加载模型字典
逐一判断每一层,如果该层是bn 的 running mean,就取出参数并取平均作为该层的代表
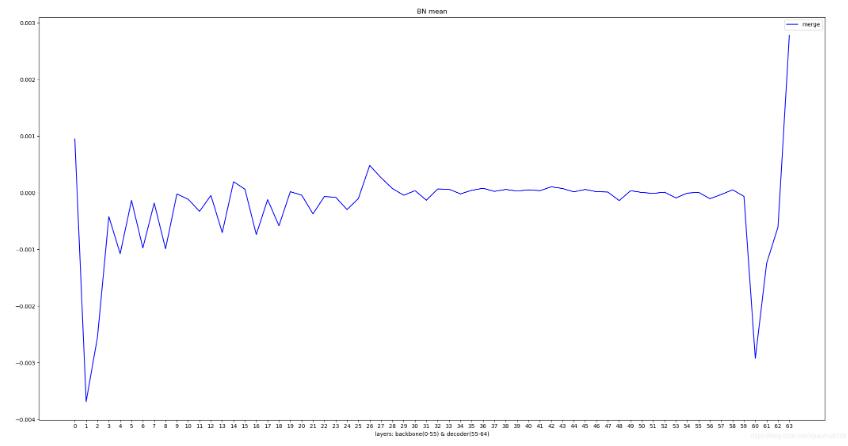
对保存的每个BN层的数值进行曲线可视化
from functools import partial
import pickle
import torch
import matplotlib.pyplot as plt
pth_path = 'checkpoint.pth'
pickle.load = partial(pickle.load, encoding="latin1")
pickle.Unpickler = partial(pickle.Unpickler, encoding="latin1")
pretrained_dict = torch.load(pth_path, map_location=lambda storage, loc: storage, pickle_module=pickle)
pretrained_dict = pretrained_dict['state_dict']
means = []
for name, param in pretrained_dict.items():
print(name)
if 'running_mean' in name:
means.append(mean.numpy())
layers = [i for i in range(len(means))]
plt.plot(layers, means, color='blue')
plt.legend()
plt.xticks(layers)
plt.xlabel('layers')
plt.show()
补充知识:关于pytorch中BN层(具体实现)的一些小细节
最近在做目标检测,需要把训好的模型放到嵌入式设备上跑前向,因此得把各种层的实现都用C手撸一遍,,,此为背景。
其他层没什么好说的,但是BN层这有个小坑。pytorch在打印网络参数的时候,只打出weight和bias这两个参数。咦,说好的BN层有四个参数running_mean、running_var 、gamma 、beta的呢?一开始我以为是pytorch把BN层的计算简化成weight * X + bias,但马上反应过来应该没这么简单,因为pytorch中只有可学习的参数才称为parameter。上网找了一些资料但都没有说到这么细的,毕竟大部分用户使用时只要模型能跑起来就行了,,,于是开始看BN层有哪些属性,果然发现了熟悉的running_mean和running_var,原来pytorch的BN层实现并没有不同。这里吐个槽:为啥要把gamma和beta改叫weight、bias啊,很有迷惑性的好不好,,,
扯了这么多,干脆捋一遍pytorch里BN层的具体实现过程,帮自己理清思路,也可以给大家提供参考。再吐槽一下,在网上搜“pytorch bn层”出来的全是关于这一层怎么用的、初始化时要输入哪些参数,没找到一个pytorch中BN层是怎么实现的,,,
众所周知,BN层的输出Y与输入X之间的关系是:Y = (X - running_mean) / sqrt(running_var + eps) * gamma + beta,此不赘言。其中gamma、beta为可学习参数(在pytorch中分别改叫weight和bias),训练时通过反向传播更新;而running_mean、running_var则是在前向时先由X计算出mean和var,再由mean和var以动量momentum来更新running_mean和running_var。所以在训练阶段,running_mean和running_var在每次前向时更新一次;在测试阶段,则通过net.eval()固定该BN层的running_mean和running_var,此时这两个值即为训练阶段最后一次前向时确定的值,并在整个测试阶段保持不变。
以上这篇可视化pytorch 模型中不同BN层的running mean曲线实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持易盾网络。