实现思路:分为两部分,第一部分,获取网页上数据并使用xlwt生成excel(当然你也可以选择保存到数据库),第二部分获取网页数据使用IO流将图片保存到本地 一、爬取所有英雄属性并
实现思路:分为两部分,第一部分,获取网页上数据并使用xlwt生成excel(当然你也可以选择保存到数据库),第二部分获取网页数据使用IO流将图片保存到本地
一、爬取所有英雄属性并生成excel
1.代码
import json
import requests
import xlwt
# 设置头部信息,防止被检测出是爬虫
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'
}
url = "https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js"
response = requests.get(url=url, headers=headers).text
loads = json.loads(response)
dic = loads['hero']
# 创建一个workbook 设置编码
workbook = xlwt.Workbook(encoding='utf-8')
# 创建一个worksheet
worksheet = workbook.add_sheet('LOL')
try:
for i in range(len(dic)):
# 设置单元格宽度大小
worksheet.col(i).width = 4000
# 设置单元格高度大小
style = xlwt.easyxf('font:height 300')
worksheet.row(i).set_style(style)
# 第一行用于写入表头
if i == 0:
worksheet.write(i, 0, '编号')
worksheet.write(i, 1, '名称')
worksheet.write(i, 2, '英文名')
worksheet.write(i, 3, '中文名')
worksheet.write(i, 4, '角色')
worksheet.write(i, 5, '物攻')
worksheet.write(i, 6, '物防')
worksheet.write(i, 7, '魔攻')
worksheet.write(i, 8, '魔防')
continue
worksheet.write(i, 0, dic[i - 1]['heroId'])
worksheet.write(i, 1, dic[i - 1]['name'])
worksheet.write(i, 2, dic[i - 1]['alias'])
worksheet.write(i, 3, dic[i - 1]['title'])
roles_ = dic[i - 1]['roles']
roles = []
for data in roles_:
if 'mage' == data:
roles.append('法师')
if 'tank' == data:
roles.append('坦克')
if 'fighter' == data:
roles.append('战士')
if 'marksman' == data:
roles.append('ADC')
if 'assassin' == data:
roles.append('刺客')
if 'support' == data:
roles.append('辅助')
worksheet.write(i, 4, str(roles))
