Keras确实是一大神器,代码可以写得非常简洁,但是最近在写LSTM和DeepFM的时候,遇到了一个问题:样本的长度不一样。对不定长序列的一种预处理方法是,首先对数据进行padding补0,然后引入keras的Masking层,它能自动对0值进行过滤。
问题在于keras的某些层不支持Masking层处理过的输入数据,例如Flatten、AveragePooling1D等等,而其中meanpooling是我需要的一个运算。例如LSTM对每一个序列的输出长度都等于该序列的长度,那么均值运算就只应该除以序列长度,而不是padding后的最长长度。
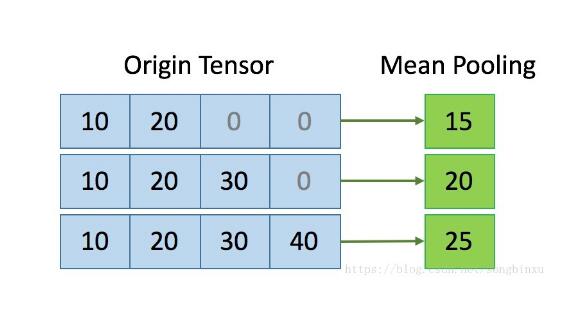
例如下面这个 3x4 大小的张量,经过补零padding的。我希望做axis=1的meanpooling,则第一行应该是 (10+20)/2,第二行应该是 (10+20+30)/3,第三行应该是 (10+20+30+40)/4。
Keras如何自定义层
在 Keras2.0 版本中(如果你使用的是旧版本请更新),自定义一个层的方法参考这里。具体地,你只要实现三个方法即可。
build(input_shape) : 这是你定义层参数的地方。这个方法必须设self.built = True,可以通过调用super([Layer], self).build()完成。如果这个层没有需要训练的参数,可以不定义。
call(x) : 这里是编写层的功能逻辑的地方。你只需要关注传入call的第一个参数:输入张量,除非你希望你的层支持masking。
compute_output_shape(input_shape) : 如果你的层更改了输入张量的形状,你应该在这里定义形状变化的逻辑,这让Keras能够自动推断各层的形状。
下面是一个简单的例子:
from keras import backend as K from keras.engine.topology import Layer import numpy as np class MyLayer(Layer): def __init__(self, output_dim, **kwargs): self.output_dim = output_dim super(MyLayer, self).__init__(**kwargs) def build(self, input_shape): # Create a trainable weight variable for this layer. self.kernel = self.add_weight(name='kernel', shape=(input_shape[1], self.output_dim), initializer='uniform', trainable=True) super(MyLayer, self).build(input_shape) # Be sure to call this somewhere! def call(self, x): return K.dot(x, self.kernel) def compute_output_shape(self, input_shape): return (input_shape[0], self.output_dim)
Keras自定义层如何允许masking
观察了一些支持masking的层,发现他们对masking的支持体现在两方面。
在 __init__ 方法中设置 supports_masking=True。
实现一个compute_mask方法,用于将mask传到下一层。
部分层会在call中调用传入的mask。
自定义实现带masking的meanpooling
假设输入是3d的。首先,在__init__方法中设置self.supports_masking = True,然后在call中实现相应的计算。
from keras import backend as K from keras.engine.topology import Layer import tensorflow as tf class MyMeanPool(Layer): def __init__(self, axis, **kwargs): self.supports_masking = True self.axis = axis super(MyMeanPool, self).__init__(**kwargs) def compute_mask(self, input, input_mask=None): # need not to pass the mask to next layers return None def call(self, x, mask=None): if mask is not None: mask = K.repeat(mask, x.shape[-1]) mask = tf.transpose(mask, [0,2,1]) mask = K.cast(mask, K.floatx()) x = x * mask return K.sum(x, axis=self.axis) / K.sum(mask, axis=self.axis) else: return K.mean(x, axis=self.axis) def compute_output_shape(self, input_shape): output_shape = [] for i in range(len(input_shape)): if i!=self.axis: output_shape.append(input_shape[i]) return tuple(output_shape)
使用举例:
from keras.layers import Input, Masking from keras.models import Model from MyMeanPooling import MyMeanPool data = [[[10,10],[0, 0 ],[0, 0 ],[0, 0 ]], [[10,10],[20,20],[0, 0 ],[0, 0 ]], [[10,10],[20,20],[30,30],[0, 0 ]], [[10,10],[20,20],[30,30],[40,40]]] A = Input(shape=[4,2]) # None * 4 * 2 mA = Masking()(A) out = MyMeanPool(axis=1)(mA) model = Model(inputs=[A], outputs=[out]) print model.summary() print model.predict(data)
结果如下,每一行对应一个样本的结果,例如第一个样本只有第一个时刻有值,输出结果是[10. 10. ],是正确的。
[[10. 10.] [15. 15.] [20. 20.] [25. 25.]]
在DeepFM中,每个样本都是由ID构成的,多值field往往会导致样本长度不一的情况,例如interest这样的field,同一个样本可能在该field中有多项取值,毕竟每个人的兴趣点不止一项。
采取padding的方法将每个field的特征补长到最长的长度,则数据尺寸是 [batch_size, max_timestep],经过Embedding为每个样本的每个特征ID配一个latent vector,数据尺寸将变为 [batch_size, max_timestep,latent_dim]。
我们希望每一个field的Embedding之后的尺寸为[batch_size, latent_dim],然后进行concat操作横向拼接,所以这里就可以使用自定义的MeanPool层了。希望能给大家一个参考,也希望大家多多支持易盾网络。