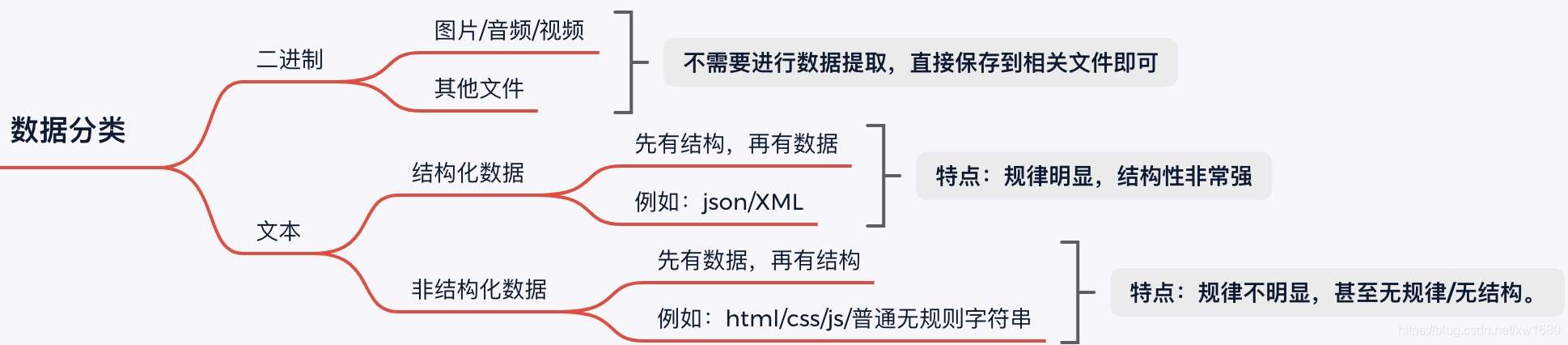
1. 数据抽取的概念

2. 数据的分类
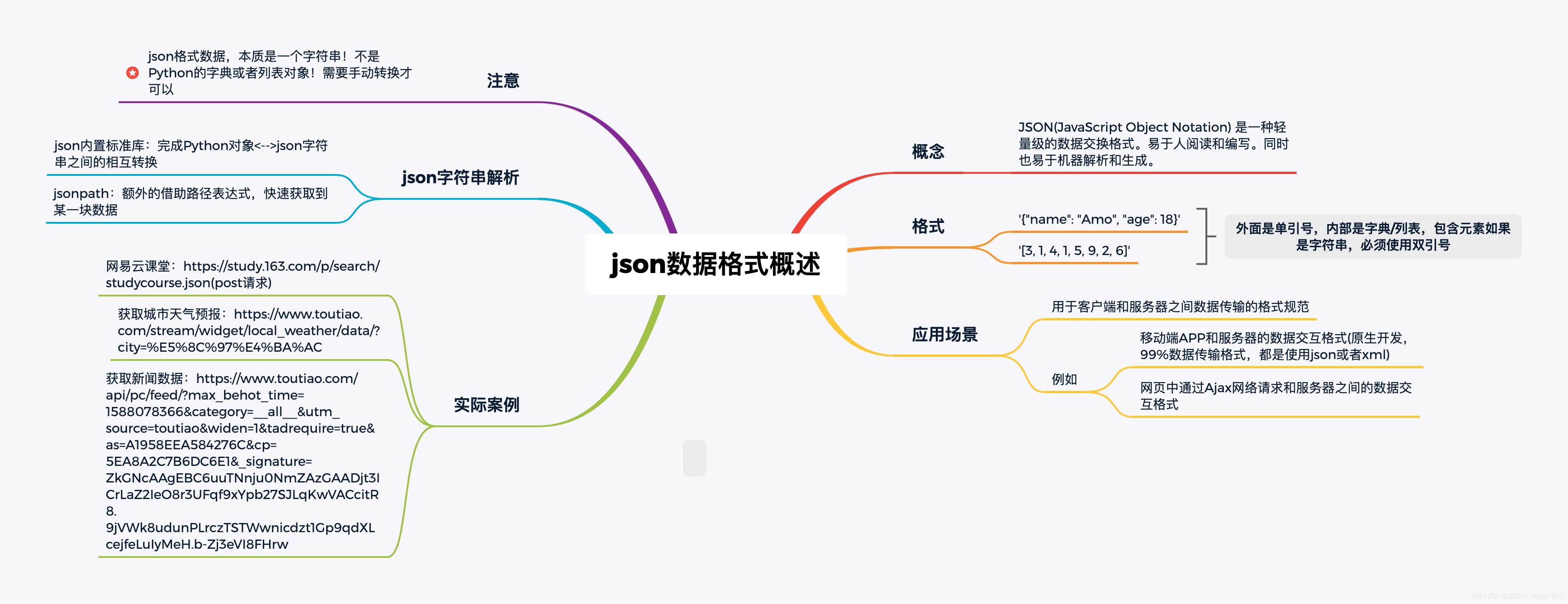
3. JSON数据概述及解析
3.1 JSON数据格式
3.2 解析库json
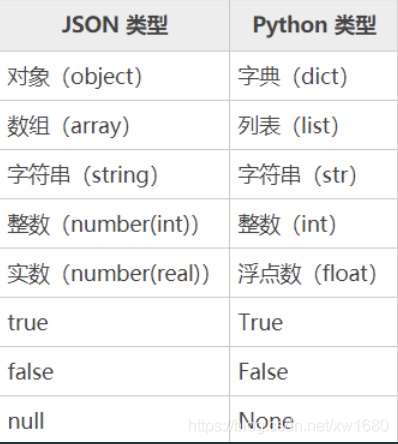
json模块是Python内置标准库,主要可以完成两个功能:序列化和反序列化。JSON对象和Python对象映射图如下:
3.2.1 json序列化
对象(字典/列表) 通过 json.dump()/json.dumps() ==> json字符串。示例代码如下:
import json
class Phone(object):
def __init__(self, name, price):
self.name = name
self.price = price
class Default(json.JSONEncoder):
def default(self, o):
print(o) # o: <__main__.Phone object at 0x10aa52c90>
return [o.name, o.price]
def parse(obj):
print(obj)
return {"name": obj.name, "price": obj.price}
person_info_dict = {
"name": "Amo",
"age": 18,
"is_boy": True,
# "n": float("nan"), # float("nan"):NaN float("inf")=>Infinity float("-inf")=>-Infinity
"phone": Phone("苹果8plus", 6458),
"hobby": ("sing", "dance"),
"dog": {
"name": "藏獒",
"age": 5,
"color": "棕色",
"isVIP": True,
"child": None
},
}
"""
obj:需要序列化的对象 字典/列表 这里指的是person_info_dict
indent: 缩进 单位: 字符
sort_keys: 是否按key排序 默认是False不排序
cls: json.JSONEncoder子类 处理不能序列化的对象
ensure_ascii: 是否确保ascii编码 默认是True确保 "苹果8plus"==>"\u82f9\u679c8plus" 所以改为False
