpider(scrapy.Spider):
name = 'TEST'
allowed_domains = ['TTTTT.com']
start_urls = ['http://www.TTTTT.com/hypernym/?q=']
custom_settings = {
'DOWNLOADER_MIDDLEWARES': {
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
'TESTSpider.middlewares.ProcessAllExceptionMiddleware': 120,
},
'DOWNLOAD_DELAY': 1, # 延时最低为2s
'AUTOTHROTTLE_ENABLED': True, # 启动[自动限速]
'AUTOTHROTTLE_DEBUG': True, # 开启[自动限速]的debug
'AUTOTHROTTLE_MAX_DELAY': 10, # 设置最大下载延时
'DOWNLOAD_TIMEOUT': 15,
'CONCURRENT_REQUESTS_PER_DOMAIN': 4 # 限制对该网站的并发请求数
}
def parse(self, response):
if not response.url: #接收到url==''时
print('500')
yield TESTItem(key=response.meta['key'], _str=500, alias='')
elif 'exception' in response.url:
print('exception')
yield TESTItem(key=response.meta['key'], _str='EXCEPTION', alias='')
Note:该中间件的Order_code不能过大,如果过大就会越接近下载器,就会优先于RetryMiddleware处理response,但这个中间件是用来兜底的,即当一个response 500进入中间件链时,需要先经过retry中间件处理,不能先由我们写的中间件来处理,它不具有retry的功能,接收到500的response就直接放弃掉该request直接return了,这是不合理的。只有经过retry后仍然有异常的request才应当由我们写的中间件来处理,这时候你想怎么处理都可以,比如再次retry、return一个重新构造的response。
下面来验证一下效果如何(测试一个无效的URL),下图为未启用中间件的情况:

再启用中间件查看效果:

ok,达到预期效果:即使程序运行时抛出异常也能被捕获并处理。
到此这篇关于如何在scrapy中捕获并处理各种异常的文章就介绍到这了,更多相关scrapy 捕获处理异常内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!