先看Pytorch中的卷积
class torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
二维卷积层, 输入的尺度是(N, C_in,H,W),输出尺度(N,C_out,H_out,W_out)的计算方式
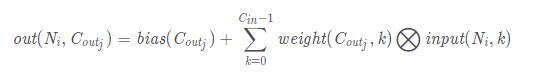
这里比较奇怪的是这个卷积层居然没有定义input shape,输入尺寸明明是:(N, C_in, H,W),但是定义中却只需要输入in_channel的size,就能完成卷积,那是不是说这样任意size的image都可以进行卷积呢?
然后我进行了下面这样的实验:
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 输入图像channel:1;输出channel:6;5x5卷积核
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# 2x2 Max pooling
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# If the size is a square you can only specify a single number
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # 除去批大小维度的其余维度
num_features = 1
for s in size:
num_features *= s
return num_features
net = Net()
print(net)
输出
Net( (conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1)) (conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1)) (fc1): Linear(in_features=400, out_features=120, bias=True) (fc2): Linear(in_features=120, out_features=84, bias=True) (fc3): Linear(in_features=84, out_features=10, bias=True) )
官网Tutorial 说:这个网络(LeNet)的期待输入是32x32,我就比较奇怪他又没有设置Input shape或者Tensorflow里的Input层,怎么就知道(H,W) =(32, 32)。
输入:
input = torch.randn(1, 1, 32, 32)
output = Net(input)
没问题,但是
input = torch.randn(1, 1, 64, 64)
output = Net(input)
出现:mismatch Error
我们看一下卷积模型部分。
input:(1, 1, 32, 32) --> conv1(1, 6, 5) --> (1, 6, 28, 28) --> max_pool1(2, 2) --> (1, 6, 14, 14) --> conv2(6, 16, 5) -->(1, 16, 10, 10) --> max_pool2(2, 2) --> (1, 16, 5, 5)
然后是将其作为一个全连接网络的输入。Linear相当于tensorflow 中的Dense。所以当你的输入尺寸不为(32, 32)时,卷积得到最终feature map shape就不是(None, 16, 5, 5),而我们的第一个Linear层的输入为(None, 16 * 5 * 5),故会出现mismatch Error。
之所以会有这样一个问题还是因为keras model 必须提定义Input shape,而pytorch更像是一个流程化操作,具体看官网吧。
补充知识:pytorch 卷积 分组卷积 及其深度卷积
先来看看pytorch二维卷积的操作API

现在继续讲讲几个卷积是如何操作的。
一. 普通卷积
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
普通卷积时group默认为1 dilation=1(这里先暂时不讨论dilation)其余都正常的话,比如输入为Nx in_channel x high x width
输出为N x out_channel x high xwidth .还是来具体的数字吧,输入为64通道的特征图,输出为32通道的特征图,要想得到32通道的特征图就必须得有32种不同的卷积核。
也就是上面传入的参数out_channel。继续说说具体是怎么的得到的,对于每一种卷积核会和64种不同的特征图依次进行卷积,比如卷积核大小是3x3大小的,由于卷积权值共享,所以对于输入的一张特征图卷积时,只有3x3个参数,同一张特征图上进行滑窗卷积操作时参数是一样的,刚才说的第一种卷积核和输入的第一个特征图卷积完后再继续和后面的第2,3,........64个不同的特征图依次卷积(一种卷积核对于输入特征图来说,同一特征图上面卷积,参数一样,对于不同的特征图上卷积不一样),最后的参数是3x3x64。
此时输出才为一个特征图,因为现在才只使用了一种卷积核。一种核分别在局部小窗口里面和64个特征图卷积应该得到64个数,最后将64个数相加就可以得到一个数了,也就是输出一个特征图上对应于那个窗口的值,依次滑窗就可以得到完整的特征图了。
前面将了这么多才使用一种卷积核,那么现在依次类推使用32种不同的卷积核就可以得到输出的32通道的特征图。最终参数为64x3x3x32.
二.分组卷积
参数group=1时,就是和普通的卷积一样。现在假如group=4,前提是输入特征图和输出特征图必须是4的倍数。现在来看看是如何操作的。in_channel64分成4组,out_inchannel(也就是32种核)也分成4组,依次对应上面的普通卷方式,最终将每组输出的8个特征图依次concat起来,就是结果的out_channel
三. 深度卷积depthwise
此时group=in_channle,也就是对每一个输入的特征图分别用不同的卷积核卷积。out_channel必须是in_channel 的整数倍。
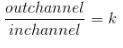
3.1 当k=1时,out_channel=in_channel ,每一个卷积核分别和每一个输入的通道进行卷积,最后在concat起来。参数总量为3x3x64。如果此时卷积完之后接着一个64个1x1大小的卷积核。就是谷歌公司于2017年的CVPR中在论文”Xception: deep learning with depthwise separable convolutions”中提出的结构。如下图
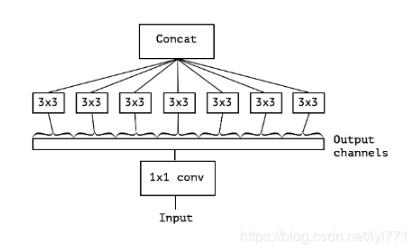
上图是将1x1放在depthwise前面,其实原理都一样。最终参数的个数是64x1x1+64x3x3。参数要小于普通的卷积方法64x3x3x64
3.2 当k是大于1的整数时,比如k=2
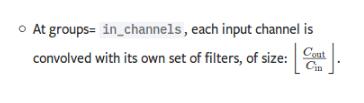
此时每一个输入的特征图对应k个卷积核,生成k特征图,最终生成的特征图个数就是k×in_channel .
以上这篇Pytorch 卷积中的 Input Shape用法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持易盾网络。