default: 对象不能被序列化时,调用对应的函数解析
"""
# 将结果返回给一个变量
result = json.dumps(person_info_dict,
indent=2,
sort_keys=True,
ensure_ascii=False,
# cls=Default,
default=parse,
# allow_nan=False 是否处理特殊常量值
# 默认为True 但是JSON标准规范不支持NaN, Infinity和-Infinity
)
print(result)
with open("dump.json", "w", encoding="utf8") as file:
# json.dump是将序列化后的内容存储到文件中 其他参数用法和dumps一致
json.dump(person_info_dict, file, indent=4, ensure_ascii=False, default=parse)
3.2.2 json反序列化
json字符串通过json.load()/json.loads()==> 对象(字典/列表),示例代码如下:
import json
class Phone(object):
def __init__(self, name, price):
self.name = name
self.price = price
def pi(num):
return int(num) + 1
def oh(dic):
if "price" in dic.keys():
return Phone(dic["name"], dic["price"])
return dic
def oph(*args, **kwargs):
print(*args, **kwargs)
# 我自己本地有一个dump.json文件
with open("dump.json", "r", encoding="utf8") as file:
# content = file.read()
# parse_int/float: 整数/浮点数钩子函数
# object_hook: 对象解析钩子函数 将字典转为特定对象 传递给函数的是字典对象
# object_pairs_hook: 转化为特定对象 传递的是元组列表
# parse_constant: 常量钩子函数 NaN/Infinity/-Infinity
# result = json.loads(content, object_hook=oh, parse_int=pi, object_pairs_hook=oph)
result = json.load(file, parse_int=pi, object_hook=oh) # 直接将文件对象传入
