从github上转来,实在是厉害的想法,什么时候自己也能写出这种精妙的代码就好了
原地址:简易高效的LeakyReLu实现
代码如下:
我做了些改进,因为实在tensorflow中使用,就将原来的abs()函数替换成了tf.abs()
import tensorflow as tf
def LeakyRelu(x, leak=0.2, name="LeakyRelu"):
with tf.variable_scope(name):
f1 = 0.5 * (1 + leak)
f2 = 0.5 * (1 - leak)
return f1 * x + f2 * tf.abs(x) # 这里和原文有不一样的,我没试验过原文的代码,但tf.abs()肯定是对的
补充知识:激活函数ReLU、Leaky ReLU、PReLU和RReLU
“激活函数”能分成两类——“饱和激活函数”和“非饱和激活函数”。
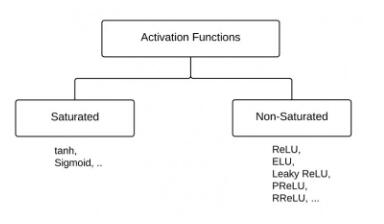
sigmoid和tanh是“饱和激活函数”,而ReLU及其变体则是“非饱和激活函数”。使用“非饱和激活函数”的优势在于两点:
1.首先,“非饱和激活函数”能解决所谓的“梯度消失”问题。
2.其次,它能加快收敛速度。
Sigmoid函数需要一个实值输入压缩至[0,1]的范围
σ(x) = 1 / (1 + exp(−x))
tanh函数需要讲一个实值输入压缩至 [-1, 1]的范围
tanh(x) = 2σ(2x) − 1
ReLU
ReLU函数代表的的是“修正线性单元”,它是带有卷积图像的输入x的最大函数(x,o)。ReLU函数将矩阵x内所有负值都设为零,其余的值不变。ReLU函数的计算是在卷积之后进行的,因此它与tanh函数和sigmoid函数一样,同属于“非线性激活函数”。这一内容是由Geoff Hinton首次提出的。
ELUs
ELUs是“指数线性单元”,它试图将激活函数的平均值接近零,从而加快学习的速度。同时,它还能通过正值的标识来避免梯度消失的问题。根据一些研究,ELUs分类精确度是高于ReLUs的。下面是关于ELU细节信息的详细介绍:
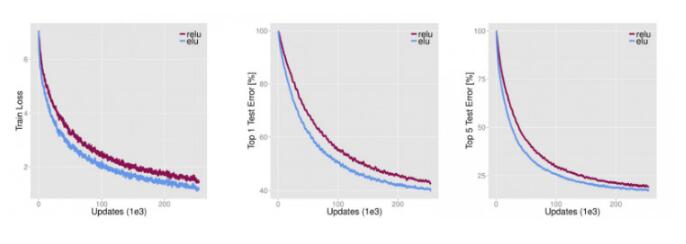
Leaky ReLUs
ReLU是将所有的负值都设为零,相反,Leaky ReLU是给所有负值赋予一个非零斜率。Leaky ReLU激活函数是在声学模型(2013)中首次提出的。以数学的方式我们可以表示为:

ai是(1,+∞)区间内的固定参数。
参数化修正线性单元(PReLU)
PReLU可以看作是Leaky ReLU的一个变体。在PReLU中,负值部分的斜率是根据数据来定的,而非预先定义的。作者称,在ImageNet分类(2015,Russakovsky等)上,PReLU是超越人类分类水平的关键所在。
随机纠正线性单元(RReLU)
“随机纠正线性单元”RReLU也是Leaky ReLU的一个变体。在RReLU中,负值的斜率在训练中是随机的,在之后的测试中就变成了固定的了。RReLU的亮点在于,在训练环节中,aji是从一个均匀的分布U(I,u)中随机抽取的数值。形式上来说,我们能得到以下结果:
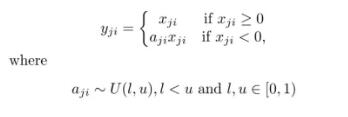
总结
下图是ReLU、Leaky ReLU、PReLU和RReLU的比较:
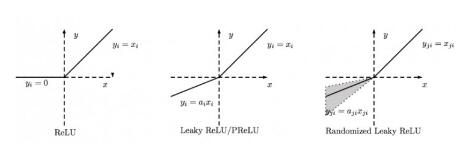
PReLU中的ai是根据数据变化的;
Leaky ReLU中的ai是固定的;
RReLU中的aji是一个在一个给定的范围内随机抽取的值,这个值在测试环节就会固定下来。
以上这篇在Tensorflow中实现leakyRelu操作详解(高效)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持易盾网络。