很难找到关于如何使用Python使用DeepMoji的教程。我已经尝试了几次,后来又出现了几次错误,于是决定使用替代版本:torchMoji。
TorchMoji是DeepMoji的pyTorch实现,可以在这里找到:https://github.com/huggingface/torchMoji

事实上,我还没有找到一个关于如何将文本转换为表情符号的教程。如果你也没找到,那么本文就是一个了。
安装
这些代码并不完全是我的写的,源代码可以在这个链接上找到。
pip3 install torch==1.0.1 -f https://download.pytorch.org/whl/cpu/stable
git clone https://github.com/huggingface/torchMoji
import os
os.chdir('torchMoji')
pip3 install -e .
#if you restart the package, the notebook risks to crash on a loop
#I did not restart and worked fine
该代码将下载约600 MB的数据用于训练人工智能。我一直在用谷歌Colab。然而,我注意到,当程序要求您重新启动笔记本进行所需的更改时,它开始在循环中崩溃并且无法补救。如果你使用的是jupyter notebook或者colab记事本不要重新,不管它的重启要求就可以了。
python3 scripts/download_weights.py
这个脚本应该下载需要微调神经网络模型。询问时,按“是”确认。
设置转换功能函数
使用以下函数,可以输入文进行转换,该函数将输出最可能的n个表情符号(n将被指定)。
import numpy as np
import emoji, json
from torchmoji.global_variables import PRETRAINED_PATH, VOCAB_PATH
from torchmoji.sentence_tokenizer import SentenceTokenizer
from torchmoji.model_def import torchmoji_emojis
EMOJIS = ":joy: :unamused: :weary: :sob: :heart_eyes: :pensive: :ok_hand: :blush: :heart: :smirk: :grin: :notes: :flushed: :100: :sleeping: :relieved: :relaxed: :raised_hands: :two_hearts: :expressionless: :sweat_smile: :pray: :confused: :kissing_heart: :heartbeat: :neutral_face: :information_desk_person: :disappointed: :see_no_evil: :tired_face: :v: :sunglasses: :rage: :thumbsup: :cry: :sleepy: :yum: :triumph: :hand: :mask: :clap: :eyes: :gun: :persevere: :smiling_imp: :sweat: :broken_heart: :yellow_heart: :musical_note: :speak_no_evil: :wink: :skull: :confounded: :smile: :stuck_out_tongue_winking_eye: :angry: :no_good: :muscle: :facepunch: :purple_heart: :sparkling_heart: :blue_heart: :grimacing: :sparkles:".split(' ')
model = torchmoji_emojis(PRETRAINED_PATH)
with open(VOCAB_PATH, 'r') as f:
vocabulary = json.load(f)
st = SentenceTokenizer(vocabulary, 30)def deepmojify(sentence,top_n =5):
def top_elements(array, k):
ind = np.argpartition(array, -k)[-k:]
return ind[np.argsort(array[ind])][::-1]tokenized, _, _ = st.tokenize_sentences([sentence])
prob = model(tokenized)[0]
emoji_ids = top_elements(prob, top_n)
emojis = map(lambda x: EMOJIS[x], emoji_ids)
return emoji.emojize(f"{sentence} {' '.join(emojis)}", use_aliases=True)
文本实验
text = ['I hate coding AI']for _ in text: print(deepmojify(_, top_n = 3))
输出

如您所见,这里给出的是个列表,所以可以添加所需的字符串数。
原始神经网络
如果你不知道如何编码,你只想试一试,你可以使用DeepMoji的网站:https://deepmoji.mit.edu/
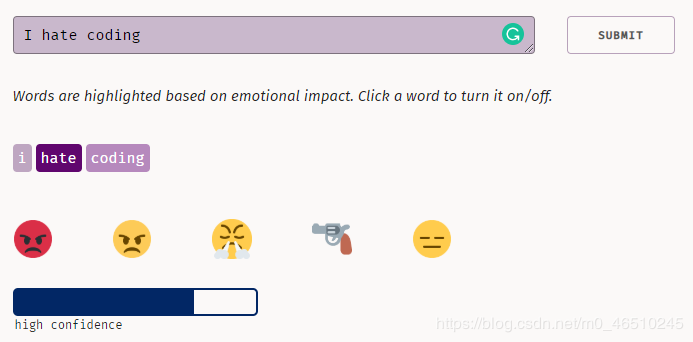
源代码应该完全相同,事实上,如果我输入5个表情符号而不是3个,这就是我代码中的结果:

输入列表而不是一句话
在进行情绪分析时,我通常会在Pandas上存储tweets或评论的数据库,我将使用以下代码,将字符串列表转换为Pandas数据帧,其中包含指定数量的emojis。
import pandas as pddef emoji_dataset(list1, n_emoji=3): emoji_list = [[x] for x in list1]for _ in range(len(list1)): for n_emo in range(1, n_emoji+1): emoji_list[_].append(deepmojify(list1[_], top_n = n_emoji)[2*-n_emo+1])emoji_list = pd.DataFrame(emoji_list) return emoji_listlist1 = ['Stay safe from the virus', 'Push until you break!', 'If it does not challenge you, it will not change you']
我想估计一下这个字符串列表中最有可能出现的5种表情:
emoji_dataset(list1, 5)
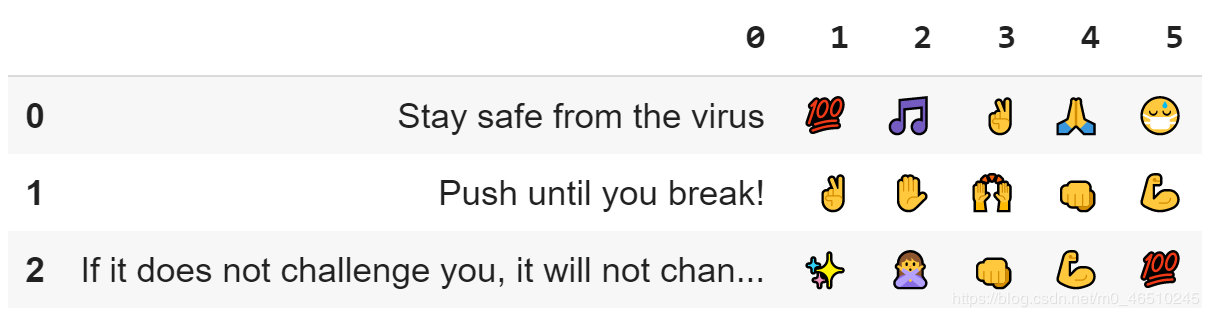
就是这么简单
作者:Michelangiolo Mazzeschi
deephub翻译组
到此这篇关于详解在Python中使用Torchmoji将文本转换为表情符号的文章就介绍到这了,更多相关Python Torchmoji文本转换为表情符号内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!