print(type(result)) # <class 'dict'>
print(result)
4. jsonpath
jsonpath三方库,点击这里这里进入官网,通过路径表达式,来快速获取字典当中的指定数据,灵感来自xpath表达式。命令安装:
pip install --user -i http://pypi.douban.com/simple --trusted-host pypi.douban.com jsonpath
或者:
4.1 使用
语法格式如下:
from jsonpath import jsonpath
dic = {....} # 要找数据的字典
jsonpath(dic, 表达式)
常用的表达式语法如下:
JSONPath
描述
4.2 使用示例
案例一用到的字典如下:
dic = {
"person": {
"name": "Amo",
"age": 18,
"dog": [{
"name": "小花",
"color": "red",
"age": 6,
"isVIP": True
},
{
"name": "小黑",
"color": "black",
"age": 2
}]
}
}
将上述抽象成一个树形结构如图所示:
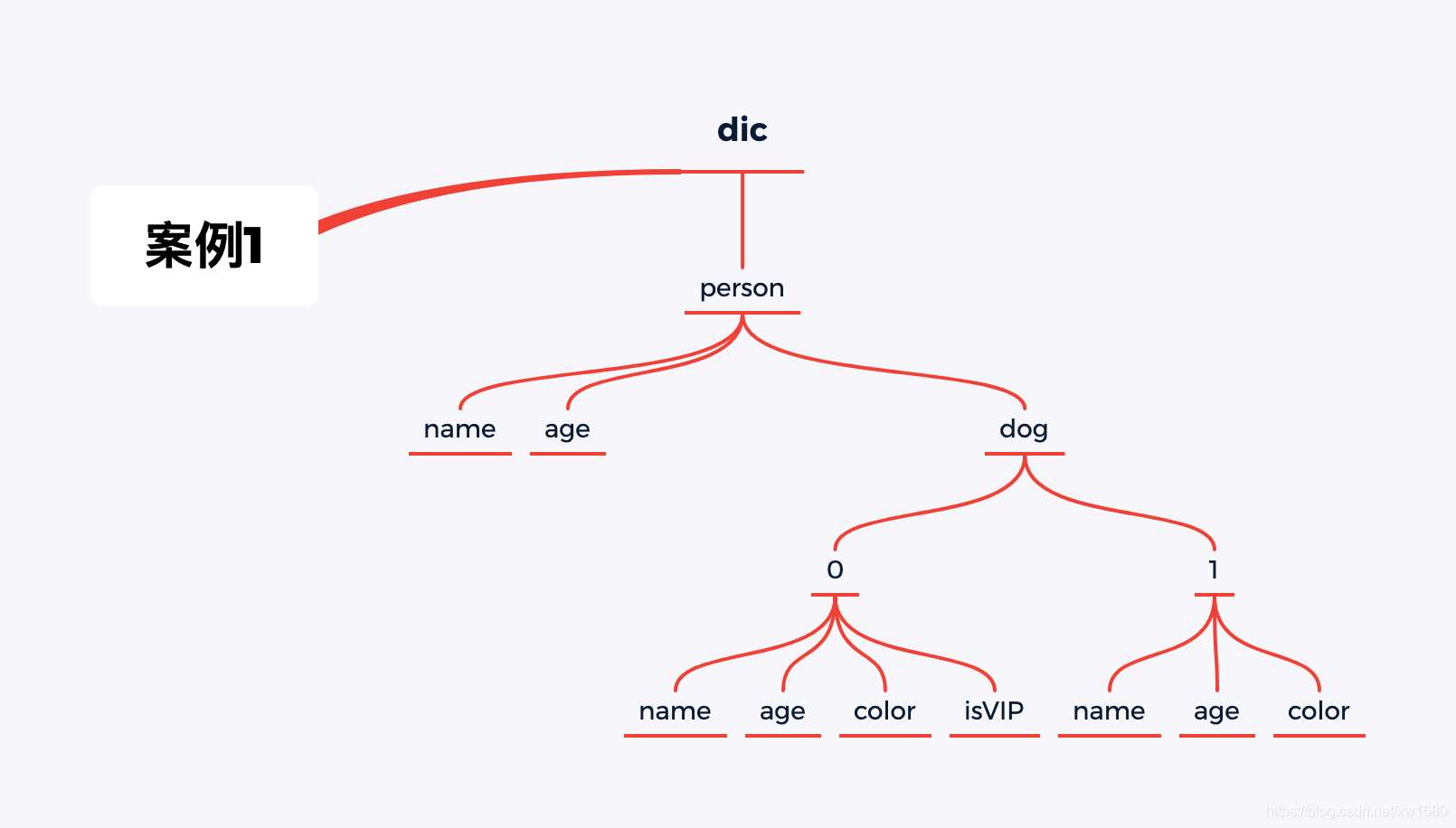
需求及结果如下:
JSONPath
Result
代码如下:
from jsonpath import jsonpath
dic = {
"person": {
"name": "Amo",
"age": 18,
"dog": [{
"name": "小花",
"color": "red",
"age": 6,
"isVIP": True
},
{
"name": "小黑",
"color": "black",
"age": 2
}]
}
}
# 1.获取人的年龄
print(jsonpath(dic, "$.person.age")) # 获取到数据返回一个列表 否则返回False
# 2.获取第2个小狗的年龄
print(jsonpath(dic, "$..dog[1].age"))
# 3.获取所有小狗的年龄
print(jsonpath(dic, "$..dog[0,1].age"))
print(jsonpath(dic, "$..dog[*].age"))