worksheet.write(i, 5, dic[i - 1]['attack'])
worksheet.write(i, 6, dic[i - 1]['defense'])
worksheet.write(i, 7, dic[i - 1]['magic'])
worksheet.write(i, 8, dic[i - 1]['difficulty'])
# 保存
workbook.save('C:\\Users\\Jonsson\\Desktop\\lol.xls')
except Exception as e:
print(e)
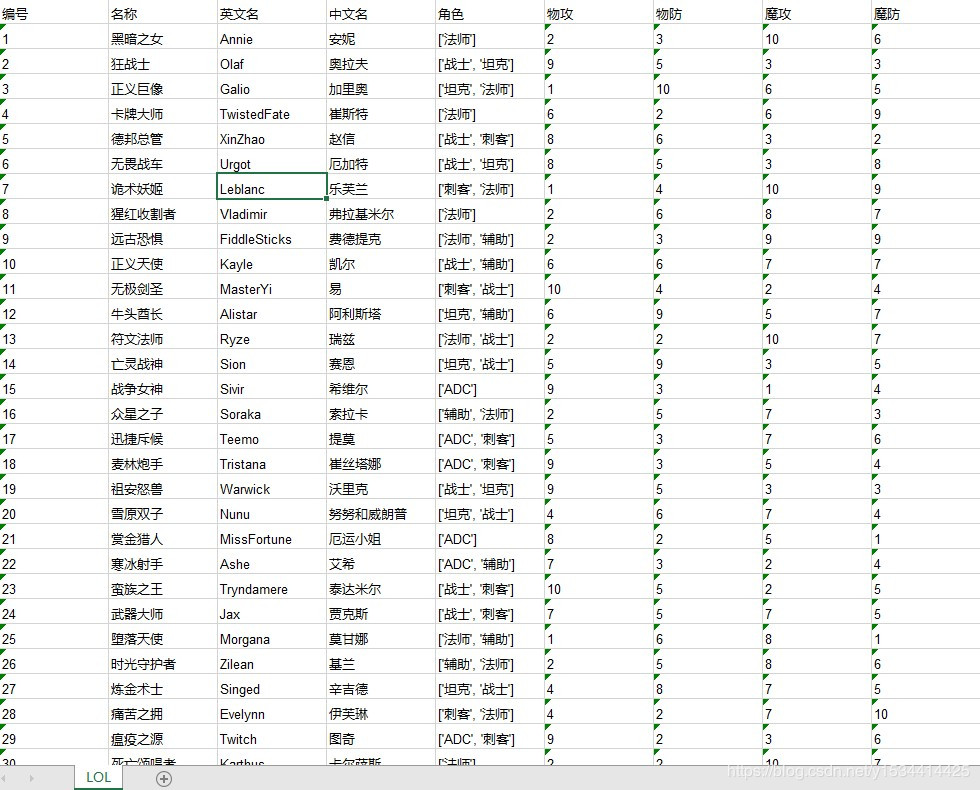
2.效果
二、爬取所有英雄皮肤并保存到本地
1.代码
import json
import os
import requests
import xlwt
# 设置头部信息,防止被检测出是爬虫
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'
}
url = "https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js"
# 请求英雄列表的url地址
response = requests.get(url=url, headers=headers).text
loads = json.loads(response)
dic = loads['hero']
for data in dic:
id_ = data['heroId']
skinUrl = 'https://game.gtimg.cn/images/lol/act/img/js/hero/%s.js' % id_
# 请求每个英雄皮肤的url地址
skinResponse = requests.get(url=skinUrl, headers=headers).text
json_loads = json.loads(skinResponse)
hero_ = json_loads['hero']
save_path = './skin/%s-%s-%s' % (hero_["heroId"], hero_['name'], hero_['title'])
# 文件夹不存在,则创建文件夹
folder = os.path.exists(save_path)
if not folder:
os.makedirs(save_path)
skins_ = json_loads['skins']
for data in skins_:
if data['chromas'] == '0':
content = requests.get(url=data['mainImg'], headers=headers).content
try:
with open('%s/%s.jpg' % (save_path, data['name']), "wb") as f:
print("正在下载英雄:%s 皮肤名称:%s ..." % (hero_['name'], data['name']))
f.write(content)
except Exception as e:
print('下载失败')
print(e)
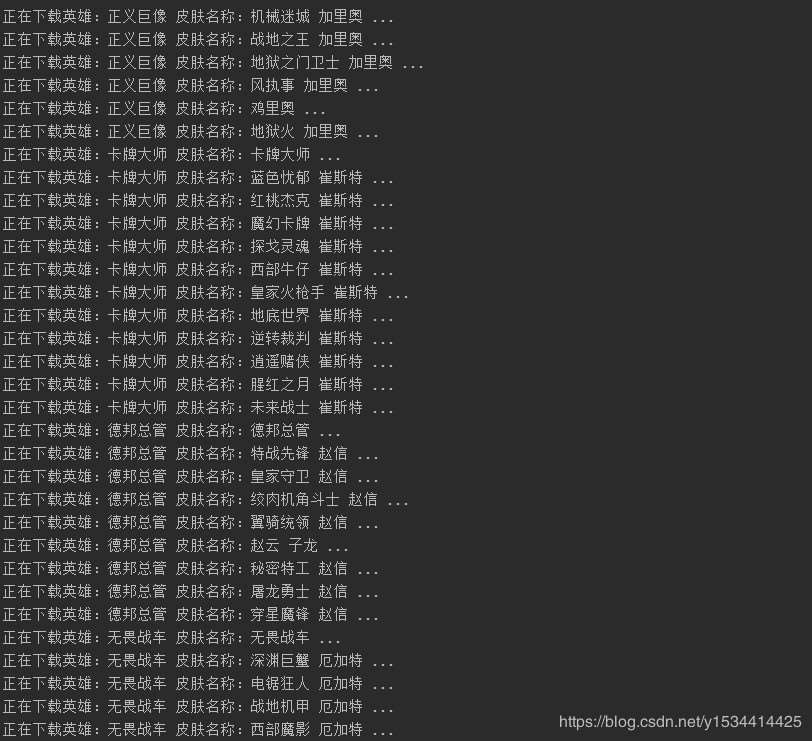
2.效果

到此这篇关于用Python爬取LOL所有的英雄信息以及英雄皮肤的示例代码的文章就介绍到这了,更多相关Python爬取LOL所有英雄内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!