实验环境:windows 7,anaconda 3(Python 3.5),tensorflow(gpu/cpu)
函数介绍:标准化处理可以使得不同的特征具有相同的尺度(Scale)。
这样,在使用梯度下降法学习参数的时候,不同特征对参数的影响程度就一样了。
tf.image.per_image_standardization(image),此函数的运算过程是将整幅图片标准化(不是归一化),加速神经网络的训练。
主要有如下操作,(x - mean) / adjusted_stddev,其中x为图片的RGB三通道像素值,mean分别为三通道像素的均值,adjusted_stddev = max(stddev, 1.0/sqrt(image.NumElements()))。
stddev为三通道像素的标准差,image.NumElements()计算的是三通道各自的像素个数。
实验代码:
import tensorflow as tf
import matplotlib.image as img
import matplotlib.pyplot as plt
import numpy as np
sess = tf.InteractiveSession()
image = img.imread('D:/Documents/Pictures/logo7.jpg')
shape = tf.shape(image).eval()
h,w = shape[0],shape[1]
standardization_image = tf.image.per_image_standardization(image)#标准化
fig = plt.figure()
fig1 = plt.figure()
ax = fig.add_subplot(111)
ax.set_title('orginal image')
ax.imshow(image)
ax1 = fig1.add_subplot(311)
ax1.set_title('original hist')
ax1.hist(sess.run(tf.reshape(image,[h*w,-1])))
ax1 = fig1.add_subplot(313)
ax1.set_title('standardization hist')
ax1.hist(sess.run(tf.reshape(standardization_image,[h*w,-1])))
plt.ion()
plt.show()
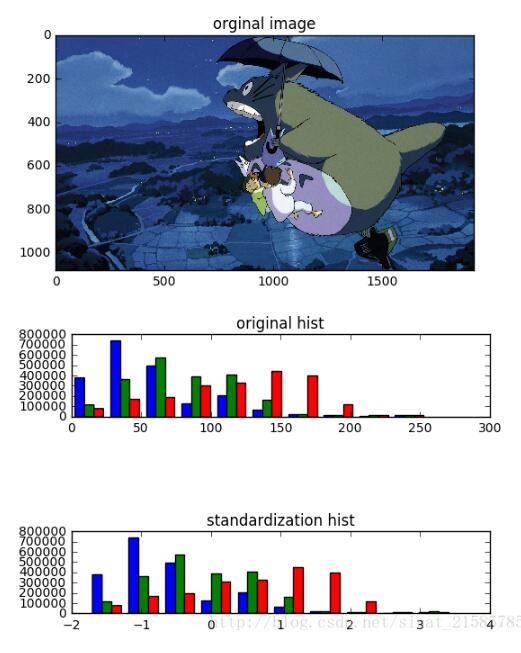
实验结果:
两幅hist图分别是原图和标准化后的RGB的像素值分布图,可以看到只是将图片的像素值大小限定到一个范围,但是像素值的分布为改变。
补充知识:tensorflow运行单张图像与加载模型时注意的问题
关于模型的保存加载:
在做实验的情况下,一般使用save函数与restore函数就足够用,该刚发只加载模型的参数而不加载模型,这意味着
当前的程序要能找到模型的结构
saver = tf.train.Saver()#声明saver用来保存模型 with tf.Session() as sess: for i in range(train_step): #.....训练操作 if i%100 == 0 && i!= 0:#每间隔训练100次存储一个模型,默认最多能存5个,如果超过5个先将序号小的覆盖掉 saver.save(sess,str(i)+"_"+'model.ckpt',global_step=i)
得到的文件如下:
在一个文件夹中,会有一个checkpoint文件,以及一系列不同训练阶段的模型文件,如下图
ckeckpoint文件可以放在编辑器里面打开看,里面记录的是每个阶段保存模型的信息,同时也是记录最近训练的检查点
ckpt文件是模型参数,index文件一般用不到(我也查到是啥-_-|||)
在读取模型时,声明一个saver调用restore函数即可,我看很多博客里面写的都是添加最近检查点的模型,这样添加的模型都是最后一次训练的结果,想要加载固定的模型,直接把模型参数名称的字符串写到参数里就行了,如下段程序
saver = tf.train.Saver() with tf.Session() as sess: saver.restore(sess, "step_1497batch_64model.ckpt-1497")#加载对应的参数
这样就把参数加载到Session当中,如果有数据,就可以直接塞进来进行计算了
运行单张图片:
运行单张图像的方法的流程大致如下,首先使用opencv或者Image或者使用numpy将图像读进来,保存成numpy的array的格式
接下来可以对图像使用opencv进行预处理。然后将处理后的array使用feed_dict的方式输入到tensorflow的placeholder中,这里注意两点,不要单独的使用下面的方法将tensor转换成numpy再进行处理,除非是想查看一下图像输出,否则在验证阶段,强烈不要求这样做,尽量使用feed_dict,原因后面说明
numpy_img = sess.run(tensor_img)#将tensor转换成numpy
这里注意一点,如果你的图像是1通道的图像,即灰度图,那么你得到的numpy是一个二维矩阵,将使用opencv读入的图像输出shape会得到如(424,512)这样的形状,分别表示行和列,但是在模型当中通常要要有batch和通道数,所以需要将图像使用python opencv库中的reshape函数转换成四维的矩阵,如
cv_img = cv_img.reshape(1,cv_img.shape[0],cv_img.shape[1],1)#cv_img是使用Opencv读进来的图片
用来输入到网络中的placeholder设置为如下,即可进行输入了
img_raw = tf.placeholder(dtype=tf.float32, shape=[1,512, 424, 1], name='input')
测试:
如果使用的是自己的数据集,通常是制作成tfrecords,在训练和测试的过程中,需要读取tfrecords文件,这里注意,千万不要把读取tfrecords文件的函数放到循环当中,而是把这个文件放到外面,否则你训练或者测试的数据都是同一批,Loss会固定在一个值!