# 4.获取是VIP的小狗
print(jsonpath(dic, "$..dog[?(@.isVIP)]"))
# 5.获取年龄大于2的小狗
print(jsonpath(dic, "$..dog[?(@.age>2)]"))
# 6.获取最后一个小狗
print(jsonpath(dic, "$..dog[-1:]"))
print(jsonpath(dic, "$..dog[(@.length-1)]"))
上述代码执行结果如下:

案例二用到的字典如下:
book_dict = {
"store": {
"book": [
{"category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{"category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{"category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{"category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
}
}
将上述抽象成一个树形结构如图所示:
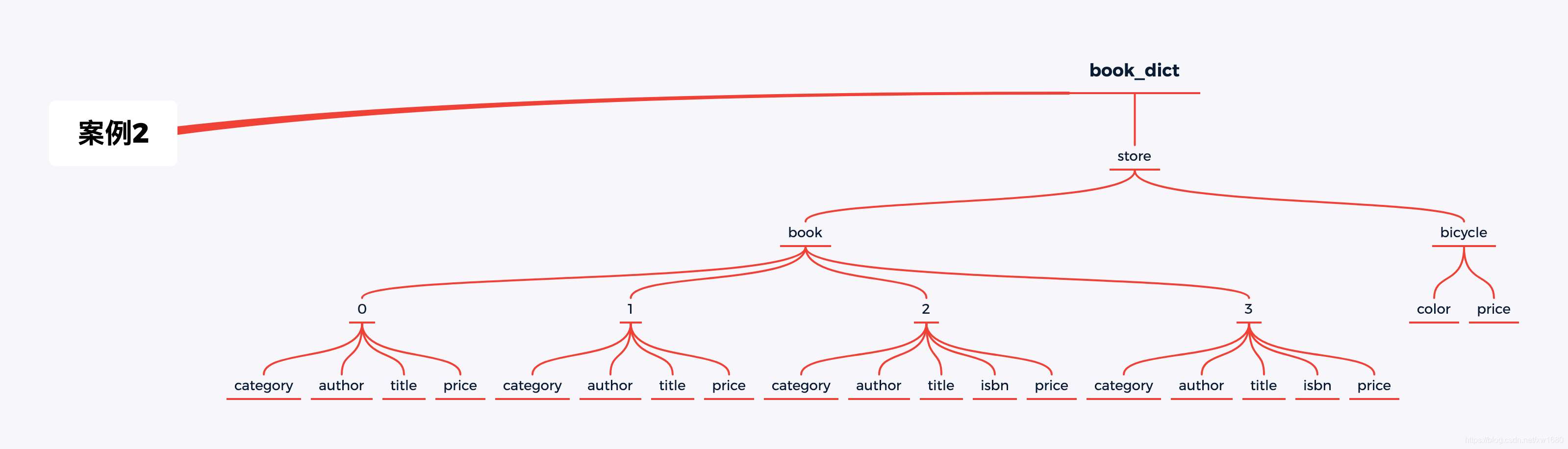
需求及结果如下:
JSONPath
Result
代码如下:
from jsonpath import jsonpath
book_dict = {
"store": {
"book": [
{"category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{"category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{"category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{"category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
}
}
# 1.store中的所有的book的作者
print(jsonpath(book_dict, "$.store.book[*].author"))
print(jsonpath(book_dict, "$..author"))
# 2.store下的所有的元素
print(jsonpath(book_dict, "$.store[*]"))