这是因为tfrecords在读取的过程中是将图像信息加入到一个队列中进行读取,不要当成普通的函数调用,要按照tensorflow的思路,将它看成一个节点!
def read_data(tfrecords_file, batch_size, image_size):#读取tfrecords文件
filename_queue = tf.train.string_input_producer([tfrecords_file])
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
img_features = tf.parse_single_example(
serialized_example,
features={
'label': tf.FixedLenFeature([], tf.int64),
'image_raw': tf.FixedLenFeature([], tf.string),
})
image = tf.decode_raw(img_features['image_raw'], tf.float32)
min_after_dequeue = 1000
image = tf.reshape(image, [image_size, image_size,1])
image = tf.image.resize_images(image, (32,32),method=3)#缩放成32×32
image = tf.image.per_image_standardization(image)#图像标准化
label = tf.cast(img_features['label'], tf.int32)
capacity = min_after_dequeue + 3 * batch_size
image_batch, label_batch = tf.train.shuffle_batch([image, label],
min_after_dequeue = min_after_dequeue)
return image_batch, tf.one_hot(label_batch,6)#返回的标签经过one_hot编码
#将得到的图像数据与标签都是tensor哦,不能输出的!
read_image_batch,read_label_batch = read_data('train_data\\tfrecord\\TrainC6_95972.tfrecords',batch_size,120)
回到在运行单张图片的那个问题,直接对某个tensor进行sess.run()会得到图计算后的类型,也就是咱们python中常见的类型。
使用sess.run(feed_dict={…})得到的计算结果和直接使用sess.run有什么不同呢?
可以使用一个循环实验一下,在循环中不停的调用sess.run()相当于每次都向图中添加节点,而使用sess.run(feed_dict={})是向图中开始的位置添加数据!
结果会发现,直接使用sess.run()的运行会越来越慢,使用sess.run(feed_dict={})会运行的飞快!
为什么要提这个呢?
在上面的read_data中有这么三行函数
image = tf.reshape(image, [image_size, image_size,1])#与opencv的reshape结果一样 image = tf.image.resize_images(image, (32,32),method=3)#缩放成32×32,与opencv的resize结果一样,插值方法要选择三次立方插值 image = tf.image.per_image_standardization(image)#图像标准化
如果想要在将训练好的模型作为网络节点添加到系统中,得到的数据必须是经过与训练数据经过相同处理的图像,也就是必须要对原始图像经过上面的处理。如果使用其他的库容易造成结果对不上,最好使用与训练数据处理时相同的函数。
如果使用将上面的函数当成普通的函数使用,得到的是一个tensor,没有办法进行其他的图像预处理,需要先将tensor变成numpy类型,问题来了,想要变成numpy类型,就得调用sess.run(),如果模型作为接口死循环,那么就会一直使用sess.run,效率会越来越慢,最后卡死!
原因在于你没有将tensorflow中的函数当成节点调用,而是将其当成普通的函数调用了!
解决办法就是按部就班的来,将得到的numpy数据先提前处理好,然后使用sess.run(feed_dict)输入到placeholder中,按照图的顺序一步一步运行即可!
如下面程序
with tf.name_scope('inputs'):
img_raw = tf.placeholder(dtype=tf.float32, shape=[1,120, 120, 1], name='input')#输入数据
keep_prob = tf.placeholder(tf.float32,name='keep_prob')
with tf.name_scope('preprocess'):#图中的预处理函数,当成节点顺序调用
img_120 = tf.reshape(img_raw, [120, 120,1])
img_norm = tf.cast(img_120, "float32") / 256
img_32 = tf.image.resize_images(img_norm, (32,32),method=3)
img_std = tf.image.per_image_standardization(img_32)
img = tf.reshape(img_std, [1,32, 32,1])
with tf.name_scope('output'):#图像塞到网络中
output = MyNet(img,keep_prob,n_cls)
ans = tf.argmax(tf.nn.softmax(output),1)#计算模型得到的结果
init = tf.global_variables_initializer()
saver = tf.train.Saver()
if __name__ == '__main__':
with tf.Session() as sess:
sess.run(init)
saver.restore(sess, "step_1497batch_64model.ckpt-1497")#效果更好
index = 0
path = "buffer\\"
while True:
f = path + str(index)+'.jpg'#从0.jpg、1.jpg、2.jpg.....一直读
if os.path.exists(f):
cv_img = cv.imread(f,0)
cv_img = OneImgPrepro(cv_img)
cv_img = cv_img.reshape(1,cv_img.shape[0],cv_img.shape[1],1)#需要reshape成placeholder可接收型
clas = ans.eval(feed_dict={img_raw:cv_img,keep_prob:1})#feed的速度快!
print(clas)#输出分类
index += 1
以上这篇tensorflow下的图片标准化函数per_image_standardization用法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持易盾网络。