print(jsonpath(book_dict, "$.store.*"))
# 3.store中的所有的内容的价格
print(jsonpath(book_dict, "$..price"))
# 4.第三本书
print(jsonpath(book_dict, "$..book[2]"))
# 5.最后一本书
print(jsonpath(book_dict, "$..book[-1:]"))
print(jsonpath(book_dict, "$..book[(@.length-1)]"))
# 6.前两本书
print(jsonpath(book_dict, "$..book[0:2]"))
# 7.获取有isbn的所有书
print(jsonpath(book_dict, "$.store.book[?(@.isbn)]"))
# 8.获取价格大于10的所有的书
print(jsonpath(book_dict, "$.store.book[?(@.price>10)]"))
# 9.获取所有的数据
print(jsonpath(book_dict, "$..*"))
5. Python专用JSON解析库pickle
pickle处理的json对象不通用,可以额外的把函数给序列化。示例代码如下:
import pickle
def eat():
print("Amo在努力地写博客~")
person_info_dict = {
"name": "Amo",
"age": 18,
"eat": eat
}
# print(pickle.dumps(person_info_dict))
with open("pickle_json", "wb") as file:
pickle.dump(person_info_dict, file)
with open("pickle_json", "rb") as file:
result = pickle.load(file)
result["eat"]()
JsonPath与XPath语法对比:
Json结构清晰,可读性高,复杂度低,非常容易匹配,下表中对应了XPath的用法。
XPath
JSONPath
描述
到此这篇关于Python 解析库json及jsonpath pickle的实现的文章就介绍到这了,更多相关Python 解析库json及jsonpath pickle内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!